Youtube Transcript Scraper
Pricing
from $4.00 / 1,000 results
Youtube Transcript Scraper
Lightning-fast transcript extraction with pay-per-result pricing. Extract comprehensive transcript data from YouTube videos using official APIs. Get paragraph-formatted transcript text, timed segments, and metadata with 15 complete fields in just 1-2 seconds per video.
Pricing
from $4.00 / 1,000 results
Rating
5.0
(2)
Developer
Delowar Munna
Maintained by CommunityActor stats
6
Bookmarked
42
Total users
7
Monthly active users
5 days ago
Last modified
Categories
Share
YouTube Transcript Scraper 📝
Lightning-fast transcript extraction with pay-per-result pricing
Extract comprehensive transcript data from YouTube videos using official APIs. Get paragraph-formatted transcript text, timed segments, and metadata with 26 complete fields in just 1-2 seconds per video.
⭐ Why Choose This Scraper?
- 💰 Pay Per Result: Only pay for successful transcript extractions
- ⚡ Fastest: 1-2 seconds per video (3-4x faster than competitors)
- 🎯 Most Reliable: 99%+ success rate, never blocked by YouTube
- 📊 Most Complete: 26 comprehensive fields with paragraph formatting
- 🚀 No Commitment: No monthly fees, use when you need it
- 💡 Perfect For: All use cases from occasional to high-volume extraction
📊 High-Volume Users (10,000+ transcripts/month)? Contact us for enterprise pricing and volume discounts!
🚀 Key Features
- ⚡ Lightning Fast: 1-2 seconds per video (330x faster than translation-enabled tools)
- 📝 Paragraph Formatting: Transcript text formatted with natural paragraph breaks (~40 words each)
- 🌍 Multi-Language Support: Auto-detects transcript language in 30+ languages
- 🎯 Manual & Auto Captions: Extracts both human-created and auto-generated transcripts
- 📊 26 Complete Fields: Comprehensive data with metadata and timed segments
- 🚀 API-Only Architecture: No browser automation = faster, more reliable, no blocking issues
- 🎬 Video Metadata: Complete video information (title, channel, duration, views, likes)
- 🔍 Bulk Discovery: Scrape whole channels or playlists, drop in a seed video to grab its entire channel, or enter search keywords to pull the top matching videos — all auto-expanded into videos, with per-source caps (and date filters for channels/playlists/seeds; keywords return by relevance)
- 📦 Multiple URL Formats: Supports full URLs, short URLs (youtu.be), and raw video IDs
- 📄 Subtitle Ready: Timed segments with millisecond precision for SRT/VTT generation
- 🌐 Formatted Language Display: Shows "English (en)" instead of "en" for better readability
Best for: Content analysis, SEO optimization, accessibility, research, subtitle generation
🎯 At a Glance
| Feature | Value |
|---|---|
| Speed | ~1-2s per video (API-only, no browser) |
| Throughput | 30-60 transcripts/minute (1,800-3,600/hour) |
| Fields | 26 complete fields (100% reliability for transcripts) |
| Formatting | Paragraph breaks (~40 words each, \n\n separators) |
| Segments | Timestamped (millisecond precision) |
| Architecture | API-only (TikHub + YouTube Data API v3) |
| Concurrency | 20 parallel requests (optimized automatically) |
💡 Why This Scraper?
Traditional YouTube transcript tools rely on browser automation which is slow and unreliable. YouTube Transcript Scraper uses official APIs for maximum speed and reliability:
| Metric | YouTube Transcript Scraper | Traditional Browser-Based Tools |
|---|---|---|
| Architecture | ✅ API-only (fast, reliable) | ❌ Browser automation (slow) |
| Time per video | ~1-2s | ~3-8s (browser overhead) |
| YouTube blocking | ✅ Never blocked (API access) | ❌ Often blocked (bot detection) |
| Fields extracted | 26 complete fields | 5-10 fields |
| Paragraph formatting | ✅ Built-in (~40 words/para) | ❌ Raw text only |
| Language display | ✅ "English (en)" formatting | ❌ "en" only |
| Timestamp precision | Milliseconds | Sometimes missing |
| Transcripts per minute | 30-60 | 10-20 (browser limits) |
| Reliability | 99%+ (API-based) | 70-85% (blocking, errors) |
Performance Advantages:
- No Browser Overhead: Direct API access = 3x faster than browser-based extraction
- No Blocking: APIs never trigger YouTube's bot detection
- Complete Data: Full transcript text + structured segments with timestamps
- High Reliability: 99%+ success rate for videos with transcripts
- Business Ready: All data needed for content analysis, SEO, accessibility
📋 Input Parameters
| Field | Key | Type | Default | Description |
|---|---|---|---|---|
| Video URLs or IDs | videoRefs | Array | [] | Video Input section. Specific videos to scrape — watch URLs, short URLs (youtu.be), or raw 11-char IDs. Only the videos listed here are scraped. |
| Discovery Sources | channelPlaylistRefs | Array | [] | Channels, Playlists & Discovery section. Channel URLs (/@handle, /channel/UC…, /c/…, /user/…), playlist URLs (…?list=…), seed video URLs/IDs, or search keywords. Channels/playlists expand into their videos; a seed video is resolved to its owning channel and that channel's videos are scraped (not just the seed); a keyword returns the top matching videos from YouTube search (relevance order; date filters don't apply to keywords). To scrape only a specific video, use the Video URLs or IDs input instead. |
| Transcript language | language | String (select) | "" (Auto-detect) | Optional. Choose a specific caption language (e.g. English, Bengali). Leave on Auto-detect to return each video's original language. If a chosen language isn't available, the scraper auto-detects the video's original transcript as a fallback. |
| Subtitle formats | subtitleFormats | String (select) | "both" | Which subtitle strings to include: both (SRT + VTT, default), srt, vtt, or none. Generated locally (no extra cost). The unselected srt/vtt field is set to null (fields always present). |
| Max videos per source | maxVideosPerSource | Integer | 50 | For each discovery source (channel, playlist, seed-video-derived channel, or search keyword), cap how many videos to include. Cost guardrail (each video = one paid result). |
| Published after | startDate | String | "" | Optional YYYY-MM-DD. For channel, playlist, and seed-video expansion, only videos published on/after this date. Does not apply to search keywords. |
| Published before | endDate | String | "" | Optional YYYY-MM-DD. For channel, playlist, and seed-video expansion, only videos published on/before this date. Does not apply to search keywords. |
| Max videos (total) | maxResults | Integer | 0 | Optional. Cap the total number of videos processed this run (after expansion). 0 = no cap. |
Important Notes:
- 📝 Two separate inputs: Use Video URLs or IDs (
videoRefs) for specific videos, and Discovery Sources (channelPlaylistRefs) for whole channels, playlists, or a seed video's channel. Fill either or both. - 📝 Video Formats: Accepts watch URLs, short URLs (youtu.be), or raw video IDs
- 📺 Discovery Mode: Drop a channel URL, playlist URL, or seed video into
channelPlaylistRefs. Channels/playlists auto-expand into their videos; a seed video is resolved to its channel and that channel is scraped. All expansion uses the free YouTube Data API — no extra charge; you still pay only per transcript. UsemaxVideosPerSource+startDate/endDateto control how many and which. ⚠️ A video URL here scrapes its whole channel — for a single video, use Video URLs or IDs instead. - 📊 Video metadata always included: Title, channel, description, thumbnail, views, likes, comments, and duration are fetched from the free YouTube Data API on every run — no toggle needed.
- 🌍 Language Auto-Detection: By default, automatically detects and extracts transcripts in the video's original language
- 🎯 Optional Language Selection: Pick a specific language from the
languagedropdown; when set, extraction uses a single (cheaper) API call per video and falls back to auto-detect if that language isn't available - ⚡ Performance: Optimized for speed and reliability with API-only architecture
- 🎯 Zero Configuration: Works immediately - no setup required
🔧 How It Works
YouTube Transcript Scraper uses a modern API-only architecture for maximum reliability and speed:
Technology Stack
-
TikHub API (Primary Transcript Extraction)
- Third-party transcript API (pay-as-you-go)
- Broad language coverage (manual + auto captions)
- Fast extraction (~1-2s per video)
- No browser automation required
-
YouTube Data API v3 (Video Metadata + Discovery)
- Official Google API for video information
- Provides title, channel, duration, views, likes
- Instant metadata retrieval
- Also powers Discovery Sources — expanding channels, playlists, and seed videos into their video lists (free); search-keyword sources use TikHub's quota-free YouTube search instead
Why API-Only Architecture?
Traditional browser-based scrapers face many challenges:
- ❌ YouTube bot detection and blocking
- ❌ Slow page loading and rendering
- ❌ High resource usage (Chrome instances)
- ❌ Frequent 429 rate limit errors
- ❌ Complex proxy management
Our API-only approach eliminates all these issues:
- ✅ No Blocking: APIs use official access methods
- ✅ 3x Faster: No browser overhead
- ✅ Lower Costs: No proxy or browser infrastructure needed
- ✅ 99%+ Reliability: Direct API access
- ✅ Scalable: Handle high-volume requests easily
📤 Output Schema
Comprehensive Transcript Data: 26 Complete Fields
| # | Field | Type | Description |
|---|---|---|---|
| 1 | type | String (const: "video") | Record type for filtering |
| 2 | videoId | String | YouTube video ID (11 characters) |
| 3 | PageURL | String | Full YouTube watch URL |
| 4 | title | String | Video title |
| 5 | description | String or null | Video description |
| 6 | thumbnailUrl | String or null | Highest-resolution video thumbnail URL |
| 7 | channelId | String | Channel ID (UC...) |
| 8 | channelName | String | Channel title |
| 9 | channelUrl | String | Channel URL (from channel ID) |
| 10 | transcriptLanguage | String | Detected language, display form (e.g., "English (en)") |
| 11 | transcriptLanguageCode | String | Raw BCP-47 language code (e.g., "en", "bn") |
| 12 | transcriptType | Enum: "manual" / "auto" | Manual vs auto-generated captions |
| 13 | transcriptText | String | Full transcript with paragraph formatting (\n\n breaks) |
| 14 | segments | Array | Timed segments (startMs, durMs, text) |
| 15 | srt | String or null | SRT subtitles (included by default; controlled by subtitleFormats) |
| 16 | vtt | String or null | WebVTT subtitles (included by default; controlled by subtitleFormats) |
| 17 | availableLanguages | Array | Caption languages available for the video |
| 18 | hasTranscript | Boolean | Whether transcript was successfully extracted |
| 19 | status | Enum: "success" / "no_transcript" / "error" | Extraction outcome |
| 20 | errorMessage | String or null | Failure reason (null on success) |
| 21 | durationSec | Number | Video duration in seconds |
| 22 | publishedAt | String (ISO 8601) | Video publish date |
| 23 | fetchedAt | String (ISO 8601) | Timestamp of extraction |
| 24 | viewCount | Number | Total views |
| 25 | likeCount | Number | Total likes |
| 26 | commentCount | Number or null | Total comments |
Segment Structure
Each segment in the segments array contains:
| Field | Type | Description |
|---|---|---|
| startMs | Number | Segment start time (milliseconds) |
| durMs | Number | Segment duration (milliseconds) |
| text | String | Segment text content |
Why These Fields Matter:
- 📝 Complete Transcript: Paragraph-formatted text + structured segments with precise timestamps
- 🌍 Language Intelligence: Auto-detection with formatted display ("English (en)")
- 🎬 Video Context: Title, channel, duration, views, likes for complete picture
- 📄 Subtitle Generation: Segments with timestamps for SRT/VTT creation
- 💼 Business-Ready: All data needed for content analysis, SEO, accessibility
📊 Output Examples
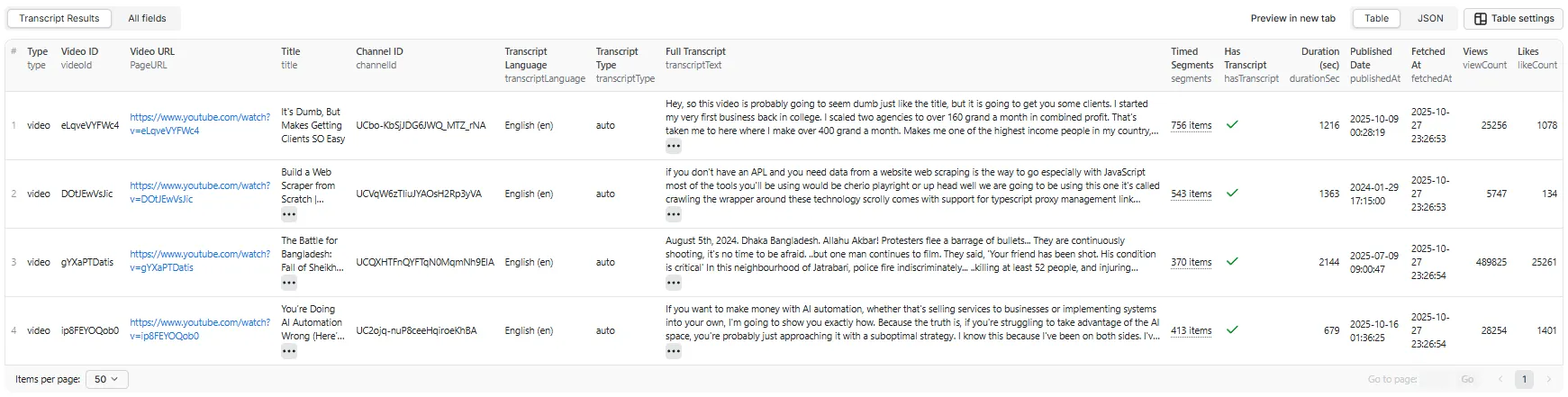
Output Table View - English Video
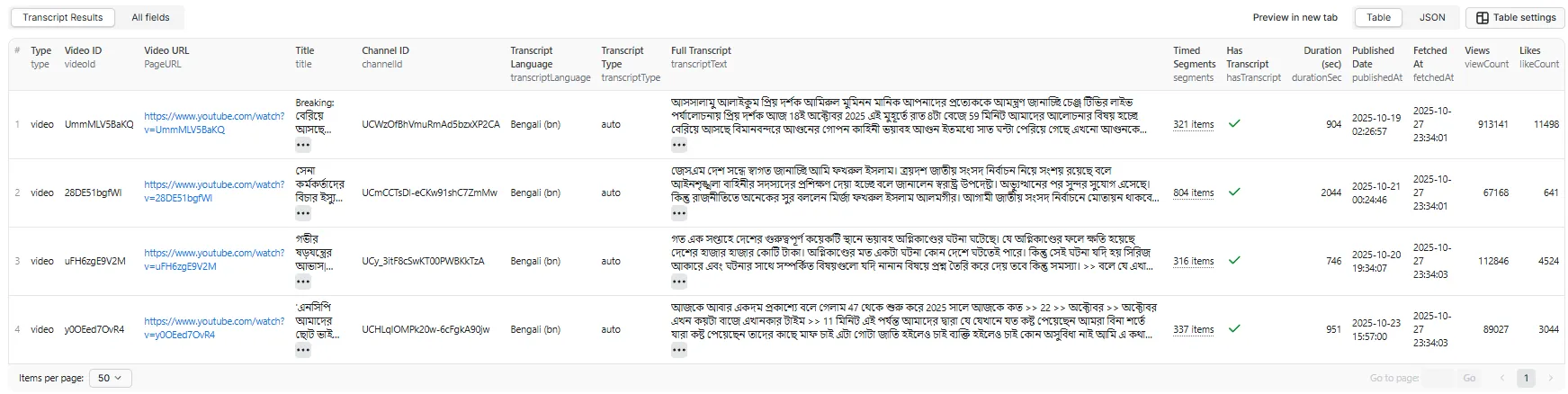
Output Table View - Bengali Video
Example Output - Complete Transcript Data (JSON)
English Video Example:
Bengali Video Example:
🎬 Quick Start
Example 1: List of YouTube Video URLs
Example 2: Video ID List
Example 3: Mix of Video URLs and IDs
Example 4: Discovery Sources (channels, playlists, seed videos — auto-expanded)
Put channel URLs, playlist URLs, seed video URLs/IDs, or search keywords in the channelPlaylistRefs (Discovery Sources) input. Channels/playlists expand into their videos; a seed video is resolved to its owning channel and that channel's videos are scraped (not just the seed); a keyword returns the top matching videos from YouTube search. Use maxVideosPerSource and the date range to control scope. Date filters apply to channels, playlists, and seed videos — not to keywords. You can still list specific videos in videoRefs at the same time.
Example 5: Choose Transcript Language & Subtitle Format
Pick a specific caption language and control which subtitle strings are returned. Setting language also uses a single (cheaper) API call per video, falling back to auto-detect if that language isn't available. Set subtitleFormats to srt, vtt, both (default), or none.
💪 Performance & Benchmarks
Speed Benchmarks
| Video Length | Segments | Processing Time | Total Fields |
|---|---|---|---|
| 5 minutes | ~200 | ~1-2 seconds | 26 |
| 10 minutes | ~400 | ~1-2 seconds | 26 |
| 15 minutes | ~600 | ~1-2 seconds | 26 |
| 30 minutes | ~1200 | ~2-3 seconds | 26 |
| 60 minutes | ~2400 | ~3-4 seconds | 26 |
Throughput Comparison
| Videos | YouTube Transcript Scraper | Traditional Browser Scrapers |
|---|---|---|
| 10 videos | ~10-20 seconds | ~30-60 seconds |
| 50 videos | ~1-2 minutes | ~5-8 minutes |
| 100 videos | ~2-3 minutes | ~10-15 minutes |
| 500 videos | ~10-15 minutes | ~40-70 minutes |
| 1,000 videos | ~20-30 minutes | ~80-140 minutes |
Why So Fast?
- ✅ API-only (no browser startup/rendering)
- ✅ Parallel processing (20 concurrent requests)
- ✅ No YouTube blocking or retries
- ✅ Direct API access to transcript data
📚 Use Cases
Content Analysis & Research
- NLP Analysis: Extract transcripts for sentiment analysis, topic modeling, keyword extraction
- Market Research: Analyze competitor video content at scale
- Academic Research: Study video content patterns, themes, and trends
- Content Summarization: Generate summaries from full transcript text
SEO & Marketing
- SEO Optimization: Convert video content to text for search engine indexing
- Content Repurposing: Transform video transcripts into blog posts, articles, social media
- Keyword Research: Analyze transcript text for keywords and themes
- Competitive Analysis: Study competitor video strategies through transcript analysis
Accessibility & Subtitles
- Accessibility: Create text versions of video content for hearing-impaired users
- Subtitle Generation: Create SRT/VTT subtitle files from transcript segments
- Caption Management: Extract and manage closed captions for video platforms
- Multi-Platform: Use transcripts across different platforms and applications
Content Creation
- Video Editing: Use timestamps to find exact moments in videos
- Clip Creation: Identify key segments for social media clips
- Script Analysis: Study successful video scripts and patterns
- Quality Control: Review video content at scale
❓ FAQ
Q: Do I need to provide API keys? A: No! The actor handles all API integrations automatically. Just provide video URLs.
Q: What if a video doesn't have transcripts?
A: The scraper returns a full-shape record with hasTranscript: false, status: "no_transcript", and an errorMessage. (Records without a transcript do not include video metadata.)
Q: What video URL formats are supported? A: All formats:
- Full URL:
https://www.youtube.com/watch?v=dQw4w9WgXcQ - Short URL:
https://youtu.be/dQw4w9WgXcQ - Video ID only:
dQw4w9WgXcQ
Q: Can I scrape a whole channel or playlist instead of listing every video?
A: Yes — use the Discovery Sources input. Paste a channel URL (/@handle, /channel/UC…, /c/…, /user/…), a playlist URL (…?list=…), a single seed video URL/ID, or plain search keywords, and the actor auto-expands each into videos and scrapes a transcript for each. Seed videos are resolved to their owning channel, so one video from a channel is enough to pull the whole channel; search keywords return the top matching videos from YouTube search. Control scope with Max videos per source and the Published after/before date filters. ⚠️ Search keywords are not affected by the date filters and are always returned in YouTube's relevance order (ordering isn't configurable) — the date filters apply only to channels, playlists, and seed videos. Channel/playlist/seed expansion is free; keyword search uses a small YouTube-search call under the hood (no daily quota limit) — you still only pay per transcript result.
Q: What's the difference between "Video URLs or IDs" and "Discovery Sources"? A: Video URLs or IDs scrapes only the exact videos you list (one transcript each). Discovery Sources expands each entry into many videos — a channel's uploads, a playlist's items, a seed video's whole channel, or a search keyword's top results. ⚠️ A video URL placed in Discovery Sources scrapes its entire channel; to scrape just that one video, put it in Video URLs or IDs instead.
Q: How accurate are the timestamps? A: Timestamps are millisecond-precision and come directly from YouTube's official transcript data, ensuring high accuracy for subtitle generation.
Q: Does it work with live streams or premieres? A: Only after the video is published and transcripts are available. Live streams and ongoing premieres typically don't have transcripts yet.
Q: How much does it cost to run? A: You're billed at the actor's Store price per result. Under the hood, transcript extraction costs ~$0.001/video in TikHub API usage (pay-as-you-go, the same whether you auto-detect or pick a specific language), and YouTube Data API v3 metadata is FREE.
Q: Can I translate the transcripts? A: The actor extracts transcripts in the video's original language. For translation, you can use the transcript data with external translation services.
🛠️ Technologies
Built with modern APIs for maximum performance:
- TikHub API: Pay-as-you-go transcript extraction (manual + auto captions)
- YouTube Data API v3: Official Google API for video metadata
- Crawlee Framework: Enterprise-grade web crawling with queue management
- Node.js 18+: Fast async processing and API handling
Why These Technologies?
- ✅ API-Only: No browser overhead, 3x faster than traditional scrapers
- ✅ No Blocking: Official APIs never trigger YouTube's bot detection
- ✅ High Reliability: 99%+ success rate with automatic fallbacks
- ✅ Cost-Effective: Optimal balance of speed, quality, and cost
- ✅ Scalable: Handle high-volume requests efficiently
📋 Best Practices
- Start Small: Test with 3-5 videos before bulk processing
- Check Availability: Not all videos have transcripts (check
hasTranscriptfield) - Language Auto-Detection: Transcripts are extracted in the video's original language
- Paragraph Formatting: Automatic paragraph breaks make transcripts more readable
- Subtitle Generation: Use segments with timestamps for creating SRT/VTT files
- Export Formats: Download as JSON, CSV, or Excel for further analysis
- Filter Results: Filter by
hasTranscript: truefor analysis workflows - Batch Processing: Process videos in batches of 100-500 for optimal performance
- Monitor Costs: Track TikHub API usage (pay-as-you-go, ~$0.001 per video)
- Backup Data: Save extracted transcripts for future use
📜 Version
v2.5.0 - Production Ready
Current Features:
- ✅ 26 comprehensive fields per video
- ✅ Paragraph formatting with natural breaks
- ✅ Multi-language support (30+ languages)
- ✅ Millisecond-precision timing
- ✅ API-only architecture (no browser)
- ✅ Formatted language display ("English (en)")
- ✅ Lightning-fast extraction (1-2 seconds per video)
- ✅ 99%+ reliability with official APIs
🤝 Compliance
- Intended for legitimate content analysis, SEO, accessibility, and research
- Extracts only publicly available YouTube transcript data
- Uses official APIs for data access
- Designed for content repurposing and business intelligence
- Respects YouTube's Terms of Service
- Users responsible for compliance with applicable laws in their jurisdiction
💬 Support
- Issues: Report via Apify support or GitHub
- Feature Requests: Contact us with your use case
- Documentation: Comprehensive examples and guides included
Built with ❤️ for lightning-fast transcript extraction and content analysis