Api Surface Mapper
Pricing
Pay per usage
Api Surface Mapper
An Apify Actor that discovers a website’s API surface by capturing browser network traffic (`fetch`/`xhr`), grouping similar requests into endpoint candidates, scoring them, and generating ready-to-run replay snippets (curl + TypeScript fetch).
Pricing
Pay per usage
Rating
0.0
(0)
Developer
Nikita Chapovskii
Maintained by CommunityActor stats
0
Bookmarked
7
Total users
0
Monthly active users
6 months ago
Last modified
Categories
Share
API Surface Mapper (Crawlee + Playwright)
An Apify Actor that discovers a website’s API surface by capturing browser network traffic (fetch/xhr), grouping similar requests into endpoint candidates, scoring them, and generating ready-to-run replay snippets (curl + TypeScript fetch).
This is API discovery, not HTML scraping: point it at a site, optionally perform a few interactions, and get a ranked list of endpoints the UI is calling.
What it does
For each visited page, the Actor:
- Navigates using
PlaywrightCrawler(Crawlee performs navigation automatically). - Attaches a network tap before navigation to capture early
fetch/xhrrequests. - Optionally runs a flow (
steps) to trigger pagination, infinite scroll, filters, “Load more”, etc. - Waits until the network becomes quiet (no new
fetch/xhrforquietMs). - Builds endpoint candidates:
- normalizes URLs
- patternizes volatile segments (IDs, tokens, etc.)
- groups exchanges by endpoint pattern + method + kind
- Classifies candidates as REST / GraphQL / Other.
- Scores candidates and outputs the top-N with replay snippets.
Key features
- Captures
fetchandxhrrequests (configurable). - Optional JSON response sampling (size-limited).
- GraphQL detection from request body (
query/operationName) even if endpoint is not/graphql. - Endpoint grouping via URL patternization so you get “unique endpoints”, not a dump of raw URLs.
- Generates replay snippets:
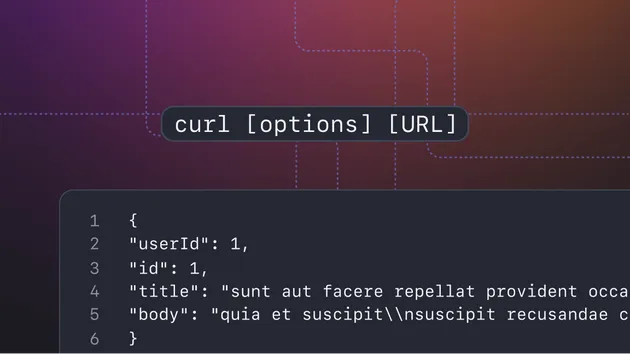
curlfetch(TypeScript)
- Optional link crawling via
enqueueLinks().
Output (Dataset)
For each processed page, the Actor stores an item like:
Input
The input is intentionally flat and simple.
startUrls (required): array of start URLs. Accepts both:
Crawling
- maxRequests (default: 20): maximum number of pages to process.
- enqueueLinks (default: false): whether to discover and enqueue links from each page.
- strategy (default: "same-hostname"): crawling strategy for links:
- "same-hostname" | "same-domain" | "all"
- globs (optional): allowlist patterns for links to enqueue.
- linkSelector (default: "a[href]"): selector used by enqueueLinks().
Capture
- captureTypes (default: ["xhr","fetch"]): which request types to capture.
- maxExchangesPerPage (default: 250): hard cap of captured exchanges per page.
- includeResponseBodies (default: false): if true, attempts to parse JSON responses and store a sample.
- maxBodyKb (default: 256): JSON body size limit (best-effort).
Settle / timing
- quietMs (default: 800): quiet period (no new fetch/xhr) before we consider capture “settled”.
- quietTimeoutMs (default: 15000): hard timeout for settling. Settling waits for the first captured request. This prevents returning “quiet” too early when a page triggers fetch/xhr slightly later.
Page interaction flow
- steps (default: []): page interaction flow (see below).
- continueOnError (default: true): if a step fails, log a warning and continue.
Filtering (optional)
- allowDomains: only capture requests to these domains (if set).
- denyDomains: ignore requests to these domains.
- denyUrlRegex: regex patterns to ignore requests.
Safety / privacy
- redactHeaders: request/response headers to redact (defaults include auth/cookies).
Flow steps (steps)
Supported step types:
- wait
- waitForSelector
- click
- type
- scroll
Example:
Example inputs
Apify website (crawl a few pages)
GraphQL demo (Catstronauts)
Scoring (how candidates are ranked)
Each captured exchange gets a numeric score. Exchanges are grouped into endpoint candidates, and the highest-scoring exchange becomes the representative example for that candidate. Scoring rules (current)
- Noise filter: if URL looks like analytics/telemetry → score = -1000.
- +30 if response content-type includes json.
- +10 if request hints include pagination keywords:
- cursor | offset | limit | page | perpage | nexttoken
- (checked across URL.search and request body text)
- +10 if response size is known and content-length > 20k.
- -50 if HTTP status is >= 400.
- -30 if path looks like auth/session/token/csrf:
- /auth | /session | /csrf | /token
- +15 if parsed JSON response looks list-like:
- an array of objects: [{...}, {...}]
- or an object with items: [...]
Notes
- If includeResponseBodies is disabled, the “list-like response” boost cannot apply.