Reddit Post Comments Scraper | Bulk Thread & Reply Export
Pricing
from $2.99 / 1,000 posts
Reddit Post Comments Scraper | Bulk Thread & Reply Export
Scrape Reddit posts with full comment trees. 6 sort orders, Q&A filtering, and deep sub-thread expansion. Bulk URLs, CSV upload, any format.
Pricing
from $2.99 / 1,000 posts
Rating
0.0
(0)
Developer
ClearPath
Maintained by CommunityActor stats
0
Bookmarked
501
Total users
282
Monthly active users
4 days ago
Last modified
Categories
Share
Reddit Post & Comments Scraper | Bulk Thread Export (2026)
10,000 comments in under 60 seconds — full comment tree expansion, 6 sort orders, bulk processing.
New · June 2026 Find posts by keyword ↗: paste keywords instead of post URLs and get back every comment from the matching posts.
Paste one post URL or upload thousands. Get back every comment, including deeply nested reply chains, sorted exactly how you need them.
| Clearpath Reddit Suite • Search, analyze, and monitor Reddit at scale | |||
|
Keyword search across Reddit |
Bulk profile & karma lookup |
Posts & comments history |
Reddit answers for LLMs |
Copy page for your AI assistant
Copy this block into ChatGPT, Claude, Cursor, or any LLM to start building with this data.
Key Features
- Fast bulk processing — processes multiple posts concurrently, so bulk runs finish in minutes instead of hours
- Full comment tree expansion — optionally scrape every comment in a thread, including deeply nested reply chains that Reddit collapses behind "load more" links
- 6 sort orders — best, top, new, old, controversial, Q&A. Each sort order returns a different ranking of the same comments
- Q&A/AMA filtering — isolate comments answered by the original poster, or find unanswered questions only. Built for extracting structured knowledge from AMA threads
- Bulk input, any format — paste URLs one by one, use bulk edit to paste a list, or upload a CSV/TXT file with thousands of post links. Accepts full URLs, short links, and bare post IDs
- Find posts by keyword — no URLs handy? Enter search keywords and the actor finds the matching posts, then scrapes all their comments. Supports
subreddit:scoping and exact-phrase quotes
How to Scrape Reddit Post Comments
Single post, default settings
Paste any Reddit post URL. The actor fetches the post metadata and up to 200 comments sorted by best.
Short links and bare IDs also work:
You can use any of these formats interchangeably. The actor normalizes all inputs before processing.
All comments, sorted by top
Set maxCommentsPerPost to 0 and enable expandAllComments to get the complete comment tree. Use sort to control the ordering.
This configuration captures every single comment in the thread, including replies nested 10+ levels deep that Reddit hides behind "continue this thread" links. Expect longer run times for threads with thousands of comments.
Multiple posts in one run
Use the postUrls array for small batches. Mix any URL format freely.
The actor processes posts in parallel, so adding more posts doesn't proportionally increase run time.
Bulk from file
Upload a .txt or .csv file through the Apify Console, or point to a hosted file URL. TXT files expect one URL per line. CSV files auto-detect a url or permalink column.
You can also drag and drop a file directly into the "Post URLs file" field in the Apify Console. This is the fastest way to run large batches without writing any code.
Find posts by keyword
No post URLs handy? Leave the URL fields empty and enter search keywords in queries. The actor finds the posts that match each keyword, then scrapes all their comments: the same full comment trees you get from a URL run. Use maxPostsPerQuery to control how many matching posts to pull per keyword.
Operators work inside a keyword: subreddit:AskReddit scopes the search to one subreddit, and quotes match an exact phrase. The full Reddit search syntax works here too: boolean AND/OR/NOT, exclusions, grouping, and field operators like author:, title:, and self:. See the full query syntax and recipes ↗ in the Reddit Search Scraper. If post URLs are also present, they take precedence and the keywords are ignored.
Q&A/AMA thread: only OP answers
Use sort: "qa" with filter: "answered" to get only comments that the original poster replied to. This turns a sprawling AMA with thousands of comments into a clean, structured Q&A dataset.
Find unanswered questions
The opposite of the above. Set filter: "unanswered" to find questions in a Q&A thread that the OP never responded to.
Controversial comments only
Get comments sorted by controversy. Reddit's controversial algorithm surfaces comments with a roughly equal number of upvotes and downvotes.
Chronological order
Sort by old to get comments in the order they were posted. Useful for analyzing how a discussion evolved over time.
Input Parameters
| Parameter | Type | Default | Description |
|---|---|---|---|
postUrl | string | A single Reddit post URL, short link (redd.it/abc), or post ID | |
postUrls | string[] | [] | Multiple post URLs or IDs. Use "Bulk edit" to paste a list |
postUrlsFile | string | Upload a .txt/.csv file, or paste a URL to a hosted file | |
sort | enum | best | Comment sort order: best, top, new, old, controversial, qa |
filter | enum | (all) | Comment filter: all comments, answered (OP replies only), unanswered |
maxCommentsPerPost | integer | 200 | Max comments to scrape per post. Set to 0 for unlimited |
expandAllComments | boolean | false | Recursively expand every collapsed reply chain. Slower but captures the full tree |
At least one of postUrl, postUrls, or postUrlsFile is required.
Sort order reference
| Value | Behavior |
|---|---|
best | Reddit's default. Confidence-weighted ranking that balances score and vote count |
top | Highest score first (upvotes minus downvotes) |
new | Most recent comments first |
old | Oldest comments first (chronological) |
controversial | Comments with roughly equal upvotes and downvotes |
qa | Prioritizes comments from the original poster. Combine with filter for Q&A extraction |
What Data Can You Extract from Reddit Posts?
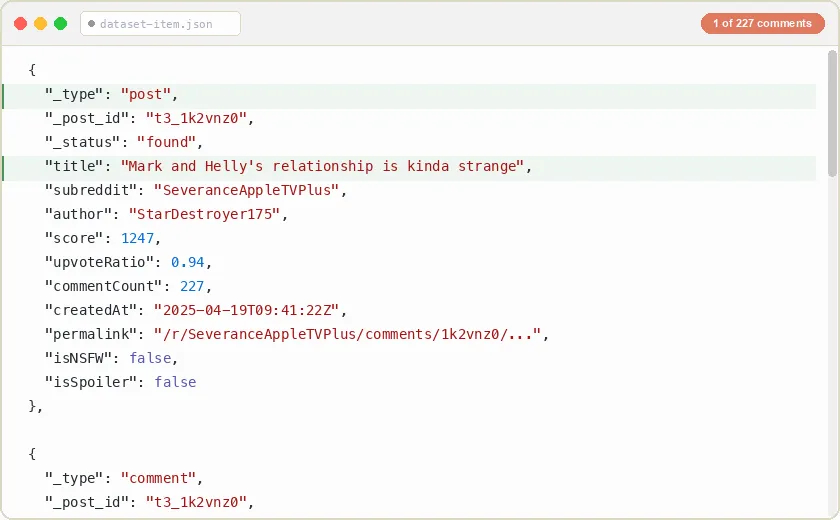
The output contains two row types: post rows and comment rows. Each post URL you provide produces one post row followed by its comment rows. The _post_id field links comments back to their parent post, so you can easily group and filter results when scraping multiple posts.
Post row
One post row per URL, carrying the full post object: every field Reddit exposes for the post (score, author, timestamps, flair, awards, media, content and moderation flags, subreddit subscriber count, and more). The example below is trimmed for readability; large nested objects (preview, media, all_awardings) are shown abbreviated or omitted.
Comment row (top-level)
Top-level comments have depth: 0 and parentId: null. These are direct replies to the post.
Comment row (nested reply)
Replies have depth > 0 and a parentId pointing to the comment they're replying to. You can reconstruct the full thread tree from these two fields.
Full field reference
Post fields: the post row carries the full post object. The table lists the routing keys and the most-used fields; the row also includes every other field Reddit exposes for the post (author_fullname, is_video, media, preview, gallery_data, all_awardings, gilded, distinguished, removed_by_category, num_crossposts, crosspost_parent_list, link-flair colors, subreddit_id, and more).
| Field | Type | Description |
|---|---|---|
_type | string | Always "post" |
_post_id | string | Reddit post ID (t3_ prefixed) |
_status | string | found, not_found, or unavailable |
title | string | Post title text |
subreddit | string | Subreddit name without the r/ prefix |
commentCount | integer | Total comment count reported by Reddit |
author | string | Username of the post author |
score | integer | Net upvotes |
upvote_ratio | number | Fraction of votes that are upvotes |
num_comments | integer | Comment count on the post object |
created_utc | number | Creation time, UNIX seconds (UTC) |
permalink | string | Relative URL path to the post |
url | string | Post URL (outbound link, or the post itself for self-posts) |
selftext | string | Post body text (markdown) for self-posts |
domain | string | Source domain (self.<sub> for self-posts) |
is_self / is_video | boolean | Post type flags |
over_18 / spoiler / stickied / locked / archived | boolean | Content and state flags |
link_flair_text | string/null | Post flair text |
total_awards_received | integer | Number of awards |
subreddit_subscribers | integer | Subscriber count of the subreddit |
Comment fields:
| Field | Type | Description |
|---|---|---|
_type | string | Always "comment" |
_post_id | string | Parent post ID (t3_ prefixed), links this comment to its post |
_status | string | found, not_found, or unavailable |
id | string | Comment ID (t1_ prefixed) |
author | string | Username of the commenter, or null for deleted comments |
score | integer | Upvotes minus downvotes |
createdAt | string | ISO 8601 creation timestamp |
editedAt | string/null | ISO 8601 edit timestamp, or null if never edited |
depth | integer | Nesting depth. 0 = top-level reply to the post, 1 = reply to a top-level comment, etc. |
parentId | string/null | Parent comment ID (t1_ prefixed), or null for top-level comments |
permalink | string | Relative URL path to the comment on Reddit |
body | string | Comment text in markdown format |
isStickied | boolean | true if pinned by a moderator |
isLocked | boolean | true if replies are disabled |
isScoreHidden | boolean | true if the score is hidden by subreddit rules (usually for recent comments) |
distinguishedAs | string/null | "moderator", "admin", or null for regular users |
authorFlair | string/null | User's flair text in the subreddit, or null |
isDeleted | boolean | true if the comment was deleted by the author or removed by moderators |
childCount | integer | Number of direct replies to this comment |
authorId | string/null | Author account ID (t2_ prefixed) |
authorAccountType | string/null | Account type (e.g. USER) |
authorIsCakeDay | boolean | true if the comment was posted on the author's account anniversary |
authorIcon | string/null | Author avatar URL |
languageCode | string/null | Detected language of the comment |
isArchived | boolean | true if the comment is archived |
isRemoved | boolean | true if removed by a moderator |
removedByCategory | string/null | Removal reason category, or null |
isCommercialCommunication | boolean | true if flagged as paid/commercial |
isInitiallyCollapsed | boolean | true if collapsed by default (e.g. low score) |
contentTypeHint | string/null | Body content format hint (e.g. RTJSON) |
Pricing — Pay Per Event (PPE)
| $2.99 per 1,000 posts • $1.00 per 1,000 comments |
Charged separately for posts and comments. A run scraping 5 posts with 200 comments each costs ~$1.02.
Use Cases
Sentiment analysis. Scrape comments from product launch posts, company announcements, or brand mentions to analyze public opinion. The score field provides a built-in signal for community agreement, and depth/parentId let you analyze how discussions branch.
Training data for LLMs. Extract large volumes of structured discussion data. Comments include the full reply chain hierarchy, so you can build conversation trees for fine-tuning dialogue models. The Q&A filter is especially useful for extracting clean question-answer pairs from AMA threads.
Market research. Monitor how Reddit communities discuss products, services, or trends. Scrape comments from relevant subreddit posts to understand what real users think, what complaints come up repeatedly, and what features people request.
Academic research. Study online discourse patterns, community dynamics, or information propagation. The chronological sort (old) combined with depth and parentId lets you reconstruct exactly how conversations developed over time.
Content curation. Extract top-rated comments from popular threads to curate highlights, summaries, or "best of" collections. Sort by top and set a low maxCommentsPerPost to get only the highest-rated responses.
Competitive intelligence. Track discussions about competitors, industry news, or market events across multiple subreddits. Upload a CSV of relevant post URLs and scrape them all in one run.
FAQ
How many comments can I scrape per post?
Set maxCommentsPerPost to 0 and enable expandAllComments to get every comment in a thread. Reddit posts can have tens of thousands of comments. The actor handles all of them, including deeply nested reply chains.
What does "Expand all sub-threads" actually do?
Reddit collapses deeply nested reply chains and shows "load more comments" links. When expandAllComments is enabled, the actor recursively opens every one of these collapsed chains so you get the complete comment tree. When disabled, you get the comments visible on the default page load, which is faster but incomplete for threads with many replies.
How fast is it? Posts are processed in parallel. A single post with 200 comments finishes in about 3 seconds. Bulk runs with 100 posts at default settings complete in about a minute. Full expansion takes longer proportional to the number of collapsed reply chains.
What URL formats are accepted?
Full URLs (reddit.com/r/sub/comments/abc123/title), short links (redd.it/abc123), bare post IDs (abc123), and prefixed IDs (t3_abc123). You can mix formats freely in the same run. The actor normalizes everything before processing.
What happens if a post is deleted or private?
Deleted, removed, and private posts are included in the output with "_status": "not_found" or "_status": "unavailable". You're only charged for posts and comments that were successfully scraped.
How does the Q&A filter work?
Set sort to qa and filter to answered to get only comment threads where the original poster replied. Set filter to unanswered to get threads with no OP response. This works best on AMA threads and support posts where the OP actively responds to questions.
Can I reconstruct the comment tree from the output?
Yes. Every comment includes depth (0 for top-level, 1 for first reply, etc.) and parentId (the ID of the comment it replies to, or null for top-level). Walk these two fields to rebuild the full tree structure in any programming language.
What's the difference between "best" and "top" sort? "Top" ranks comments purely by score (upvotes minus downvotes). "Best" uses a confidence-weighted algorithm that accounts for both score and vote count. This means newer comments with fewer but mostly positive votes can rank above older comments with more total votes. "Best" is Reddit's default for good reason: it surfaces quality content that hasn't had time to accumulate raw vote counts.
How are deleted comments handled?
Deleted comments appear in the output with isDeleted: true, author: null, and body containing "[deleted]" or "[removed]". They're still part of the comment tree and preserve the thread structure. They count toward your comment total and billing.
Is there a limit on how many posts I can scrape in one run? No hard limit. You can process thousands of posts in a single run. The actor scales linearly — doubling the number of posts roughly doubles the run time, not more.
Can I use this with the Apify API or integrations? Yes. Call the actor via the Apify API, schedule recurring runs, or connect it to integrations (webhooks, Zapier, Make, Google Sheets). The output is standard JSON that works with any downstream pipeline.
What's the output format?
A flat JSON array. Post rows and comment rows are interleaved: first a post row, then all its comments, then the next post row, and so on. Each row has a _type field ("post" or "comment") and a _post_id field that links comments to their parent post.
More Clearpath scrapers for Reddit
🔍 Search & discovery
 Reddit Search Scraper
Reddit Search Scraper
Keyword search across all of Reddit Reddit Subreddit Posts Scraper
Reddit Subreddit Posts Scraper
Full subreddit feeds: hot, new, top, rising
👤 Users
 Reddit Profile Scraper
Reddit Profile Scraper
Bulk username, karma, and account lookup Reddit User Posts & Comments Scraper
Reddit User Posts & Comments Scraper
A single user's full post and comment history
🤖 AI & LLM tools
 Reddit MCP Server
Reddit MCP Server
Live Reddit search inside your AI assistant Reddit Answers API
Reddit Answers API
Reddit's AI answer engine for any question Reddit to LLM
Reddit to LLM
Clean Reddit threads as Markdown for AI pipelines
Support
- Bugs: Issues tab
- Features: Email or issues
- Email: max@mapa.slmail.me
Legal Compliance
Extracts publicly available data. Users must comply with Reddit terms and data protection regulations (GDPR, CCPA).
Bulk Reddit post and comment extraction. Full trees, sorted and filtered, from one URL or thousands.