Truth Social Scraper (it Worked)
Pricing
from $0.99 / 1,000 results
Truth Social Scraper (it Worked)
Truth Social Scraper extracts real-time posts, replies, and interaction metrics directly from user profiles. It uses browser automation to intercept official network requests, easily bypassing standard anti-bot protections to deliver clean JSON data.
Pricing
from $0.99 / 1,000 results
Rating
0.0
(0)
Developer
Luffy
Maintained by CommunityActor stats
0
Bookmarked
3
Total users
0
Monthly active users
2 months ago
Last modified
Categories
Share

Truth Social Scraper: Extract Posts, Media, Replies, and Engagement Data from truthsocial.com
The Truth Social scraper is a no-code data extraction tool for truthsocial.com. Point it at any public Truth Social profile and it returns clean, structured JSON: posts, replies, retruths, media attachments, follower counts, and per-post engagement numbers. No login required, no fragile CSS selectors, and no headless browser to babysit.
If you have tried to track what is posted on truth social at any real scale, you already know why this exists. The timeline is dynamic, and most generic scrapers either time out, get rate-limited into the ground, or hand back half-populated objects with missing media URLs. This actor handles all of that for you.
What this Truth Social scraper actually does
You give it a list of usernames. It fetches the user's statuses, handling proper pagination, and writes every post to a dataset. You can cap how many posts per user, filter to media-only, exclude replies, or do the opposite and pull only replies. If a previous run died halfway, you can resume from a specific post ID instead of starting over.
The output is the raw, full-fat JSON object for each status. That includes the post ID, creation timestamp, visibility, language, and source URL. You get the full post HTML and a cleaned plain-text version. The complete account object comes along with each post: display name, bio, follower count, following count, total statuses, avatar and header image URLs, verified and premium flags. Every media attachment includes both the original and preview URLs plus its type (image, video, gifv). Counts for replies, retruths, favorites, upvotes, and downvotes are all there. Mentions, hashtags, and quote or reblog references show up when present.
You can keep the raw HTML content field, or strip it out with cleanContent: true and keep only the plain text. Handy if you are dumping into a database and do not want to deal with escaping later.
Why scraping truthsocial.com is harder than it looks
A few things trip people up when they try to scrape truth social with a generic web scraper.
The site is a single-page app. The timeline you see in your browser is fetched via API after the page loads, so a basic HTTP GET of the profile URL returns almost no useful content. You need to either render JavaScript (slow, expensive) or hit the API directly (fast, but you need to know the patterns and handle the auth headers).
Account IDs are not the same as usernames. The URL says @realDonaldTrump but the API needs the numeric account ID, like 107780257626128497. You have to resolve that first, and the resolution endpoint has its own rate limits.
Pagination uses max_id cursors, not page numbers. Handle this wrong and you either re-fetch the same page in a loop forever or skip entire chunks of history without noticing.
Rate limits are real and not always documented. Hammer the endpoint and you get capped, sometimes for hours. This scraper paces requests, retries with backoff, and rotates through Apify's proxy pool so long runs do not crater halfway through.
Use cases for the Truth Social scraper
Anyone working with content from truthsocial.com at any real scale hits the same wall: you need the data in a usable format, not as screenshots or copy-pasted text. Here is where this scraper actually pays for itself.
🔬 Researchers & Academics Track political messaging, run sentiment models, or study echo chambers. The full account object lets you weight posts by reach, ensuring a 12-million-follower account doesn't get the same weight as one with 200 followers. Assemble large public datasets cleanly.
📰 Journalists & Fact-Checkers Pull exact posts from the API with verifiable timestamps and post IDs. If a public figure said something on truthsocial.com, you get a permanent record that survives even if the post is deleted later. Extract attached images to run reverse-image searches easily.
📈 Financial Markets & Hedge Funds Watch statements from political figures and CEOs that move markets. Latency matters, and so does structured data you can pipe straight into your alerting systems and trading models.
🛡️ PR & Communications Teams Watch for mentions of your company, executives, or products. Set up keyword alerts on replies to a client's account so your team finds out about negative sentiment spikes instantly.
📊 Social Media Analysts & Strategists Build per-account engagement dashboards. Favorites, retruths, and reply counts are included in every response. See what content performs best (video vs. text, links vs. native) to inform editorial decisions.
💾 Archivists & Intelligence Teams Drop the JSON output straight into Elasticsearch, Postgres, or a vector store. The
startPostIdparameter lets you do clean incremental backups without re-fetching the same data every time.

Input parameters
| Parameter | Type | Default | Description |
|---|---|---|---|
profiles | array | ["realDonaldTrump"] | List of Truth Social usernames to scrape. No @ prefix needed. |
maxItemsPerProfile | integer | 100 | Maximum number of posts to extract per profile. Set higher for backfills. |
onlyMedia | boolean | false | Return only posts with at least one media attachment. |
onlyReplies | boolean | false | Return only posts that are replies to other posts. |
excludeReplies | boolean | true | Skip replies. Mutually exclusive with onlyReplies. |
cleanContent | boolean | false | Drop the raw HTML content field and keep only contentText. |
startPostId | string | "" | Resume from a specific post ID. Useful for incremental scheduled runs. |
Example input
This pulls the 50 most recent non-reply posts from both accounts, strips the HTML, and returns plain text plus all metadata.
Output format
Each item in the dataset is one post. The schema mirrors the Truth Social API response one-to-one, with three extra convenience fields (contentText, authorUsername, authorDisplayName) added so you do not have to dig into the nested account object for the common cases.
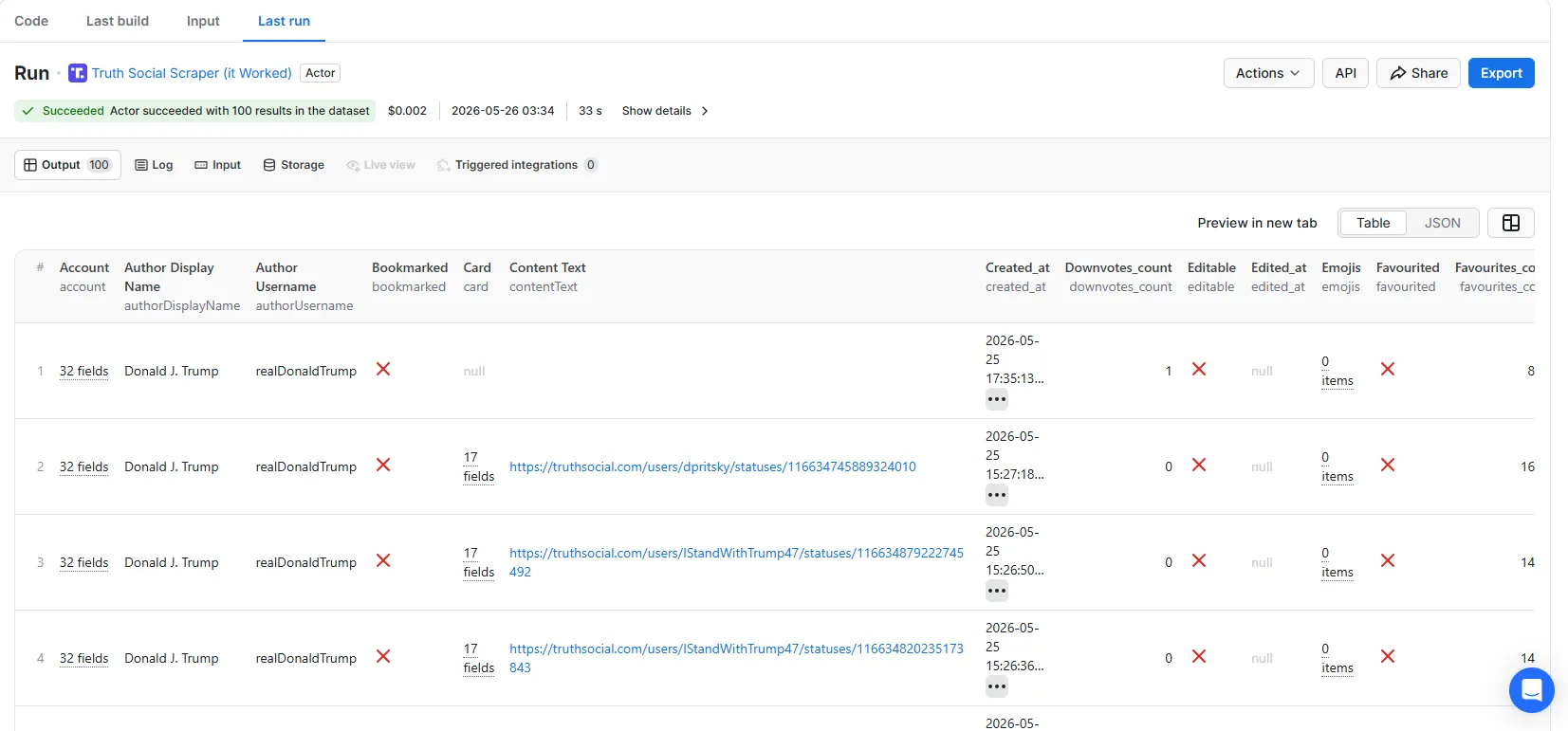
How to run it
Three options, use whichever fits your workflow.
Run it on the Apify platform with no code. Open the actor page, paste your usernames into the input form, hit start. Results land in the default dataset and you can export to JSON, CSV, or Excel from the UI. Good for one-off pulls and for non-developers on the team.
Run it from Python. Install apify-client, drop in your API token, call run with the input dict, iterate the dataset. Five lines of real code. This is how you wire it into an existing data pipeline.
Run it from Node.js. Same idea on the JavaScript side: npm install apify-client, instantiate the client, call the actor, await the dataset. Works in any backend, serverless function, or scheduled job.
For ongoing collection, use Apify's built-in scheduler. Set it to every 30 minutes, every hour, or every day, whatever your use case needs. Pass the last seen startPostId between runs and you only fetch new posts each time.
Legal and ethical notes
Public posts on truthsocial.com are, by definition, public. Scraping them for research, journalism, archival, or analytics is generally fine. How you use that data is on you. Do not use it to harass individuals, build surveillance products targeting private citizens, or break Truth Social's terms in ways that will get you banned. If you republish content, follow normal attribution and fair-use practices. If you are not sure whether your use case is acceptable, talk to a lawyer, not a scraper README.