🔥 Easy RedNote (XiaoHongShu) Scraper
Pricing
$15.00/month + usage
🔥 Easy RedNote (XiaoHongShu) Scraper
Extract trending posts and user data from RedNote (XiaoHongShu). Automatically scrape posts across categories like 🏠Homefeed, 👗Fashion, 🍜Food, 💄Cosmetics, 🎬Movie & TV, 💼Career, ❤️Love, 🛠️Household, 🎮Gaming, ✈️Travel, and 💪Fitness.
Pricing
$15.00/month + usage
Rating
0.0
(0)
Developer
BuglessLogic
Maintained by CommunityActor stats
6
Bookmarked
95
Total users
0
Monthly active users
a year ago
Last modified
Categories
Share
✨ Features
- 🎯 Smart Targeting: Choose from 11 different content categories
- ⚡ Lightning Fast: Optimized scrolling and data extraction
- 🛡️ Anti-Bot Protection: Advanced mechanisms to avoid detection
- 🤖 Intelligent Scrolling: Dynamic content loading with smart wait times
- 🔄 Smart Recovery: Auto-resumes from failures and handles network issues
🎯 Use Cases
- 📱 Social Media Marketing: Track trending content and influencers
- 🔍 Market Research: Analyze consumer preferences and trends
- 🎨 Content Creation: Get inspiration from top-performing posts
- 👥 Influencer Discovery: Find and analyze popular creators
- 📊 Competitor Analysis: Monitor competitor content and engagement
📋 What Data You Get
| Field | Description |
|---|---|
| post_title | Title of the post |
| post_likes | Number of likes on the post |
| post_url | Direct link to the post |
| author_name | Username of the post creator |
| author_id | Unique identifier of the author |
| author_avatar | URL of author's profile picture |
| author_profile_url | Link to author's profile |
🚀 How do I use RedNote (XiaoHongShu) Scraper to scrape website data?
-
Choose Category: Select any category:
- 🏠 Homefeed
- 👗 Fashion
- 🍜 Food
- 💄 Cosmetics
- 🎬 Movie & TV
- 💼 Career
- ❤️ Love
- 🛠️ Household
- 🎮 Gaming
- ✈️ Travel
- 💪 Fitness
-
Set Volume: Choose how many posts to collect
-
Start Scraping: Click Run and watch the data flow
-
Download: Get your data in JSON, CSV, or Excel
📊 Example Input
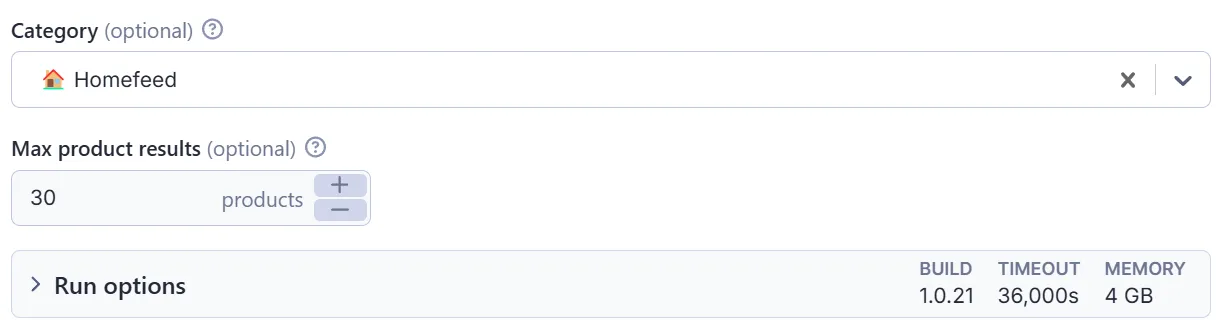
Json input
📈 Sample Output
You can download the dataset extracted by RedNote (XiaoHongShu) Scraper in various formats such as JSON, HTML, CSV, or Excel.
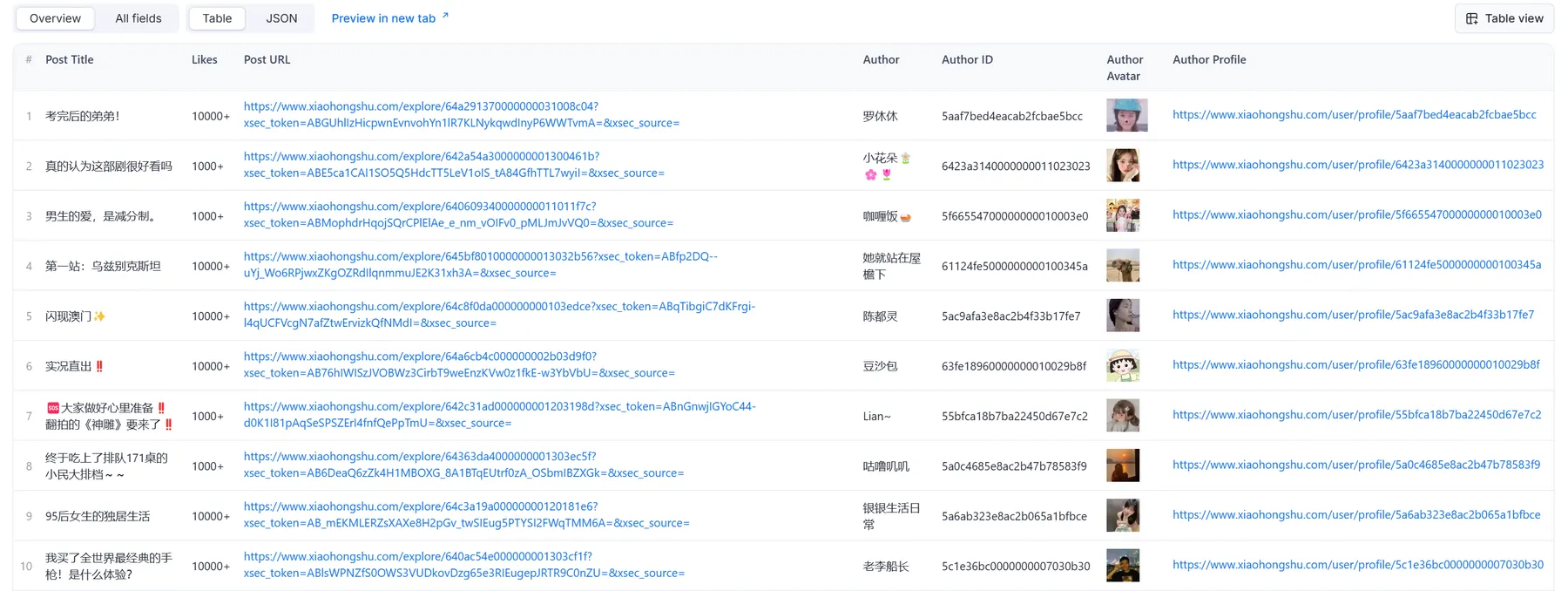
Json output
❓ FAQ
Is it legal to scrape XiaoHongShu?
Our scraper only collects publicly available data while respecting the site's terms. For large-scale scraping, review XiaoHongShu's terms of service.
Need Help?
- 🐛 Found a bug? Create an issue.
- 💡 Need customization? Contact us for tailored solutions