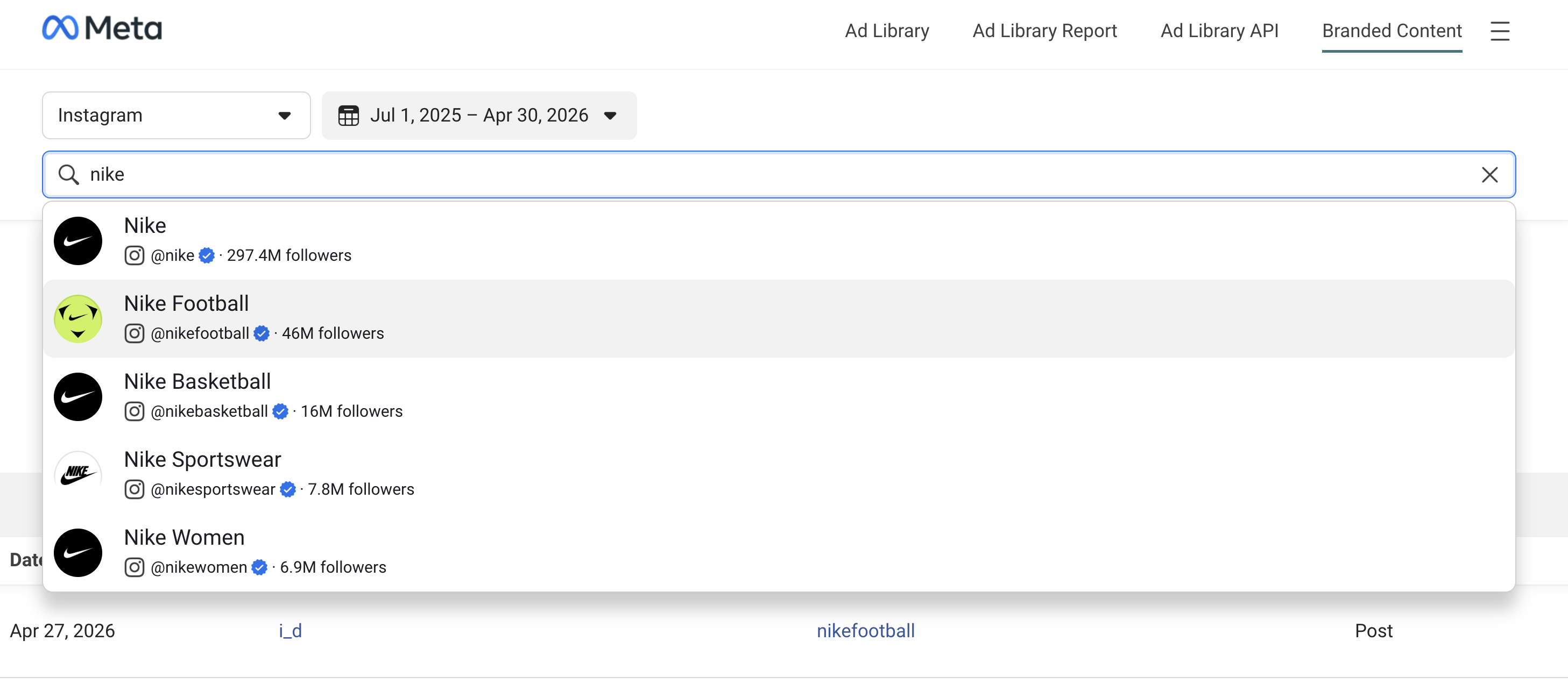
| 🏢 Brand collaboration company | 🧑🎨 Creator name and profile URL |
| 🎬 Content type: post/reel/story | 📱 Platform (Instagram/Facebook) |
| 🔗 Reel URL, Post URL, or Story URL | 📅 Date released |
| 🆔 Content ID |
Once the URL was copied, paste it into Actor's input and choose the number of results per URL. You can also configure date filters to fetch the collabs only from the time range you're interested in.
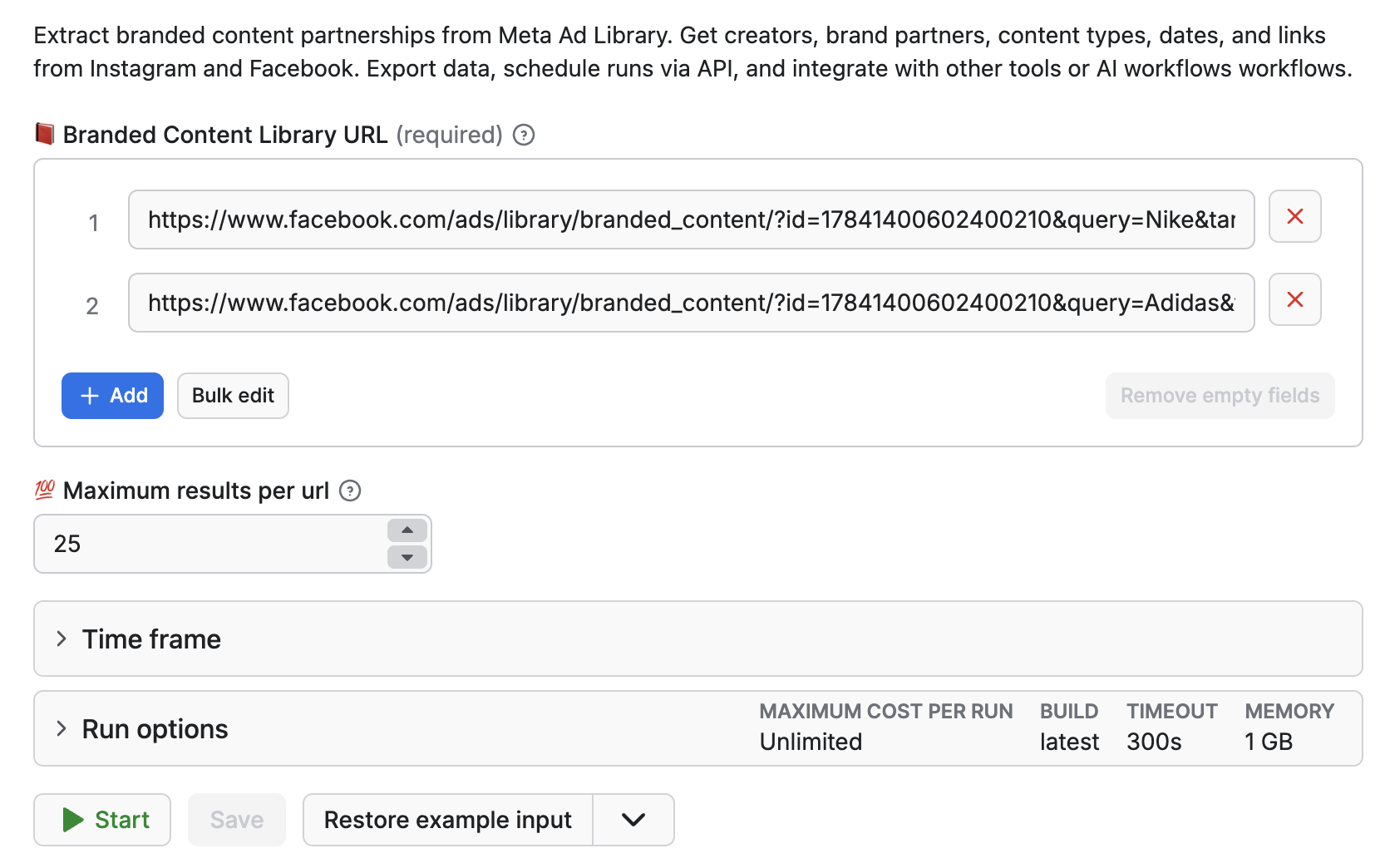 Click on the [input tab](https://apify.com/apify/brand-collaboration-scraper/input-schema) for a full explanation of an input example in JSON.
### ⬆️ Output
The results will be wrapped into a dataset, which you can find in the **Output** tab.
Click on the [input tab](https://apify.com/apify/brand-collaboration-scraper/input-schema) for a full explanation of an input example in JSON.
### ⬆️ Output
The results will be wrapped into a dataset, which you can find in the **Output** tab.
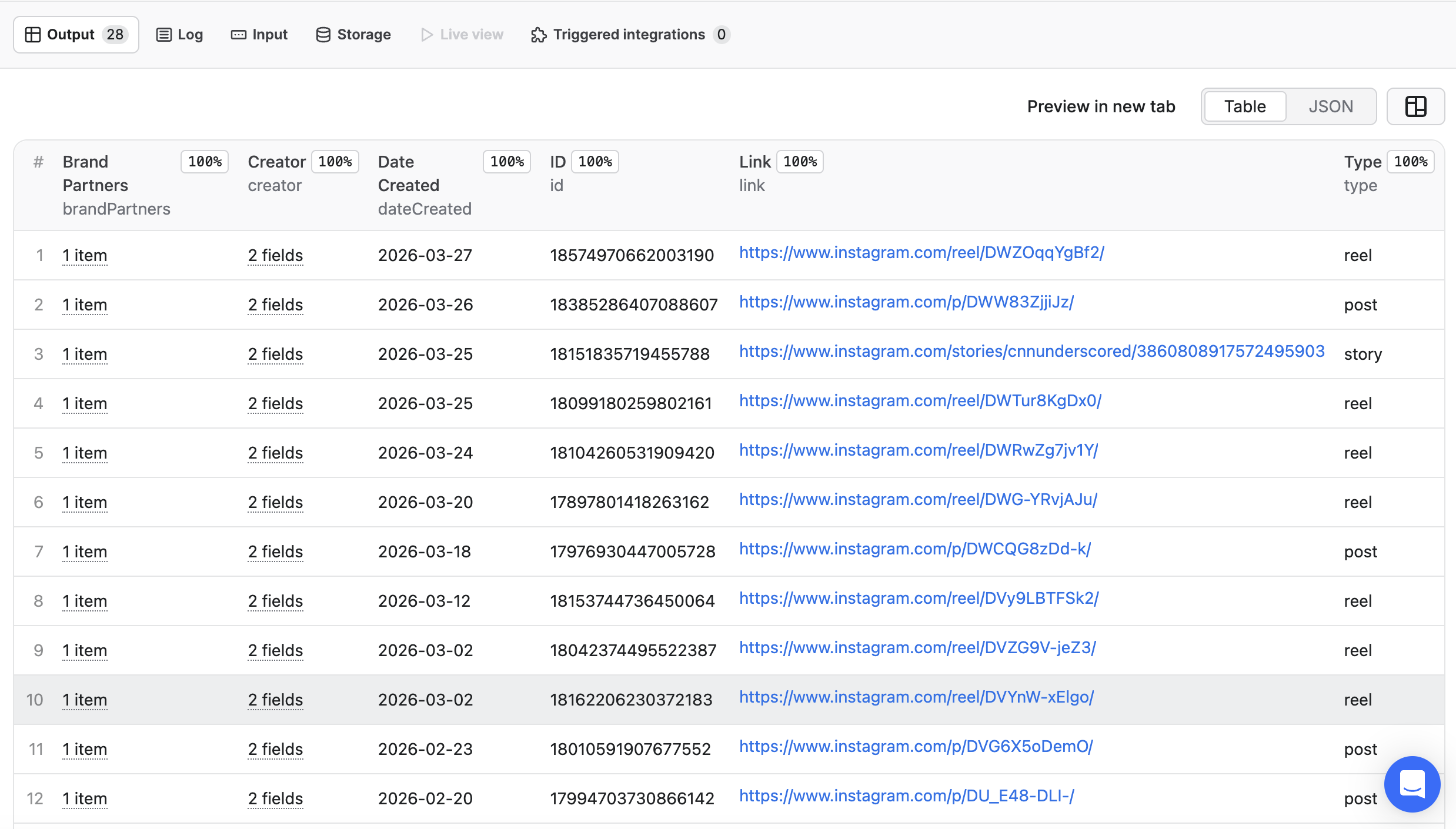 #### 🤝 **Extracted Instagram brand-influencer collaboration sample**
You can choose in which format to download your data: JSON, JSONL, Excel spreadsheet, HTML table, CSV, or XML. Here's what a typical output looks like:
```json
[
{
"id": "18574970662003190",
"dateCreated": "2026-03-27",
"creator": {
"name": "oemerpa",
"link": "https://www.instagram.com/_u/oemerpa"
},
"brandPartners": [
{
"name": "nike",
"link": "https://www.instagram.com/_u/nike"
}
],
"type": "reel",
"link": "https://www.instagram.com/reel/DWZOqqYgBf2/"
},
{
"id": "18385286407088607",
"dateCreated": "2026-03-26",
"creator": {
"name": "cfabastin",
"link": "https://www.instagram.com/_u/cfabastin"
},
"brandPartners": [
{
"name": "nike",
"link": "https://www.instagram.com/_u/nike"
}
],
"type": "post",
"link": "https://www.instagram.com/p/DWW83ZjjiJz/"
},
{
"id": "18151835719455788",
"dateCreated": "2026-03-25",
"creator": {
"name": "cnnunderscored",
"link": "https://www.instagram.com/_u/cnnunderscored"
},
"brandPartners": [
{
"name": "nike",
"link": "https://www.instagram.com/_u/nike"
}
],
"type": "story",
"link": "https://www.instagram.com/stories/cnnunderscored/3860808917572495903"
},
{
"id": "18099180259802161",
"dateCreated": "2026-03-25",
"creator": {
"name": "tatticassiano",
"link": "https://www.instagram.com/_u/tatticassiano"
},
"brandPartners": [
{
"name": "nike",
"link": "https://www.instagram.com/_u/nike"
}
],
"type": "reel",
"link": "https://www.instagram.com/reel/DWTur8KgDx0/"
},
{
"id": "18104260531909420",
"dateCreated": "2026-03-24",
"creator": {
"name": "cfabastin",
"link": "https://www.instagram.com/_u/cfabastin"
},
"brandPartners": [
{
"name": "nike",
"link": "https://www.instagram.com/_u/nike"
}
],
"type": "reel",
"link": "https://www.instagram.com/reel/DWRwZg7jv1Y/"
},
{
"id": "17897801418263162",
"dateCreated": "2026-03-20",
"creator": {
"name": "oemerpa",
"link": "https://www.instagram.com/_u/oemerpa"
},
"brandPartners": [
{
"name": "nike",
"link": "https://www.instagram.com/_u/nike"
}
],
"type": "reel",
"link": "https://www.instagram.com/reel/DWG-YRvjAJu/"
},
{
"id": "17976930447005728",
"dateCreated": "2026-03-18",
"creator": {
"name": "peterfagnoni",
"link": "https://www.instagram.com/_u/peterfagnoni"
},
"brandPartners": [
{
"name": "nike",
"link": "https://www.instagram.com/_u/nike"
}
],
"type": "post",
"link": "https://www.instagram.com/p/DWCQG8zDd-k/"
},
{
"id": "18153744736450064",
"dateCreated": "2026-03-12",
"creator": {
"name": "tatticassiano",
"link": "https://www.instagram.com/_u/tatticassiano"
},
"brandPartners": [
{
"name": "nike",
"link": "https://www.instagram.com/_u/nike"
}
],
"type": "reel",
"link": "https://www.instagram.com/reel/DVy9LBTFSk2/"
},
{
"id": "18042374495522387",
"dateCreated": "2026-03-02",
"creator": {
"name": "peterfagnoni",
"link": "https://www.instagram.com/_u/peterfagnoni"
},
"brandPartners": [
{
"name": "nike",
"link": "https://www.instagram.com/_u/nike"
}
],
"type": "reel",
"link": "https://www.instagram.com/reel/DVZG9V-jeZ3/"
},
{
"id": "18162206230372183",
"dateCreated": "2026-03-02",
"creator": {
"name": "rashwin99",
"link": "https://www.instagram.com/_u/rashwin99"
},
"brandPartners": [
{
"name": "nike",
"link": "https://www.instagram.com/_u/nike"
}
],
"type": "reel",
"link": "https://www.instagram.com/reel/DVYnW-xElgo/"
}
]
````
### Want to get other data from Instagram?
You can use any of the dedicated scrapers below if you want to scrape specific Instagram data. Each of them is built for a specific Instagram scraping use case. Feel free to browse them:
#### 🤝 **Extracted Instagram brand-influencer collaboration sample**
You can choose in which format to download your data: JSON, JSONL, Excel spreadsheet, HTML table, CSV, or XML. Here's what a typical output looks like:
```json
[
{
"id": "18574970662003190",
"dateCreated": "2026-03-27",
"creator": {
"name": "oemerpa",
"link": "https://www.instagram.com/_u/oemerpa"
},
"brandPartners": [
{
"name": "nike",
"link": "https://www.instagram.com/_u/nike"
}
],
"type": "reel",
"link": "https://www.instagram.com/reel/DWZOqqYgBf2/"
},
{
"id": "18385286407088607",
"dateCreated": "2026-03-26",
"creator": {
"name": "cfabastin",
"link": "https://www.instagram.com/_u/cfabastin"
},
"brandPartners": [
{
"name": "nike",
"link": "https://www.instagram.com/_u/nike"
}
],
"type": "post",
"link": "https://www.instagram.com/p/DWW83ZjjiJz/"
},
{
"id": "18151835719455788",
"dateCreated": "2026-03-25",
"creator": {
"name": "cnnunderscored",
"link": "https://www.instagram.com/_u/cnnunderscored"
},
"brandPartners": [
{
"name": "nike",
"link": "https://www.instagram.com/_u/nike"
}
],
"type": "story",
"link": "https://www.instagram.com/stories/cnnunderscored/3860808917572495903"
},
{
"id": "18099180259802161",
"dateCreated": "2026-03-25",
"creator": {
"name": "tatticassiano",
"link": "https://www.instagram.com/_u/tatticassiano"
},
"brandPartners": [
{
"name": "nike",
"link": "https://www.instagram.com/_u/nike"
}
],
"type": "reel",
"link": "https://www.instagram.com/reel/DWTur8KgDx0/"
},
{
"id": "18104260531909420",
"dateCreated": "2026-03-24",
"creator": {
"name": "cfabastin",
"link": "https://www.instagram.com/_u/cfabastin"
},
"brandPartners": [
{
"name": "nike",
"link": "https://www.instagram.com/_u/nike"
}
],
"type": "reel",
"link": "https://www.instagram.com/reel/DWRwZg7jv1Y/"
},
{
"id": "17897801418263162",
"dateCreated": "2026-03-20",
"creator": {
"name": "oemerpa",
"link": "https://www.instagram.com/_u/oemerpa"
},
"brandPartners": [
{
"name": "nike",
"link": "https://www.instagram.com/_u/nike"
}
],
"type": "reel",
"link": "https://www.instagram.com/reel/DWG-YRvjAJu/"
},
{
"id": "17976930447005728",
"dateCreated": "2026-03-18",
"creator": {
"name": "peterfagnoni",
"link": "https://www.instagram.com/_u/peterfagnoni"
},
"brandPartners": [
{
"name": "nike",
"link": "https://www.instagram.com/_u/nike"
}
],
"type": "post",
"link": "https://www.instagram.com/p/DWCQG8zDd-k/"
},
{
"id": "18153744736450064",
"dateCreated": "2026-03-12",
"creator": {
"name": "tatticassiano",
"link": "https://www.instagram.com/_u/tatticassiano"
},
"brandPartners": [
{
"name": "nike",
"link": "https://www.instagram.com/_u/nike"
}
],
"type": "reel",
"link": "https://www.instagram.com/reel/DVy9LBTFSk2/"
},
{
"id": "18042374495522387",
"dateCreated": "2026-03-02",
"creator": {
"name": "peterfagnoni",
"link": "https://www.instagram.com/_u/peterfagnoni"
},
"brandPartners": [
{
"name": "nike",
"link": "https://www.instagram.com/_u/nike"
}
],
"type": "reel",
"link": "https://www.instagram.com/reel/DVZG9V-jeZ3/"
},
{
"id": "18162206230372183",
"dateCreated": "2026-03-02",
"creator": {
"name": "rashwin99",
"link": "https://www.instagram.com/_u/rashwin99"
},
"brandPartners": [
{
"name": "nike",
"link": "https://www.instagram.com/_u/nike"
}
],
"type": "reel",
"link": "https://www.instagram.com/reel/DVYnW-xElgo/"
}
]
````
### Want to get other data from Instagram?
You can use any of the dedicated scrapers below if you want to scrape specific Instagram data. Each of them is built for a specific Instagram scraping use case. Feel free to browse them: