European Commission Scraper
Pricing
from $4.00 / 1,000 results
European Commission Scraper
Scrape the European Commission Press Corner, and extract press releases, statements, speeches, and background briefings on everything from tech regulation and defence to climate policy. Set your filters on the website, paste the URL, and let the scraper extract up to 150 full articles.
Pricing
from $4.00 / 1,000 results
Rating
0.0
(0)
Developer
Marco Rodrigues
Maintained by CommunityActor stats
0
Bookmarked
2
Total users
1
Monthly active users
7 days ago
Last modified
Categories
Share
🇪🇺 European Commission News Scraper
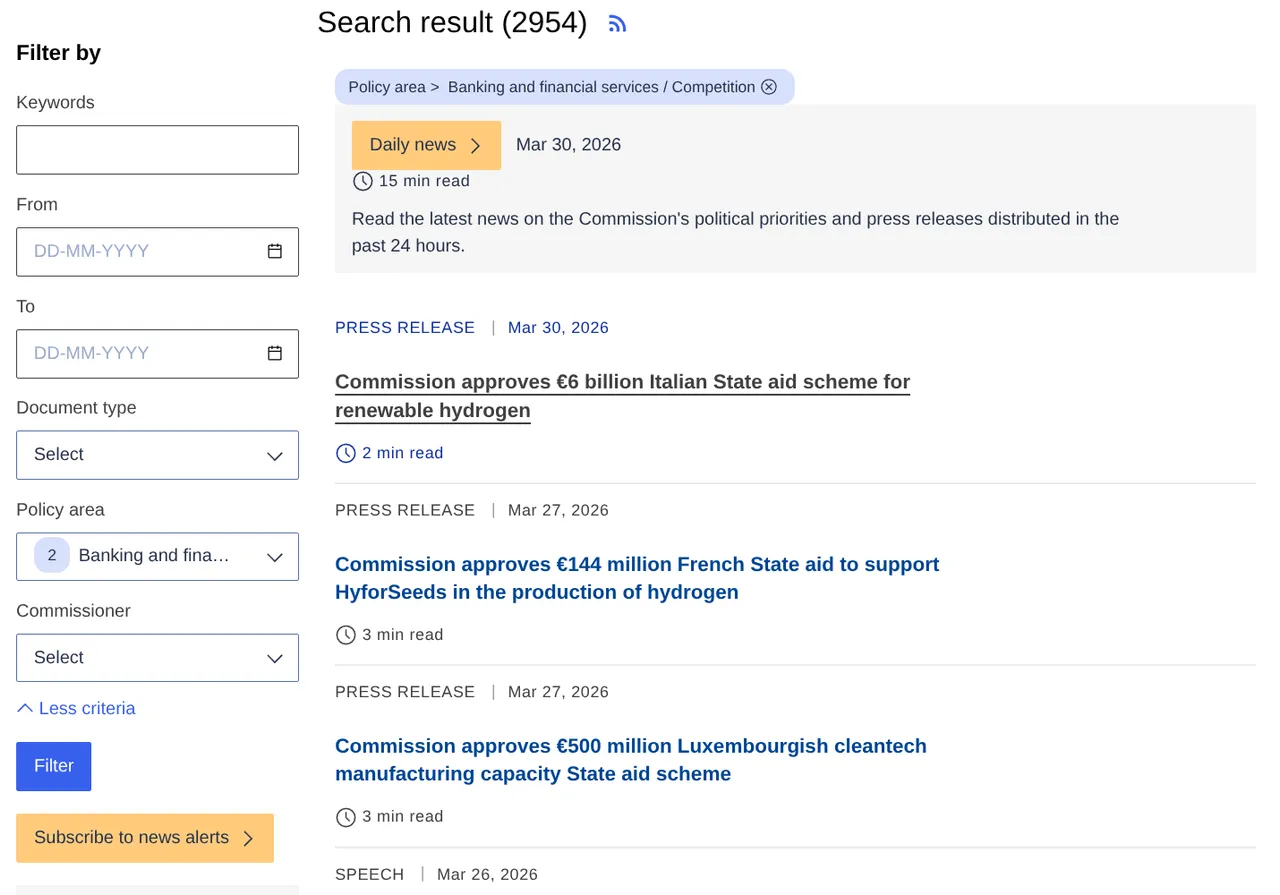
Official EU policy news moves fast. The European Commission Press corner publishes press releases, statements, speeches, and briefings on regulation, climate, funding, defence, and more.
This actor turns those pages into structured data. Apply filters on the website, paste the URL, set how many items you want (up to 250), and get titles, full text, PDF links, and press contacts.
💡 Perfect for…
- Regulatory & compliance teams: Capture official wording and PDF documents for audit trails.
- Newsrooms & journalists: Track announcements by theme or commissioner and quote official text.
- Public affairs: Monitor dossiers and share structured updates with stakeholders.
- 📚 RAG & research: Index
contentso tools can answer what the Commission said — with citations.
✨ Why you'll love this scraper
- 🎯 Paste your filtered search: Start from any Press corner URL after you filter in the browser.
- 📄 PDF links included: Captures the downloadable PDF when available.
- 👤 Press contacts: Name and phone number when listed on the page.
- 📰 Full body text: Headline, date, document type, and article content.
📦 What's inside the data?
| Field | Description |
|---|---|
url | Press corner detail URL |
title | Headline |
category | Document type (e.g. Press release, Statement, Speech) |
date | Publication date as shown on the page |
content | Full body text |
content_pdf | URL to the official PDF (when available) |
contact_name | Press contact name |
contact_number | Press contact phone |
🚀 Quick start
- Open the Press corner and apply any filters you want.
- Copy the browser URL and paste it into
input_url. (Leave the default to scrape the latest general feed.) - Set
max_articles(up to 250). - Click Start and export JSON, CSV, or Excel.
Example input
Example output
| Parameter | Type | Required | Description |
|---|---|---|---|
input_url | string | No | Press corner URL after filters (or the default latest feed). |
max_articles | integer | No | How many items to collect. Min 10, max 250, default 100. |