LinkedIn Recruiter / Job Poster Finder
Pricing
from $2.40 / 1,000 lead-results
LinkedIn Recruiter / Job Poster Finder
Find recruiters, hiring managers, and job posters from public LinkedIn jobs - one flat lead row per person, with job context (matched job, company, role keyword, location), relevance score, and reason tags. No LinkedIn login or cookies required.
Pricing
from $2.40 / 1,000 lead-results
Rating
0.0
(0)
Developer
Delowar Munna
Maintained by CommunityActor stats
1
Bookmarked
15
Total users
7
Monthly active users
a month ago
Last modified
Categories
Share

Find recruiters, hiring managers, and job posters behind public LinkedIn job listings — clean, flat, CSV-ready people leads with matched-job context (job title, company, location, posted date), a transparent relevance score, and reason tags. Built for staffing agencies, recruiting teams, sales / lead-gen, and B2B research.
No LinkedIn login, no cookies, no session IDs. The actor uses LinkedIn's public guest jobs surface over HTTP. You pay one flat event per unique lead row pushed to the dataset.
✨ Why this scraper
- People-first, not job-first — every row is a person/lead with hiring context (matched job, company, role keyword, location, source type), not a job listing.
- Three discovery modes —
jobs_with_posters(default),recruiter_search(recruiter-titled searches harvested for people),combined(both, deduped). - 30 flat fields — person identity, source type, matched-search context, optional job context, relevance score + reason tags. No nested objects; drops straight into Sheets/Excel/CRMs.
- Pay-Per-Event — one flat
lead-resultevent per saved unique lead. Duplicates, person-less jobs, and filtered rows are never charged. - No login / cookies / sessions — just keywords (or pasted LinkedIn job URLs).
- Transparent relevance score (PRD §7) — rule-based, no AI, explained below.
🚀 Quick start — sample inputs
Example 1 — jobs with posters (default)
Example 2 — combined (jobs + recruiter searches, deduped)
Provide at least one of
keywords(with optionallocations) orjobUrls. The actor blocks Apify Residential proxy; if you need residential routing, supply your own provider viaproxyConfiguration.proxyUrls. See 🚦 Proxy policy below.
📦 Output
The dataset has one view: Recruiter / job-poster leads — a 30-column flat table.
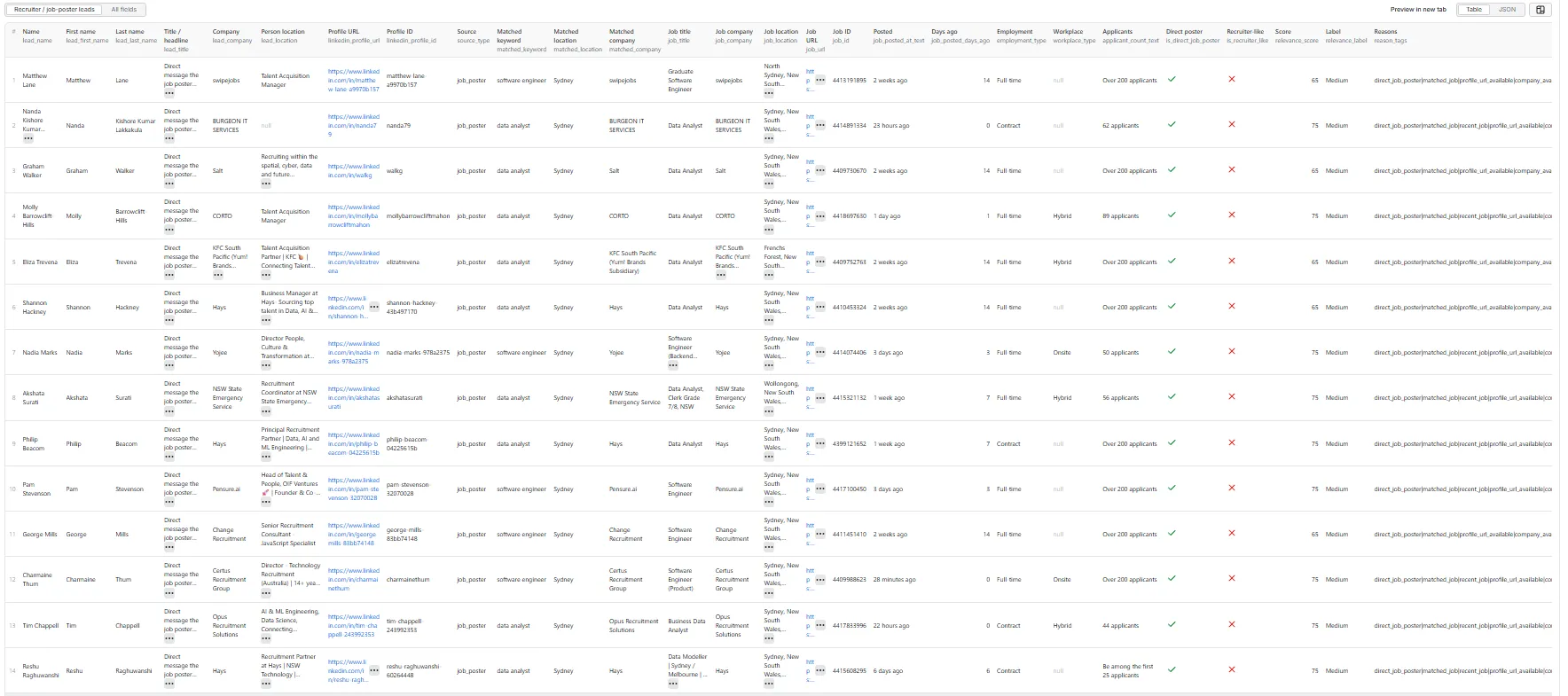
Output fields (30)
lead_name, lead_first_name, lead_last_name, lead_title, lead_company, lead_location, linkedin_profile_url, linkedin_profile_id, source_type, matched_keyword, matched_location, matched_company, job_title, job_company, job_location, job_url, job_id, job_posted_at_text, job_posted_days_ago, employment_type, workplace_type, applicant_count_text, is_direct_job_poster, is_recruiter_like, relevance_score, relevance_label, reason_tags, search_url, input_url, scraped_at.
Sample record — Recruiter / job-poster leads
🎯 Relevance score (PRD §7)
Transparent rule-based score (0–100) computed from extracted fields — no AI, no external enrichment.
| Signal | Points |
|---|---|
| Direct job poster or hiring-team contact visible | +35 |
| Title/headline contains recruiter / hiring / talent keyword | +25 |
| Matched to a specific job posting | +15 |
| Job posted within the last 7 days (where parsed) | +10 |
| LinkedIn profile URL available | +10 |
| Company available | +5 |
Score is capped at 100.
Labels: High (80–100) · Medium (60–79) · Low (30–59) · Weak (0–29).
reason_tags is a pipe-separated string (CSV-safe). Vocabulary: direct_job_poster, hiring_team_visible, recruiter_title, talent_acquisition_title, matched_job, recent_job, profile_url_available, company_available, keyword_match.
💰 Pricing
Pay-Per-Event. One flat event per saved row (final per-event price is configured on the Apify console):
| Event | Charged when |
|---|---|
lead-result | Once per unique recruiter / job-poster lead row that passed all filters and was written to the dataset. |
So your bill is simply results_saved × price_per_event. The actor honors the user-configured per-run spending cap (Apify eventChargeLimitReached): it both caps how many results it collects up-front to what the limit can pay for, and stops cleanly the moment the cap is reached during charging.
Not charged:
- Duplicates (deduplicated by profile ID/URL and normalized name+company).
- Rows filtered out by company / title / date / workplace filters.
- Job pages with no visible person identity (PRD §6 — leads must include at minimum a profile URL or a name + company/title).
- Failed or blocked requests.
🚦 Proxy policy
Use Apify Datacenter proxy or no proxy for normal runs — both work for LinkedIn's public guest jobs surface at this actor's conservative concurrency.
Apify Residential proxy is not supported. The actor will fail at startup if proxyConfiguration.apifyProxyGroups includes RESIDENTIAL. Reason: in pay-per-event actors, residential bandwidth (~/GB) is billed to the developer, not the run user, so a single bandwidth-heavy run could exceed the per-result event revenue.
If you genuinely need residential routing, supply your own residential provider via the proxy editor's Custom proxy URLs field — that traffic goes through your provider, not Apify, and is unaffected:
📊 Run summary
After each run, a RUN_SUMMARY entry is written to the key-value store:
charged_events equals the number of successfully saved unique lead rows.
⚙️ Filters
| Filter | Stage | Effect |
|---|---|---|
mode | Source builder | jobs_with_posters / recruiter_search / combined — decides which searches are run. |
datePosted | Source + post | any / past_24h / past_week / past_month. Enforced at LinkedIn where stable. |
remoteFilter | Source + post | any / remote / hybrid / onsite. |
companyNames | Pre + post | Case-insensitive substring on lead_company, matched_company, job_company. |
titleKeywords | Post | Case-insensitive substring on lead_title. Direct posters always pass (PRD §8). |
maxResults | Both stages | Caps saved unique lead rows across the whole run. |
maxJobsToInspect | Crawl-time | Safety cap on detail pages opened. |
deduplicate | Both stages | Profile ID/URL + name+company keys (recommended ON). |
Filters are applied before any dataset push or event charge.
🚧 Limitations (V1)
- Public guest data only: no login, cookies, or member-only content. Many LinkedIn job pages do not publicly expose the "Meet the hiring team" / job-poster module to logged-out viewers. When no person is visible, the row is dropped per PRD §6 — you are never charged for person-less jobs.
lead_locationisnullunless the public detail fragment exposes the person's location (rare).- No people-search crawling:
recruiter_searchdoes not target LinkedIn's auth-walled people search. It expands the recruiter title set into the same guest-jobs surface, then harvests the visible hiring contact behind each posting. - No email enrichment, company-website crawling, or AI scoring.
- LinkedIn guest pagination tops out around ~1,000 results per search source; narrow searches return more coverage than broad ones.
maxResultscaps saved unique rows across the whole run (not per query);maxJobsToInspectis a separate safety cap on detail visits.
❓ FAQ
Do I need a LinkedIn account or cookies? No. The actor only uses LinkedIn's public guest jobs endpoints.
Why are some runs lean?
Public LinkedIn often hides the hiring-team module from logged-out viewers. The actor only saves rows where a person identity is visible (PRD §6). Try broader keywords/locations or use combined mode to maximize coverage.
How is is_direct_job_poster different from is_recruiter_like?
is_direct_job_poster means LinkedIn visibly attaches the person to the job posting (the "message the job poster" / direct-poster module). is_recruiter_like is a title-based heuristic (recruiter / talent acquisition / hiring manager...) and works for both direct posters and visible hiring-team members.
Can I paste a LinkedIn jobs search URL?
Yes — put it in jobUrls. Both /jobs/view/<id> and /jobs/search/?keywords=... URLs are supported. Search URLs preserve their filters and the actor paginates them.
Can I export to CSV?
Yes — every field is flat (no nested objects). Use Apify's CSV / Excel export, or call the dataset API with format=csv. reason_tags is intentionally pipe-separated to remain a single CSV cell.
Will I get blocked? The actor uses conservative concurrency (1–5), realistic headers, session rotation, and retry/backoff. Default Apify Proxy is sufficient for typical small/medium runs.
🛠️ Technical notes
- Stack: Node.js 22 · Apify SDK 3 · Crawlee
CheerioCrawler· Cheerio + native fetch. No browser. - Endpoints: LinkedIn public guest
seeMoreJobPostings(search) andjobPosting(detail). - Concurrency:
min=1,max=5(conservative; tune after real runs). - Memory: 1 GB min · 2 GB default · 4 GB max.
- Proxy: Apify Proxy enabled by default; custom configs accepted; Apify Residential rejected at startup.