Metadata Extractor
Pricing
Pay per usage
Go to Apify Store

Metadata Extractor
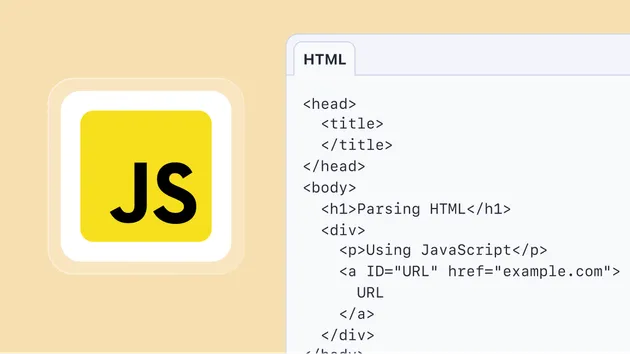
A small efficient actor that loads a web page, parses its HTML using Cheerio library and extracts the following meta-data from the <HEAD> tag, such as page title, description, author etc.
Pricing
Pay per usage
Rating
0.0
(0)
Developer
Jan Čurn
Maintained by CommunityActor stats
19
Bookmarked
1.4K
Total users
14
Monthly active users
3 years ago
Last modified
Categories
Share