Python Crawlee Page Profiler
Pricing
Pay per event
Python Crawlee Page Profiler
Pilot Python/Crawlee actor that profiles HTML documents and extracts page metadata, headings, links, and text statistics from supplied URLs.
Pricing
Pay per event
Rating
0.0
(0)
Developer
Stas Persiianenko
Maintained by CommunityActor stats
0
Bookmarked
2
Total users
1
Monthly active users
a month ago
Last modified
Categories
Share
Profile HTML documents with a bounded Python/Crawlee pilot actor.
Overview
Python Crawlee Page Profiler visits supplied URLs, downloads each HTML document with Crawlee for Python, parses it with BeautifulSoup, and writes one dataset item per page.
It extracts titles, meta descriptions, heading counts, link counts, approximate word counts, text samples, and optional sampled links.
This actor is intentionally small and non-critical. Its purpose is to validate whether Python/Crawlee should become a selective internal template for future Apify actors.
Why this pilot exists
Our standard actor factory is TypeScript-based.
Python can be useful for document processing, file analysis, NLP-lite, PDF tooling, and library-heavy utilities.
Before adopting Python more broadly, we need one bounded pilot with normal Apify schemas, Dockerfile, dependencies, README, pricing events, and smoke-test instructions.
Who is it for?
This actor is for developers, QA teams, content operators, and internal automation builders who need lightweight HTML page profiles.
It is also for maintainers evaluating whether Python/Crawlee can support selective Apify actor templates.
What this actor is good for
Use it when you need a quick profile of server-rendered HTML pages.
Typical jobs include:
- checking whether pages have titles and meta descriptions
- counting H1 and H2 headings
- estimating visible text length
- sampling links from documentation or content pages
- comparing small groups of public landing pages
- validating Python actor packaging on Apify
What this actor is not
This is not a full SEO crawler.
It does not render JavaScript.
It does not bypass anti-bot protection.
It does not deep-crawl discovered links.
It is a Python/Crawlee template validation pilot, not a premium production scraper.
Input
Provide a list of URLs in startUrls.
Set maxPages to cap how many supplied URLs are processed.
Set includeLinks to include or omit sampled normalized links.
The actor accepts both Apify request-list source objects and plain URL strings.
Input fields
| Field | Type | Default | Description |
|---|---|---|---|
startUrls | array | required | HTML document URLs to profile. |
maxPages | integer | 5 | Maximum number of supplied URLs to process, capped at 100. |
includeLinks | boolean | true | Include up to 25 normalized links from each page. |
Example input
Output
Each dataset item represents one profiled page.
Fields include the final loaded URL, basic HTML metadata, heading counts, link counts, text statistics, sampled links, and the profiler identifier.
Output fields
| Field | Type | Description |
|---|---|---|
url | string | Final loaded URL profiled by Crawlee. |
title | string | Text content of the <title> element. |
metaDescription | string | Content of the meta description tag, when present. |
statusCode | number/null | HTTP response status code, when available. |
h1Count | number | Number of H1 headings. |
h2Count | number | Number of H2 headings. |
linkCount | number | Number of usable anchors found. |
wordCount | number | Approximate visible text word count. |
textSample | string | First 500 characters of normalized page text. |
links | array | Up to 25 normalized sampled links. |
profiler | string | Implementation identifier. |
Example output
Pricing and cost
This pilot uses pay-per-event pricing.
| Event | When it is charged | Current BRONZE price |
|---|---|---|
start | Once when the run starts | $0.005 |
page-profiled | Once per successfully profiled page | $0.00021819 |
The values are deliberately low because this is a lightweight HTTP utility with no browser and no residential proxy requirement.
Free-plan estimate: a two-page test run costs about $0.0054 before platform tier differences.
Larger 100-page validation runs are still expected to be low-cost because the actor only downloads HTML and parses it in memory.
Cost expectations
The actor does not use a browser.
It does not use residential proxies by default.
Expected memory is 512 MB.
Small runs should complete quickly and produce one item per supplied URL.
Real-world cost depends on target page size and network latency.
Local smoke run
Install dependencies in a virtual environment:
Run syntax validation:
Run the actor locally with Apify CLI:
A sample input is committed at storage/key_value_stores/default/INPUT.json.
Docker image
The Dockerfile uses the official Apify Python base image:
Dependencies are pinned in requirements.txt.
This keeps the pilot reproducible and avoids floating Python/Crawlee versions.
Python and Crawlee details
The actor uses:
apify==3.4.0crawlee[beautifulsoup]==1.7.1beautifulsoup4==4.13.4lxml==5.4.0
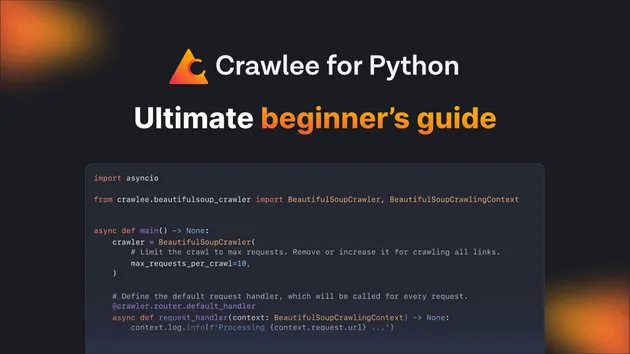
The crawler class is BeautifulSoupCrawler.
The handler receives a BeautifulSoupCrawlingContext and reads context.soup.
How it works
The actor normalizes input URLs.
It charges the start event.
It creates a bounded BeautifulSoup crawler with max_requests_per_crawl set from maxPages.
For each fetched HTML page, it extracts metadata and pushes one dataset item.
It then charges page-profiled for that successful item.
JavaScript rendering
The actor does not render JavaScript.
Use it for pages where relevant data exists in the initial HTML response.
If a page is a JavaScript shell, the title and text fields may be sparse.
Link sampling
When includeLinks is enabled, the actor stores up to 25 normalized links per page.
It skips empty links and javascript:, mailto:, and tel: URLs.
The linkCount field counts all usable links, not just the sampled subset.
Integrations and workflows
You can use the dataset in:
- content inventory workflows
- lightweight documentation audits
- HTML migration checks
- QA smoke tests for public pages
- Python actor template validation runs
- dashboards that compare titles, headings, and text sizes
The actor pairs well with downstream data tools that consume Apify datasets as JSON, CSV, or via API.
API usage
You can run the actor from Apify Console, the Apify API, Apify client libraries, cURL, or MCP.
The examples below use the public actor identifier automation-lab/python-crawlee-page-profiler.
Node.js API example
Python API example
cURL example
MCP usage
Apify MCP can expose this actor as a tool to compatible clients.
Use the current hosted MCP endpoint pattern:
Add it from a CLI-based client with:
Or use a JSON config block:
Example prompts after connecting MCP:
- "Profile the Crawlee Python docs and summarize the title, heading counts, and sampled links."
- "Run Python Crawlee Page Profiler on these two documentation URLs with maxPages set to 2."
- "Compare word counts and meta descriptions for two public HTML pages."
MCP client configuration
For Claude Desktop or Claude Code style clients, add the hosted Apify MCP endpoint with this pattern:
If your MCP client accepts JSON server configuration, add:
Data quality notes
The actor reports counts from parsed HTML.
Word counts are approximate and based on BeautifulSoup text extraction.
Links are normalized with the page URL as base.
Only the first 25 links are included when includeLinks is enabled.
Sites may serve different HTML to different geographies or user agents.
Limits
The input schema caps maxPages at 100.
This keeps the pilot bounded and makes cost/memory behavior easy to evaluate.
If a future Python template is approved, production actors can choose limits appropriate to their target use case.
Troubleshooting
If the output is empty, check that your input URLs are valid.
If a page needs JavaScript rendering, this HTTP-only pilot will not see rendered content.
If a site blocks datacenter requests, try a simple public URL for the pilot run.
If links is empty, confirm includeLinks is set to true and the page contains anchors with href attributes.
Legality
Only crawl URLs you are allowed to access.
Respect website terms, robots policies, and applicable laws.
This actor is designed for small, transparent metadata profiling.
Related scrapers and actors
Other automation-lab actors that may fit adjacent workflows:
- Substack Scraper for newsletter and post metadata.
- LinkedIn Company Scraper for company profile enrichment.
- YouTube Channel Email Scraper for creator discovery workflows.
This pilot is intentionally narrower: it profiles supplied HTML pages rather than scraping a specific platform.
FAQ
Does this actor render JavaScript?
No. It uses BeautifulSoupCrawler and parses server responses.
Does it follow links?
No. It profiles only supplied URLs in this pilot version.
Can it process PDFs?
No. This pilot profiles HTML documents. Future Python actors may target PDF or file-analysis libraries.
Is this a production Python template?
Not by itself. The pilot recommendation is to promote Python/Crawlee only as a selective template after QA validates build, pricing, memory, schema, and maintainability.
Template recommendation
Recommendation: promote Python/Crawlee only as a selective pilot template, not as the default actor scaffolding.
Python is promising for library-heavy utilities such as document processing, file analysis, NLP-lite extraction, and data validation.
TypeScript should remain the default for broad web scraping until more Python utility actors validate maintenance, pricing, and Store-readiness at normal standards.
Publication status
This actor remains unpublished until normal QA and publisher flow approves it.
The pilot can be evaluated technically without being promoted to the public Store.
Changelog
- 0.1: Initial Python/Crawlee pilot actor.
Internal QA checklist
- Python syntax validation passes.
- Local Apify run produces dataset items.
- Dataset items match
.actor/dataset_schema.json. - Dockerfile uses pinned official Apify Python base image.
dev-precheck.mjscan distinguish Python actors from TypeScript actors.- The actor remains unpublished until normal QA/publisher flow approves it.