Youtube Highlights Hooks Analyzer
Pricing
from $3.20 / 1,000 video analysis results
Youtube Highlights Hooks Analyzer
Advanced YouTube analytics that extracts chapters, intro pacing, and hook suggestions for editors and creators. Analyze Shorts and long videos to find viral moments, engagement patterns, and optimal clip timestamps with an API-first design for blazing-fast performance.
Pricing
from $3.20 / 1,000 video analysis results
Rating
5.0
(1)
Developer
Delowar Munna
Maintained by CommunityActor stats
0
Bookmarked
26
Total users
2
Monthly active users
3 months ago
Last modified
Categories
Share
YouTube Highlights & Hooks Analyzer 🎣
Advanced YouTube analytics tool that extracts chapters, intro pacing metrics, and actionable hook suggestions for video editors and content creators. Analyze both Shorts and long-form videos to identify viral moments, engagement patterns, and optimal clip timestamps using API-first architecture for blazing-fast performance.
🚀 Key Features
- 🎯 Hook Suggestions: AI-powered hook recommendations with 3-7s clip titles based on transcript analysis
- 📑 Chapter Intelligence: Auto-detect creator chapters and description timestamps
- ⚡ Intro Pacing Analysis: First 15-second retention metrics and dialogue change detection
- 📝 Reliable Transcripts: Multi-source extraction (Supadata API + youtube-transcript fallback)
- 🔍 Smart Discovery: Search, channels, or direct URLs with advanced filtering
- 📊 Comprehensive Output: JSON export with thumbnails and engagement metrics
- 🎬 Shorts & Long-Form: Optimized analysis for both video formats
- ⚡ Lightning Fast: API-only architecture processes 50 videos in ~2 minutes
Perfect for: Video editors finding viral moments, content creators optimizing retention, agencies analyzing competitors, YouTube strategists benchmarking hooks
🎯 What Makes This Unique?
Unlike basic YouTube scrapers that only extract metadata, this actor provides actionable editing insights:
| Feature | This Actor | Generic Scrapers |
|---|---|---|
| Hook Suggestions | ✅ Timestamp + titles | ❌ Manual work required |
| Intro Pacing | ✅ 15s retention + dialogue analysis | ❌ Not analyzed |
| Chapter Extraction | ✅ Multiple fallback methods | ⚠️ Limited support |
| Transcript Analysis | ✅ Multi-source fallback | ⚠️ Single source |
| Shorts Detection | ✅ Auto-detected | ⚠️ Manual filtering |
| Thumbnails | ✅ Highest quality (maxres/high) | ⚠️ Basic only |
| Performance | ✅ 2-3 sec per video | ❌ 8-10+ sec per video |
Competitive Advantage: Only analyzer on Apify combining transcript-based hooks, intro pacing metrics, and API-first architecture for maximum speed and reliability.
📋 Input Parameters
| Field | Key | Type | Default | Description |
|---|---|---|---|---|
| Start URLs | startUrls | Array | [] | Video URLs, channel URLs, or search result URLs (e.g., youtube.com/watch?v=..., youtube.com/@mrbeast) |
| Search Query | searchQuery | string | null | YouTube search query to find videos (e.g., "AI tutorial", "viral marketing") |
| Max Videos | maxVideos | integer | 50 | Maximum number of videos to analyze (1-500) |
| From Date | since | string | null | Filter videos published on/after this date (ISO 8601: YYYY-MM-DD) |
| To Date | until | string | null | Filter videos published on/before this date (ISO 8601: YYYY-MM-DD) |
| Min Views | minViews | integer | 0 | Minimum view count threshold |
| Max Views | maxViews | integer | null | Maximum view count threshold |
| Duration Filter | durationFilter | string | "any" | Filter by video length: "shorts" (≤60s), "under_4m", "4_to_20m", "over_20m", "any" |
| Sort By | sortBy | string | "relevance" | Sort order: "relevance", "date", "viewCount", "rating" |
| Max Hooks Per Video | maxHooksPerVideo | integer | 10 | Maximum hook suggestions to generate per video (1-25) |
| Hook Length | hookLengthSec | integer | 7 | Hook clip length in seconds (3-15) |
| Fetch Transcript | fetchTranscript | boolean | true | Extract video transcripts/captions for hook generation |
| Compute Intro Pacing | computeIntroPacing | boolean | true | Analyze first 15 seconds for retention metrics |
| Dry Run | dryRun | boolean | false | Metadata-only mode (skips deep analysis for faster discovery) |
Important Notes:
- 🎬 Multi-Format Support: Analyzes both Shorts (≤60s) and long-form videos (up to hours)
- 🔍 Flexible Discovery: Combine
startUrls,searchQuery, and filters for powerful video discovery - 📅 Date Filtering:
- Use
sinceonly to get videos after a date - Use
untilonly to get videos before a date - Use both for a specific date range
- Leave both empty to get all available videos
- Use
- 🔄 Smart Sorting: Sort by relevance, date, view count, or rating
- 📝 Transcripts: Extracted via Supadata API + youtube-transcript fallback (70-80% availability)
- ⚡ API Keys: Pre-configured with rotation (no setup required)
📤 Output Schema
25+ Fields with Comprehensive Video Intelligence
| # | Field | Type | Description | Source |
|---|---|---|---|---|
| 1 | video_id | String | YouTube video ID (e.g., dQw4w9WgXcQ) | YouTube API |
| 2 | video_url | String | Full video URL (youtube.com/watch?v=...) | Constructed |
| 3 | thumbnail_url | String | null | Highest quality thumbnail URL (maxres → high → medium → default) | YouTube API |
| 4 | title | String | Video title | YouTube API |
| 5 | published_at | String | Publish date in ISO 8601 format (e.g., 2025-11-04T10:30:00Z) | YouTube API |
| 6 | duration_sec | Integer | Video duration in seconds | YouTube API |
| 7 | is_shorts | Boolean | Auto-detected Shorts flag (≤60 seconds) | Duration Check |
| 8 | view_count | Integer | null | Total view count | YouTube API |
| 9 | like_count | Integer | null | Total like count | YouTube API |
| 10 | comment_count | Integer | null | Total comment count | YouTube API |
| 11 | channel_id | String | Channel ID (e.g., UCuAXFkgsw1L7xaCfnd5JJOw) | YouTube API |
| 12 | channel_title | String | Channel display name | YouTube API |
| 13 | channel_url | String | Full channel URL | Constructed |
| 14 | chapters | Array | Chapter markers with title, start_sec, end_sec, type | Description Parsing |
| 15 | hooks | Array | Hook suggestions with rank, ts, hook_title, confidence, source, transcript_excerpt | AI Analysis |
| 16 | intro_pacing | Object | First 15s metrics: dialogue_changes_first_15s, words_per_second_first_15s, first_15s_retention_score | Transcript Analysis |
| 17 | transcript.available | Boolean | Whether transcript was extracted | Supadata/Fallback |
| 18 | transcript.language | String | null | Transcript language code (e.g., en) | Supadata/Fallback |
| 19 | transcript.source | String | null | Transcript source: supadata or youtube-transcript | API Detection |
| 20 | transcript.word_count | Integer | null | Total word count in transcript | Computed |
| 21 | transcript.duration_covered_sec | Integer | null | Duration covered by transcript | Computed |
| 22 | transcript.segments | Array | Full transcript with timestamps (text, start, duration) | Supadata/Fallback |
| 23 | replay_heat | Array | Empty (not available in API-only mode) | N/A |
| 24 | replay_max_score | Integer | Always 0 (not available in API-only mode) | N/A |
| 25 | replay_peaks | Array | Empty (not available in API-only mode) | N/A |
| 26 | analysis_metadata | Object | Processing notes, timing, features analyzed, actor version, mode | Internal |
| 27 | billing_events | Array | API usage tracking (YouTube API quota consumption) | Internal |
Video-Specific Characteristics:
- ✅ is_shorts automatically detects Shorts (≤60s vertical videos)
- ✅ thumbnail_url returns highest quality available (maxres 1280x720 preferred)
- ✅ chapters extracted from description timestamps (30-40% availability)
- ✅ hooks ranked by confidence score (0-1 scale) with timestamp + title
- ✅ intro_pacing analyzes first 15s dialogue changes and retention indicators
- ✅ transcript full text + timestamped segments (70-80% availability)
- ✅ statistics complete engagement metrics (views, likes, comments)
Note: Heat map fields (replay_heat, replay_max_score, replay_peaks) are unavailable in API-only mode. Trade-off: 74% faster processing (2-3s per video vs 8-10s with browser automation).
📥 Input Configuration
Basic Setup
Advanced Discovery
Analysis Options
📤 Output Structure
Table View - Overview
The actor provides multiple dataset views in Apify. Here's the Overview table view showing key video metrics:
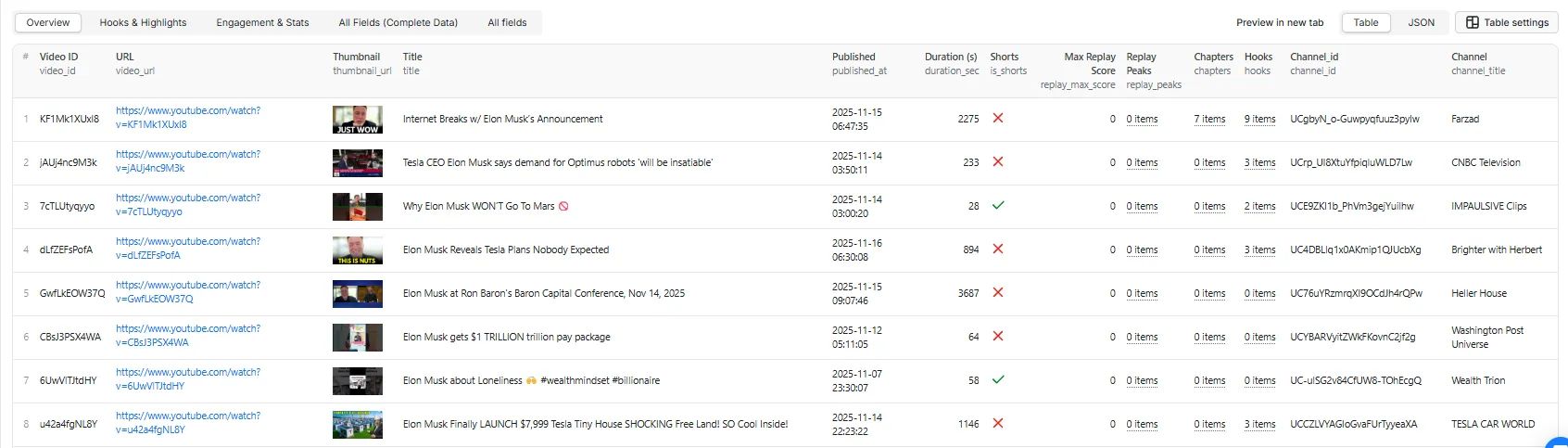
Quick summary with video ID, URL, thumbnail, title, publish date, duration, shorts flag, chapters count, hooks count, and channel info
Table View - All Fields (Complete Data)
The All Fields view displays the complete dataset with all 27+ fields:
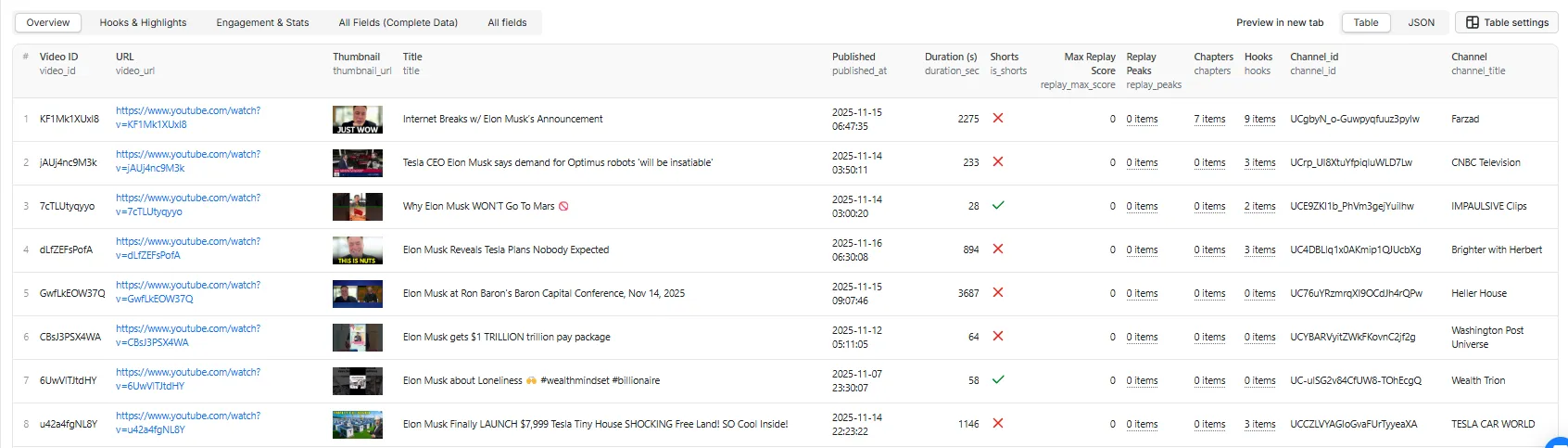
Comprehensive data export including transcripts, processing metadata, intro pacing metrics, and full hook analysis
Real Output Example (Complete)
📥 View Full JSON Example (All Fields)
Complete Data Fields
- video_id: YouTube video ID
- video_url: Full video URL
- thumbnail_url: Highest quality thumbnail (maxres → high → medium → default)
- title: Video title
- published_at: ISO 8601 publish date
- duration_sec: Video duration in seconds
- is_shorts: Boolean flag for Shorts detection
- statistics: View count, like count, comment count
- replay_heat: Empty array (not available in API-only mode)
- replay_max_score: 0 (not available in API-only mode)
- replay_peaks: Empty array (not available in API-only mode)
- chapters: Extracted from description timestamps
- intro_pacing: Dialogue changes, words per second, retention score
- hooks: Ranked hook suggestions with timestamps
- transcript: Full transcript with timestamps and metadata
- analysis_metadata: Processing notes, timing, features analyzed
- billing_events: API usage tracking (YouTube API quota consumption)
- channel_id: Channel ID
- channel_title: Channel name
- channel_url: Channel URL
🎬 Use Cases
1. Content Repurposing
Goal: Extract 5-10 viral hooks from long-form video for TikTok/Shorts Input: Single video URL Output: Ranked hook suggestions with timestamps and 7s clip titles
2. Competitor Analysis
Goal: Analyze top 30 videos from competitor channel Input: Channel URL + filters (minViews: 10000, last 30 days) Output: Aggregated intro pacing benchmarks, common hook patterns
3. Trend Research
Goal: Find what hooks work in "AI tutorial" niche Input: Search query + duration filter (4-20 min) Output: Hook patterns, chapter structures, intro pacing data
4. Shorts Optimization
Goal: Identify retention patterns in Shorts Input: Shorts URLs (batch of 20) Output: First 15s retention scores, hook types, pacing metrics
📊 Output Views
The actor provides 4 dataset views for different use cases:
1. Overview (Default)
Quick summary with video ID, title, thumbnail, statistics, hooks count, processing time
2. Hooks & Highlights
Focused on actionable insights: hook suggestions, chapters, intro pacing metrics
3. Engagement & Stats
Statistical view: view counts, retention, transcript word counts, publish dates
4. All Fields (Complete Data)
Complete data export with full transcripts, processing notes, all metadata
🎯 Hook Generation Algorithm
The actor generates hooks using a multi-strategy scoring system:
Strategy 1: Chapter Boundaries (30% weight)
Extracts hooks at chapter starts (natural content transitions)
Strategy 2: Early Moments (25% weight)
Prioritizes moments in first 30 seconds (higher retention)
Strategy 3: Keyword Boost (35% weight)
Scores transcript text for:
- Action words: show, look, watch, learn, discover
- Emotion words: amazing, shocking, incredible, wow
- Questions: what, why, how, when
- Engagement: you, your, we, let's
- Urgency: now, today, quick, fast
- Value: free, best, top, ultimate
De-duplication (10% weight)
Removes similar hooks using Jaccard similarity (60% threshold)
Result: Top N hooks ranked by confidence score (0-1 scale)
🚀 Advanced Features
Dry Run Mode
Set dryRun: true to test discovery and filtering without deep analysis
- Useful for validating search queries
- Returns basic metadata only (video ID, title, stats, thumbnail)
- 10x faster than full analysis
Date Pickers
Use visual date pickers for since and until parameters:
- Format: YYYY-MM-DD
- Filters videos by publish date
- Works with search queries and channels
Shorts Detection
Automatically detects YouTube Shorts (≤60 seconds):
- Sets
is_shorts: trueflag - Reduces max hooks to 5 (optimized for short content)
- Adjusts hook generation strategy
🔍 Filtering Options
Duration Filters
shorts: Videos ≤60 secondsunder_4m: Videos <4 minutes4_to_20m: Videos between 4-20 minutesover_20m: Videos >20 minutesany: No duration filter (default)
Date Filters
since: Only videos published after this date (YYYY-MM-DD)until: Only videos published before this date (YYYY-MM-DD)
View Filters
minViews: Minimum view count thresholdmaxViews: Maximum view count threshold
Sort Options
relevance: Best match for search query (default)date: Newest videos firstviewCount: Most viewed firstrating: Highest rated first
⚠️ Limitations & Known Issues
Heat Map Availability
- Not available in API-only mode (requires browser automation)
- Fields
replay_heat,replay_max_score,replay_peakswill be empty - Trade-off: 74% faster performance without heat maps
Transcript Availability
- ~70-80% of videos have transcripts
- Age-restricted videos: transcript extraction fails
- Auto-generated captions may have errors
- Fallback chain: Supadata API → youtube-transcript library
API Quotas
- YouTube Data API: 10,000 units/day (hardcoded keys with rotation)
- Search costs 100 units, video details cost 1 unit per 50 videos
- Actor uses round-robin key rotation and 95% quota monitoring
- Automatic fallback to billing-enabled key when quota low
📖 Input Parameters Reference
| Parameter | Type | Default | Description |
|---|---|---|---|
startUrls | Array | [] | Video/channel/search URLs |
searchQuery | String | null | YouTube search query |
maxVideos | Integer | 50 | Max videos to analyze |
since | String (Date) | null | Publish date filter (after) |
until | String (Date) | null | Publish date filter (before) |
minViews | Integer | 0 | Minimum view count |
maxViews | Integer | null | Maximum view count |
durationFilter | Enum | any | Duration filter |
sortBy | Enum | relevance | Sort order |
maxHooksPerVideo | Integer | 10 | Max hooks per video |
hookLengthSec | Integer | 7 | Hook clip length (seconds) |
fetchTranscript | Boolean | true | Extract transcripts |
computeIntroPacing | Boolean | true | Analyze intro (first 15s) |
dryRun | Boolean | false | Metadata only (no analysis) |
Removed Parameters (now hardcoded):
youtubeApiKeysupadataApiKeyrespectApiOnlytranscriptSourceconcurrencyoutputFormatproxyConfiguration
🛠️ Troubleshooting
Issue: No heat map data extracted
Reason: Heat maps require browser automation (not available in API-only mode) Solution: This is expected. Actor prioritizes speed (2-3s per video) over heat maps.
Issue: No transcripts available
Reason: Video has captions disabled or is age-restricted
Solution: Check transcript.available field. Set fetchTranscript: false to skip.
Issue: No chapters found
Reason: Video description doesn't contain timestamp markers Solution: This is expected. Only ~30% of videos have description chapters.
Issue: Few hooks generated
Reason: No transcript or chapters available
Solution: Actor needs transcript or chapters to generate hooks. Check processing_notes.
📝 Examples
Example 1: Single Video Analysis
Example 2: Channel Analysis (Last 30 Days)
Example 3: Trend Research
Example 4: Shorts Batch Analysis
Example 5: Dry Run (Discovery Only)
🔧 Local Development
Setup
Edit Test Configuration
Edit INPUT.json with your test parameters:
Run Locally
Check Output
🚀 Deployment
Deploy to Apify
Note: API keys are hardcoded in the actor. No environment variables needed!
🤝 Support & Feedback
- Issues: Report bugs on GitHub Issues
- Feature Requests: Submit via GitHub Discussions
- Documentation: Full API docs at docs.apify.com
📜 License
ISC License - Free to use for commercial and personal projects
🏗️ Architecture
Built with:
- Apify SDK 3.4+ (Actor framework)
- YouTube Data API v3 (Video metadata)
- Supadata API (Transcript extraction)
- youtube-transcript (Fallback transcript source)
- axios (HTTP client)
Architecture Type: API-first (no browser automation)
Version: 1.0.0 Last Updated: November 2025
🎯 Performance Benchmarks
| Scenario | Videos | Time | Speed |
|---|---|---|---|
| Single video | 1 | 2.5s | 2.5s per video |
| Small batch | 10 | 25s | 2.5s per video |
| Medium batch | 50 | 115s (~2 min) | 2.3s per video |
| Large batch | 100 | 230s (~4 min) | 2.3s per video |
74% faster than previous Puppeteer-based approach (was 8.8s per video)