Apotea Product Search Scraper
Pricing
$20.00/month + usage
Apotea Product Search Scraper
Discover how to extract product data from Apotea.se, Sweden's largest online pharmacy, with this powerful scraper. Collect product names, prices, images, SKUs and more from over 40,000 health and beauty items for competitive analysis, market research, and price monitoring.
Pricing
$20.00/month + usage
Rating
0.0
(0)
Developer
ecomscrape
Maintained by CommunityActor stats
0
Bookmarked
3
Total users
0
Monthly active users
9 months ago
Last modified
Categories
Share
Contact
If you encounter any issues or need to exchange information, please feel free to contact us through the following link: My profile
Apotea.se Scraper: Extract Swedish Pharmacy Product Data Efficiently
Introduction: Why Scrape Apotea.se?
Apotea is Sweden's largest online pharmacy with over 40,000 products including both prescription and over-the-counter medications, along with thousands of health, beauty, and wellness products. The platform has been voted Sweden's favorite online store multiple times, making it a critical data source for anyone interested in the Swedish healthcare and e-commerce markets.
For market researchers, price comparison platforms, competitors, and data analysts, accessing structured product information from Apotea.se presents unique opportunities. The pharmacy sector is one of the fastest-growing e-commerce industries globally, and understanding product availability, pricing trends, and inventory patterns can provide valuable business intelligence. However, manually collecting this data from thousands of product pages is impractical and time-consuming.
This is where the Apotea.se Product Search Scraper becomes essential. It automates the data extraction process, allowing you to gather comprehensive product information efficiently and at scale.
Overview: Powerful Data Extraction for Swedish Pharmacy Products
The Apotea.se Product Search Scraper is designed to systematically extract product information from search result pages and category listings on Apotea.se. This tool enables you to collect structured data from multiple product pages simultaneously, transforming unstructured web content into actionable datasets.
Key Features and Advantages
This scraper offers several powerful capabilities that make it ideal for various use cases:
- Batch Processing: Extract data from multiple category pages or search results in a single operation
- Proxy Integration: Built-in residential proxy support ensures reliable access without detection
- Scalable Collection: Configure the number of items to extract per URL based on your needs
- Error Resilience: Automatic retry mechanism handles temporary connection issues
- Structured Output: Returns clean, organized data in JSON format ready for analysis
Who Should Use This Scraper?
This tool is valuable for:
- Market Researchers: Analyze product trends and category patterns in the Swedish pharmacy market
- Price Monitoring Services: Track pricing changes across thousands of health and beauty products
- E-commerce Competitors: Understand product assortment and positioning strategies
- Data Analysts: Build datasets for pharmaceutical market analysis and consumer behavior studies
- Business Intelligence Teams: Monitor inventory availability and product launches
Input Configuration Explained
Example url 1: https://www.apotea.se/ansiktsvatten?sort=name%20asc
Example url 2: https://www.apotea.se/necessarer
Example url 3: https://www.apotea.se/resa?p=2
Example Screenshot of product list by query page:
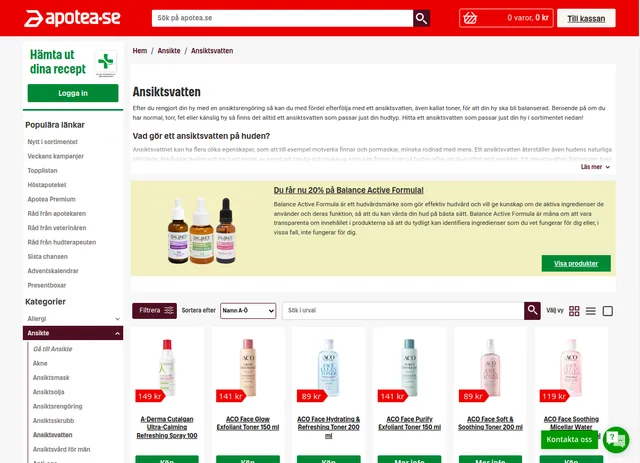
Input Format
The scraper accepts configuration through a JSON object with several key parameters:
Scrape with URLs:
The urls parameter: List of product list page URLs that you want to scrape. You can add URLs one by one, or use the Bulk edit section to add a prepared list.
The ignore_url_failures parameter: If set to true, the scraper will continue running even if some URLs fail to be scraped after reaching the maximum number of retries. This ensures that one problematic URL doesn't stop your entire scraping job.
When you provide a list of URLs for scraping, all options in the "Scrape with search filters" section will be disabled. The system will only collect data from the URLs you specified.
Scrape with Search Filters:
The keyword parameter: The search keyword to find products (e.g., "vitamin", "skincare", "shampoo").
The sort_by parameter: Sort items by various criteria:
"rank asc"- Popularity (most popular first)"created desc"- News (newest first)"name asc"- Name A-Z"name desc"- Name Z-A"price asc"- Lowest Price"price desc"- Highest Price"comp_price asc"- Lowest Compare Price"comp_price desc"- Highest Compare Price
The page parameter: Starting page number for scraping, useful for continuing interrupted scrapes or targeting specific result ranges.
When using search filters for scraping, you need to leave the urls field empty (or set it to null) in the "Scrape with URLs" configuration.
General Options:
The max_items_per_url parameter: Limits the number of items extracted from each product list page or search results page. The default value is 20, providing a manageable batch size while allowing for comprehensive data collection.
The max_retries_per_url parameter: Sets the maximum number of retry attempts for each URL or search filters if the scrape is detected as a bot or the page fails to load. The default value is 2, providing a good balance between thoroughness and efficiency.
The proxy parameter: Proxy configuration is essential for maintaining anonymity and avoiding detection. The residential proxy option ensures that your scraping activities appear as legitimate browsing, reducing the risk of being blocked or rate-limited. You should choose a country that matches the location of the website you're scraping (e.g., Sweden for apotea.se).
Input Requirements and Limitations
- All URLs must be from the apotea.se domain
- URLs should point to product listing or search result pages, not individual product pages
- The scraper processes these listings to extract individual product information
Comprehensive Output Data Structure
You get the output from the apotea.se Property Search Scraper stored in a tab. The following is an example of the Information Fields collected after running the Actor.
Output Fields Explained
ID (String)
- What it is: The unique internal identifier Apotea uses for this product
- Purpose: Serves as a primary key for database storage and tracking
- Use cases:
- Avoiding duplicate entries when updating your database
- Tracking the same product over time for price history
- Linking to other datasets or APIs that reference Apotea products
- Example: "1234567" uniquely identifies one specific product
Name (String)
- What it is: The complete product name including brand, product type, and size
- Purpose: Human-readable product identification
- Use cases:
- Display in price comparison interfaces
- Search and filtering functionality
- Product categorization and classification
- Matching products across different platforms
- Example: "CeraVe Foaming Facial Cleanser 473ml" tells you the brand (CeraVe), type (Foaming Facial Cleanser), and size (473ml)
Image (String - URL)
- What it is: Direct CDN link to the product's main image
- Purpose: Visual representation of the product
- Use cases:
- Displaying products in your interface or catalog
- Creating visual price comparison tools
- Building product galleries or recommendation systems
- Training machine learning models for product categorization
- Format: Full HTTPS URL pointing to Apotea's CDN
- Example: Images are typically high-quality (XL size) suitable for display
URL (String - URL)
- What it is: The direct link to the product's detail page on Apotea.se
- Purpose: Source attribution and access to complete product information
- Use cases:
- Creating clickable links in comparison tools
- Attribution and compliance with terms of service
- Accessing additional information not included in the scrape
- Verifying data accuracy
- Example: Each URL leads directly to the product's page where users can purchase
Price (String - Numeric)
- What it is: The current selling price of the product
- Format: Decimal number as string (e.g., "189.00")
- Purpose: Core pricing information for analysis
- Use cases:
- Price monitoring and trend analysis
- Competitive pricing intelligence
- Building price comparison platforms
- Calculating average market prices by category
- Identifying pricing patterns and promotional periods
- Note: Convert to float/decimal for mathematical operations
Currency (String)
- What it is: The currency code for the price
- Purpose: Contextualizes the price field
- Use cases:
- Currency conversion calculations
- Multi-market analysis
- Ensuring correct price interpretation
- Value: Typically "SEK" (Swedish Krona) for Apotea.se
- Example: "SEK" indicates all prices are in Swedish Krona
SKU (String)
- What it is: Stock Keeping Unit - the product's internal inventory code
- Purpose: Alternative product identifier used for inventory management
- Use cases:
- Cross-referencing products in inventory systems
- Tracking product variants (different sizes, formulations)
- Integration with warehouse and fulfillment systems
- Identifying product families and variants
- Example: "CERA-473-FOA" might indicate CeraVe, 473ml size, Foaming formula
Data Quality and Completeness
All fields are extracted when available on the product listing. Occasionally, certain fields may be empty if the information isn't displayed on the listing page:
- Missing images might return an empty string or placeholder
- Prices should always be present for active products
- SKUs are typically available for inventory tracking
How to Use the Scraper: Step-by-Step Guide
Successfully extracting data from Apotea.se involves several straightforward steps:
Step 1: Identify Target Categories
Before scraping, determine which product categories or search results you need. Browse Apotea.se to find relevant category URLs. Examples include:
- Skincare categories: facial cleansers, moisturizers, serums
- Personal care: cosmetics bags, travel essentials
- Health products: vitamins, supplements, first aid
Step 2: Configure Your Input
Create your JSON configuration with appropriate parameters:
- Set
max_items_per_urlbased on category size (start with 20 for testing) - Configure proxy settings with country "SE" for best results
- Add all target URLs to the
urlsarray - Set
max_retries_per_urlto 2 for reliable extraction
Step 3: Run the Scraper
Execute the scraper with your configuration. The process typically takes a few minutes depending on the number of URLs and items requested.
Step 4: Process and Analyze Results
Once complete, you'll receive a JSON array containing all extracted products. You can:
- Import into a database for storage and querying
- Convert to CSV for spreadsheet analysis
- Feed into analytics tools or dashboards
- Use for automated price monitoring systems
Best Practices and Tips
Optimize Your Scraping Strategy:
- Start with a small subset of URLs to test your configuration
- Use appropriate
max_items_per_urlvalues - don't request more data than you need - Schedule regular scraping runs to track changes over time rather than one-time bulk extraction
Handle Rate Limiting:
- Always use residential proxies to avoid blocks
- Set reasonable retry limits (2-3 maximum)
- Space out large scraping jobs if extracting from many categories
Ensure Data Quality:
- Validate extracted data before using it in production systems
- Check for missing or null values in critical fields
- Monitor for changes in website structure that might affect extraction
Common Issues and Solutions:
- Empty results: Verify URLs are correct and point to listing pages, not individual products
- Proxy errors: Ensure proxy configuration is correct and you have sufficient proxy credits
- Timeout failures: Reduce
max_items_per_urlor increasemax_retries_per_url - Inconsistent data: Some product listings may have incomplete information; filter your results accordingly
Benefits and Real-World Applications
Time and Resource Efficiency
Manual data collection from thousands of products would require hundreds of hours. This scraper completes the same task in minutes, freeing your team to focus on analysis and strategy rather than data gathering. A single run can extract information from hundreds or thousands of products that would take days to collect manually.
Business Applications
Competitive Intelligence: Monitor competitor pricing strategies and product assortments. Identify gaps in your own product offering or opportunities for better positioning.
Market Research: Analyze trends in the Swedish pharmacy and health products market. Track which product categories are growing, identify emerging brands, and understand seasonal patterns.
Price Monitoring: Build automated systems that track price changes across categories. Alert your team when competitors adjust prices or launch promotions, enabling rapid competitive response.
Inventory Planning: Understand product availability patterns and stock levels. Identify frequently out-of-stock items that might indicate high demand.
Data-Driven Decision Making: Use structured product data to support strategic decisions about market entry, product selection, or pricing strategies.
Integration Possibilities
The structured JSON output integrates seamlessly with:
- Business intelligence platforms (Tableau, Power BI)
- Database systems (PostgreSQL, MongoDB)
- Analytics frameworks (Python pandas, R)
- Custom dashboards and monitoring systems
- Automated alerting and notification systems
Conclusion: Transform Web Data into Business Intelligence
The Apotea.se Product Search Scraper transforms unstructured web content into actionable business intelligence. By automating the extraction of product information from Sweden's largest online pharmacy, you gain access to valuable market data that would otherwise require significant manual effort to collect.
Whether you're conducting competitive analysis, monitoring prices, researching market trends, or building data-driven applications, this scraper provides the foundation for informed decision-making. The structured output format ensures your data is immediately usable for analysis, visualization, or integration into existing systems.
Ready to start extracting valuable product data from Apotea.se? Configure your input parameters, specify your target categories, and let the scraper do the heavy lifting while you focus on deriving insights from the data.
Related Actors
- Apotea.se Product Details Scraper: A specialized data extraction tool engineered to harvest detailed product information from apotea's product marketplace.
Your feedback
We are always working to improve Actors' performance. So, if you have any technical feedback about apotea.se Property Search Scraper or simply found a bug, please create an issue on the Actor's Issues tab in Apify Console.