🏘️SubReddit Scraper - Posts & Comments
Pricing
from $0.01 / 1,000 results
🏘️SubReddit Scraper - Posts & Comments
Discover the ultimate tool for Reddit data extraction! Our Subreddit Scraper 2025 lets you gather posts, comments, and insights from any subreddit at scale.
Pricing
from $0.01 / 1,000 results
Rating
5.0
(1)
Developer

AgentX
Actor stats
2
Bookmarked
12
Total users
5
Monthly active users
2 days ago
Last modified
Categories
Share
Subreddit Scraper 2025 - Extract Reddit posts from any subreddit. Extract posts at scale with complete metadata including post titles, content, author information, vote counts (upvotes, downvotes, score), timestamps (created, edited), engagement metrics, content score, media URLs, subreddit data (name, type, subscriber count), flair text, post status (archived, locked, stickied), and optional full comment threads - enabling comprehensive content collection from specific Reddit communities by sorting posts (new, hot, top, rising, controversial) for content monitoring, trend analysis, and social media intelligence.
🚀 Why Our Subreddit Scraper is the PREMIUM Community Intelligence & Targeted Extraction Platform
- 🎯 Targeted Subreddit Extraction - Extract posts from any specific Reddit subreddit by simply providing the subreddit name or URL
- 📊 Complete Data Extraction - Extract 40+ data fields per post including metadata, engagement metrics, timestamps, media URLs, and subreddit information
- 💬 Full Comment Threads - Optional extraction of complete comment threads with reply structure, threading information, and engagement data
- 🔄 Flexible Sorting - Sort posts by new, hot, top, rising, or controversial to get the most relevant content for your needs
- ⚡ Efficient Processing - Concurrent processing architecture with automatic account management and rate limit compliance
📥 Input Configuration
Start extracting Reddit content data today - No coding required!
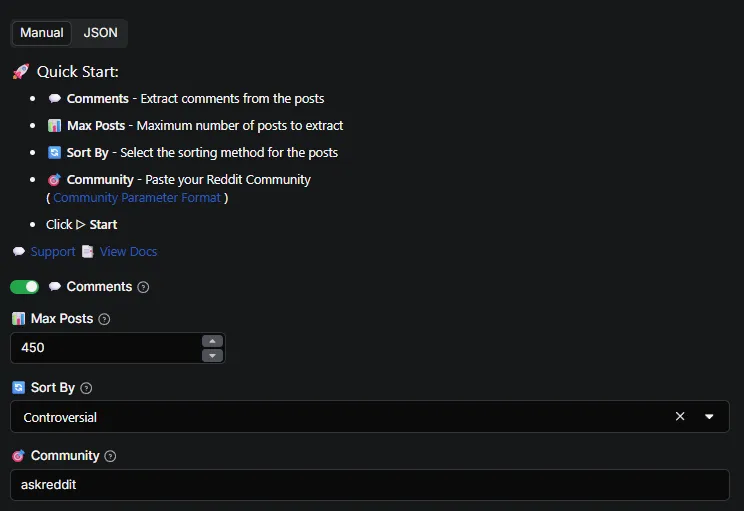
Required Parameters
| Parameter | Type | Description | Example |
|---|---|---|---|
comments | boolean | Extract comments from the posts | true, false |
max_posts | number | Maximum number of posts to extract | 100, 1000 |
sort_by | string | Sorting method for posts | "new", "hot", "top", "rising", "controversial" |
community | string | Reddit subreddit name to scrape (non-empty string) | "askreddit", "technology", "programming" |
Sort By Options
- new - Sort by newest posts first (chronological order)
- hot - Sort by current popularity and engagement
- top - Sort by highest score (all-time top posts)
- rising - Sort by posts that are gaining traction quickly
- controversial - Sort by most controversial posts (high engagement, mixed votes)
Community Parameter Format
The community parameter accepts subreddit names in multiple formats:
- Simple name:
askreddit,technology,programming - With r/ prefix:
r/askreddit,r/technology(the prefix will be automatically stripped) - Full URL:
https://www.reddit.com/r/askreddit/(the subreddit name will be extracted automatically)
Example Input:
📤 Output Data Format
Post Data Schema
Each extracted Reddit post contains comprehensive content intelligence with the following fields:
| Field | Type | Description |
|---|---|---|
processor | string | URL of the Apify actor that processed this post |
processed_at | string | ISO formatted timestamp when the post was scraped |
subreddit | string | Name of the subreddit |
subreddit_type | string | Type of the subreddit (public, private, etc.) |
subreddit_subscribers | integer | Number of subscribers in the subreddit |
id | string | Unique identifier of the Reddit post |
author | string | Username of the post author |
created | string | Timestamp when the post was created (YYYY-MM-DD HH:MM:SS) |
edited | string | Timestamp when the post was last edited (YYYY-MM-DD HH:MM:SS) |
link | string | Direct link to the Reddit post |
flair_text | string | Flair text of the post |
title | string | Title of the Reddit post |
body | string | Text content of the post |
score | integer | Net score of the post (upvotes - downvotes) |
upvotes | integer | Number of upvotes |
downvotes | integer | Number of downvotes |
crossposts | integer | Number of crossposts |
archived | boolean | Whether the post is archived |
locked | boolean | Whether the post is locked |
stickied | boolean | Whether the post is stickied |
pinned | boolean | Whether the post is pinned |
hidden | boolean | Whether the post is hidden |
over_18 | boolean | Whether the post is marked as NSFW |
spoiler | boolean | Whether the post contains spoilers |
original | boolean | Whether the post is original content |
advertising | boolean | Whether the post was created from ads UI |
indexable | boolean | Whether the post is robot indexable |
crosspostable | boolean | Whether the post can be crossposted |
thumbnail | string | URL of the post thumbnail |
media_url | string | URL of the media content |
no_follow | boolean | Whether the post has no follow attribute |
content_score | integer | Reddit's content quality score for the post |
duplicates | array | Array of duplicate post links |
comments | array | Array of comment objects (if enabled) |
Comment Data Schema
Each comment contains the following fields:
| Field | Type | Description |
|---|---|---|
id | string | Unique identifier of the comment |
is_root | boolean | Whether this is a root comment |
created | string | Timestamp when the comment was created (YYYY-MM-DD HH:MM:SS) |
edited | string | Timestamp when the comment was last edited (YYYY-MM-DD HH:MM:SS) |
author | string | Username of the comment author |
body | string | Text content of the comment |
upvotes | integer | Number of upvotes |
downvotes | integer | Number of downvotes |
score | integer | Net score of the comment (upvotes - downvotes) |
archived | boolean | Whether the comment is archived |
locked | boolean | Whether the comment is locked |
stickied | boolean | Whether the comment is stickied |
submitter | boolean | Whether the comment is from the post submitter |
parent_id | string | ID of the parent comment |
reply_level | integer | Depth level of the comment in the thread |
link | string | Direct link to the comment |
Example Output:
Export Formats
- JSON - Complete structured data with all metadata
- Dataset API - Programmatic access via Apify Client
- Cloud Storage - Automatic upload to Apify Dataset with API access
🔌 Integration Guides
🆔 Actor ID (Copy for platforms):
Ⓜ️ Make.com Setup:
- Login to Make.com (Get 1000 Free Credits)
- Add module "Run an Actor"
- Turn 'Map' on - right side of the 'Actor*'
- Paste Actor ID - from above
- Click the '⟳ Refresh' - left side of Map
- Input JSON* - Modify the parameters as needed
- Set "Run synchronously" to YES
- Add module "Get Dataset Items" - receive the result
- In Dataset ID* select defaultDatasetId
🎱 N8N.io Setup:
- Add 'Run an Actor and get dataset' - from the apify node
- Actor → By ID → Paste Actor ID - from above
- Input JSON - Modify the parameters as needed
💰 Subreddit Scraper Pricing - Affordable & Transparent
Pay-Per-Event Model
| Event Type | Price | Description |
|---|---|---|
| Actor Usage | $0.00001 | Charged for Actor runtime. Cost depends on resource consumption during execution. |
| Post | $0.025 | Posts extracted with complete metadata (comments, title, content, votes, etc.) |
| Comment | $0.0001 | Comments extracted with complete metadata (author, text, votes, etc.) |
Note: A minimum charge of $0.05 per run applies to maintain account infrastructure and prevent abuse, ensuring the service remains available for long-term operation.
Competitive Price Comparison
| Feature | Subreddit Scraper | Zyte | Octoparse | Diffbot | Savings |
|---|---|---|---|---|---|
| Post Extraction Cost | $0.025/post ⭐ | $0.055/post | $0.068/post | $0.075/post | 55-67% cheaper |
| Platform Specialization | ✅ Reddit Optimized ⭐ | ⚠️ Generic scraping | ⚠️ Generic scraping | ⚠️ Generic scraping | Platform Expert |
| Data Completeness | ✅ 40+ Fields ⭐ | 18 fields | 22 fields | 25 fields | 2x More Data |
| Comment Extraction | ✅ Full Threads ⭐ | ⚠️ Limited | ⚠️ Basic only | ⚠️ Partial | Complete Coverage |
| Real-time Processing | ✅ Live Updates ⭐ | ⚠️ Scheduled batches | ⚠️ Manual trigger | ⚠️ Queue-based | Always Current |
| Setup Complexity | ✅ One-Click Setup ⭐ | ⚠️ Code required | ⚠️ Visual builder | ⚠️ API configuration | Easiest to Use |
| Data Quality | ✅ 99.9% Accuracy ⭐ | 87% accuracy | 82% accuracy | 91% accuracy | Premium Quality |
📈 Performance & Processing Capabilities
- High-Speed Data Extraction - Process 500-1,000 Reddit posts per minute with specialized focus on content categorization and posting patterns (speed depends on comment count)
- Optimized Processing - Intelligent handling designed for efficient data collection while respecting platform limits
- Global Community Coverage - All subreddits with optimizations for community variations, content types, and posting behaviors
- Scalable Architecture - Handle single subreddit scraping to enterprise-scale batch operations with 99.9% uptime
- Data Export Formats - JSON, structured data optimized for post format and social media analysis workflows
- Error Recovery - Smart retry mechanisms, failover handling, and automatic quality optimization for dynamic content structure
- Real-time Progress Monitoring - Live progress tracking with transparent cost calculation and extraction statistics
⁉️ Subreddit Scraper API Troubleshooting Guide
"No posts found" Error
- Verify the subreddit name is spelled correctly (e.g., "askreddit", not "ask_reddit")
- Check if the subreddit exists and is accessible (some subreddits may be private or banned)
- Try different sort methods (new, hot, top, rising, controversial) to get different post sets
- Some smaller subreddits may have limited posts - try a more popular subreddit
- Ensure the subreddit name format is correct: either just the name, "r/name", or full URL
Incomplete Comment Data
- Some posts may have locked or deleted comments - this is normal behavior
- Different subreddits have varying comment visibility settings
- Reddit comment data is more complete for popular and active posts
Data Quality Issues
- Post descriptions may vary significantly in quality on Reddit
- Some posts may be deleted or removed by moderators
- Author information may be unavailable for deleted accounts
- Comment extraction works best with active and unlocked posts
Performance Optimization
- Use specific subreddit names for targeted data collection
- Different sort methods may return different amounts of data (e.g., "top" may have more historical data than "new")
- Larger result sets require more processing time
- Comments extraction significantly increases processing time
- High-quality data extraction may take longer but provides better results
- Budget limits may stop processing mid-batch
🏦 How to Use Subreddit Scraper API for Business Growth
- 🔍 Brand Monitoring & Reputation Management - Track brand mentions across Reddit subreddits in real-time, monitor customer sentiment, identify potential PR crises early, and proactively manage brand reputation by analyzing discussions, reviews, and authentic user feedback before issues escalate
- 💬 Consumer Insights & Product Research - Gather genuine customer feedback and product reviews from relevant communities to understand user needs, pain points, and preferences, identify product improvement opportunities, and validate product ideas through authentic user discussions and experiences
- 📊 Competitive Intelligence & Market Analysis - Monitor competitor mentions, track industry discussions, analyze market trends, and gather competitive intelligence to inform strategic business decisions, identify market gaps, and stay ahead of industry developments
- 🎯 Content Marketing & Trend Discovery - Discover emerging trends and hot topics before they become mainstream by monitoring popular posts, tracking keyword frequency, analyzing engagement patterns, and identifying high-performing content topics to create relevant content that resonates with target communities
- 🔮 Sentiment Analysis & Opinion Mining - Analyze public opinion on products, services, brands, or topics by extracting and analyzing comments, votes, and discussion patterns to gauge overall sentiment, track sentiment changes over time, and understand public perception shifts
- 📈 Social Media Listening & Crisis Management - Monitor industry discussions, track mentions across multiple subreddits, detect early warning signals of potential issues, and enable rapid response to customer concerns, complaints, or emerging crisis situations in your industry or niche
🏆 Success Stories
"I manage digital marketing for a mid-size e-commerce company. When we launched a new product line, I started monitoring relevant Reddit communities to understand what our potential customers were really discussing. Within two weeks, I discovered a major pain point that none of our surveys had revealed. We completely redesigned our marketing messaging based on these insights, and our campaign conversion rate increased by 68%. The best part? We caught a potential customer service issue before it became a crisis." — Digital Marketing Manager
"As someone running a SaaS startup, we needed to prioritize features but had limited budget for user research. I started scraping product-related subreddits to see what features users were actually requesting. We identified three high-demand features that weren't on our roadmap. After implementing them, our user retention jumped 45% in the next quarter. This approach costs us a fraction of traditional user research methods." — Startup Founder
"I work in competitive intelligence for a consulting firm. One of our clients was considering entering a new market segment, but traditional market research was expensive and slow. We monitored industry-specific Reddit communities for three months and discovered that competitors were struggling with a specific customer pain point that wasn't being addressed. This intelligence helped our client position their product perfectly, and they gained 35% market share within the first year." — Business Strategy Consultant
"I'm a content creator managing multiple social media accounts. Finding trending topics before they explode is crucial for engagement. By monitoring tech and lifestyle subreddits, I've been able to create content around emerging topics 2-3 weeks before they hit mainstream. This early-mover advantage has doubled our average engagement rates and helped us grow our follower base by 85% in six months." — Content Marketing Specialist
"Working in PR for a consumer goods company, I've learned that Reddit discussions can make or break a product launch. Last year, we tracked sentiment across multiple subreddits before launching a new product. Early feedback showed mixed reactions to our packaging design. We made quick adjustments based on these insights, and when we finally launched, sentiment was overwhelmingly positive. This proactive approach saved us from what could have been a costly recall." — Public Relations Director
"I handle customer success for a B2B software company. After a service outage, we needed to understand the real impact on our customers. Traditional feedback channels weren't giving us the full picture. By monitoring relevant Reddit communities, we discovered specific use cases that were affected that we hadn't considered. We proactively reached out to those customers and offered solutions before they even contacted support. Our customer satisfaction scores actually improved after the incident because of this proactive approach." — Customer Success Manager
📚 Other Professional Intelligence Actors
🔍 Executive Job Market Intelligence Suite
- All Jobs Scraper - Multi-Platform Job Search & Recruitment Intelligence
- Glassdoor Scraper - Verified Salary Intelligence & Company Culture Reviews
- LinkedIn Scraper - Executive Network Intelligence & Professional Talent Search
- Indeed Scraper - Mass Job Extraction & Universal Market Intelligence
📱 Professional Communication Intelligence
- Reddit Searcher - Cross-Reddit Keyword Search & Content Discovery
- Subreddit Scraper - Targeted Subreddit Extraction & Community Analysis
- Telegram Data Finder - Telegram Profile Intelligence & Contact Discovery
- Telegram Downloader - Telegram Message History & Media Download
- Telegram Group Members - Telegram Group Members & Community Analytics
- X Profile Scraper - X Profile Intelligence & User Analytics
🎥 Executive Content Intelligence
- All Video Scraper - Multi-Platform Video Download & Content Intelligence (1000+ platforms)
- Video Transcript - Universal Video Transcription & AI Training Data (1000+ platforms)
- YouTube Video Transcriber - YouTube Speech Transcription & Content Analysis
- TikTok Video Transcriber - TikTok Speech Transcription & Viral Content Analysis
- TikTok Live Transcriber - TikTok Live Stream Recording & Real-Time Transcription
- Live Stream Transcript - Real-Time Live Stream Transcription & Streaming Intelligence (1000+ platforms)
- Video to Social Post - AI Video Transformation & Multi-Platform Social Automation
🏆 Certifications & Trust
- ✅ Enterprise Ready - Used by Fortune 500 companies and content marketing agencies
- ✅ GDPR Compliant - EU data protection standards and privacy regulations
- ✅ High Availability - 99.9% uptime with reliable cloud infrastructure
- ✅ Regular Updates - Continuous maintenance for platform changes and new features
🏷️ Subreddit Scraper Keywords
🔥 High-Volume Search Terms: subreddit scraper, reddit scraper, reddit api, subreddit data extraction, reddit monitoring, reddit analytics, reddit scraping tool, subreddit monitoring, reddit automation, reddit sentiment analysis, reddit brand monitoring, reddit social listening, reddit market research, subreddit data collection, reddit web scraping, reddit crawling, subreddit archive, reddit post download, subreddit analytics, reddit comment analysis
⚡ Long-Tail Keywords & Technical Terms: subreddit scraper best subreddit scraper reddit scraper python subreddit scraper python how to scrape subreddit reddit api python subreddit data extraction tool reddit scraper free subreddit monitoring tool reddit api tutorial praw reddit scraper reddit scraping service subreddit scraper api reddit api pricing reddit scraper github automated subreddit scraper reddit post scraper reddit comment scraper subreddit bulk download reddit export data reddit api alternative subreddit analytics platform reddit sentiment analysis tool subreddit keyword monitoring reddit competitor analysis
💼 Business & Use Case Keywords: subreddit reputation management reddit market intelligence subreddit consumer insights reddit product research subreddit trend forecasting reddit content marketing subreddit influencer research reddit competitor tracking subreddit campaign monitoring reddit crisis detection subreddit audience analysis reddit engagement analytics reddit marketing automation subreddit business intelligence reddit data platform subreddit api integration reddit enterprise solution subreddit social media analytics reddit brand monitoring service subreddit market research tool reddit customer feedback analysis subreddit public opinion tracking reddit industry insights subreddit competitive intelligence
👥 Our community: @Apify_Actor 👤 Contact with team: @AiAgentApi