Gelbe Seiten Business Search Scraper
Pricing
$15.00/month + usage
Gelbe Seiten Business Search Scraper
Gelbeseiten.de Business Search Scraper automates German business data extraction, transforming weeks of manual research into hours. Extract company names, contacts, addresses, ratings from Germany's leading directory. Perfect for market research, sales prospecting, competitive analysis.
Pricing
$15.00/month + usage
Rating
0.0
(0)
Developer
ecomscrape
Maintained by CommunityActor stats
0
Bookmarked
24
Total users
0
Monthly active users
5 months ago
Last modified
Categories
Share
Contact
If you encounter any issues or need to exchange information, please feel free to contact us through the following link: My profile
Guide (English version)
Gelbeseiten.de Business Search Scraper - Executive Summary
Introduction
Gelbeseiten.de serves as Germany's primary business directory and phone book, providing comprehensive information about companies across all industries. For businesses engaged in B2B sales, market research, or lead generation, accessing this vast repository of German business data manually is time-consuming and inefficient. As Germany's most comprehensive yellow pages directory, Gelbe Seiten offers consumers a wide range of digital services, making it an invaluable resource for data extraction.
The Gelbeseiten.de Business Search Scraper addresses the critical need for automated data collection from this platform, enabling businesses to systematically extract valuable business intelligence without manual effort. This tool transforms hours of manual research into minutes of automated data gathering, providing structured access to Germany's extensive business landscape.
Scraper Overview
The Gelbeseiten.de Business Search Scraper is a sophisticated data extraction tool designed specifically for automated business information retrieval from Germany's premier business directory. This scraper efficiently navigates through business listings, extracting comprehensive company data while respecting website protocols and maintaining data accuracy.
Key advantages include automated proxy rotation to prevent detection, configurable extraction limits, and structured output formats suitable for immediate business use. The scraper is particularly valuable for sales teams conducting market research, businesses seeking competitor analysis, or marketing agencies building targeted prospect lists for the German market.
The tool is designed for professionals who need reliable, scalable access to German business data, including sales professionals, market researchers, business development teams, and digital marketing agencies focusing on the German business landscape.
Input and Output Details
Example url 1: https://www.gelbeseiten.de/suche/restaurants/berlin
Example url 2: https://www.gelbeseiten.de/suche/busbetriebe/bundesweit
Example url 3: https://www.gelbeseiten.de/suche/suchtmedizin/bundesweit
Example Screenshot of business information page:
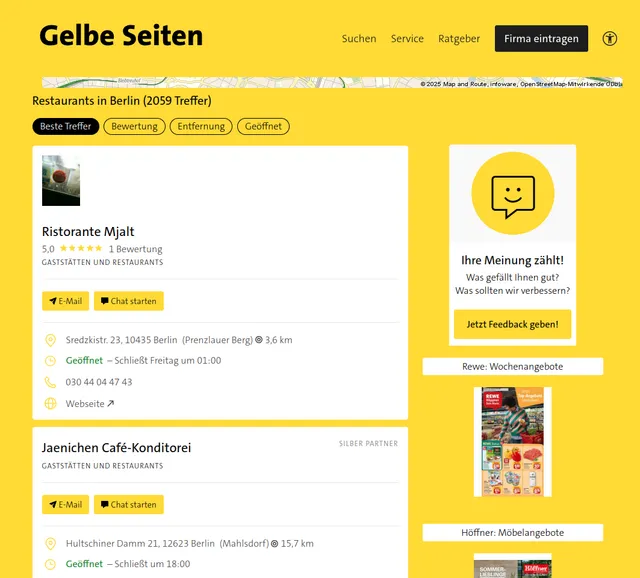
Input Format
The scraper accepts configuration through a JSON object with several key parameters:
Scrape with URLs:
The urls parameter: List of business listing page URLs that you want to scrape. You can add URLs one by one, or use the Bulk edit section to add a prepared list.
The ignore_url_failures parameter: If set to true, the scraper will continue running even if some URLs fail to be scraped after reaching the maximum number of retries. This ensures that one problematic URL doesn't stop your entire scraping job.
When you provide a list of URLs for scraping, all options in the "Scrape with search filters" section will be disabled. The system will only collect data from the URLs you specified.
Scrape with Search Filters:
The keyword parameter: The search keyword to find businesses (e.g., "restaurants", "ärzte", "hotels", "apotheke").
The region parameter: Enter the location to search for businesses. You can use:
- City names (e.g., "Berlin", "München", "Hamburg")
- Postal codes (e.g., "10115", "80331")
- Specific addresses or districts
The radius parameter: Specify the search radius in meters from the specified location:
- 5000 - 5 km radius
- 10000 - 10 km radius
- 20000 - 20 km radius
- Custom values can be set based on your needs
When using search filters for scraping, you need to leave the urls field empty (or set it to null) in the "Scrape with URLs" configuration.
General Options:
The max_items_per_url parameter: Limits the number of business listings extracted from each listing page or search results page. The default value is 20, providing a manageable batch size while allowing for comprehensive data collection.
The max_retries_per_url parameter: Sets the maximum number of retry attempts for each URL or search filters if the scrape is detected as a bot or the page fails to load. The default value is 2, providing a good balance between thoroughness and efficiency.
The proxy parameter: Proxy configuration is essential for maintaining anonymity and avoiding detection. The residential proxy option ensures that your scraping activities appear as legitimate browsing, reducing the risk of being blocked or rate-limited. You should choose a country that matches the location of the website you're scraping (e.g., Germany/DE for gelbeseiten.de).
Output Format
You get the output from the Gelbeseiten.de Business Search Scraper stored in a tab. The following is an example of the Information Fields collected after running the Actor.
The scraper returns structured business data in the following format:
Business Data Fields:
- ID: Unique identifier for each business listing, essential for data deduplication and database management
- URL: Direct link to the business's Gelbeseiten.de profile page for verification and additional information access
- Name: Official business name as registered on the platform, crucial for lead identification and outreach
- Logo: Business logo image URL when available, valuable for visual identification and presentation materials
- Rating: Customer satisfaction score, typically on a 5-point scale, indicating service quality and reputation
- Total Ratings: Number of customer reviews, providing context for rating reliability and business popularity
- Business Field: Industry category or sector classification, enabling targeted market segmentation
- Email: Contact email address for direct business communication and lead nurturing campaigns
- Phone: Primary contact number for immediate outreach and qualification calls
- Website: Official business website URL for comprehensive company research and digital presence analysis
- Address: Complete physical location including street, city, and postal code for local market analysis
- Open Hours: Operating schedule information crucial for timing outreach efforts and understanding business availability
This structured output enables immediate integration into CRM systems, email marketing platforms, and sales databases.
Usage Instructions
Step 1: Choose Your Scraping Approach
Option A - Prepare Target URLs: Identify specific Gelbeseiten.de search pages by navigating to the website and using the search and filtering features. Search for your target business category and location. Copy the complete resulting search page URLs with all parameters.
Option B - Use Search Filters: Define your search criteria using the built-in filters:
- Set
keywordfor specific business types (e.g., "restaurants", "ärzte", "hotels") - Enter
regionto target specific locations (city names, postal codes, or districts) - Set
radius(in meters) to define the search area around the location (e.g., 5000 for 5 km, 10000 for 10 km)
Step 2: Configure Parameters
Set appropriate retry limits (recommended: 2-3 via max_retries_per_url), enable proxy usage with German (DE) residential proxies for optimal performance, and adjust item limits (max_items_per_url) based on your data needs (20-50 items per URL typically optimal). Enable ignore_url_failures for robust scraping.
Step 3: Execute Extraction Input your configuration and monitor the scraping process. The tool will automatically handle pagination and data extraction while respecting rate limits.
Step 4: Data Processing Review extracted data for completeness and accuracy. The structured output can be directly imported into Excel, Google Sheets, or business databases.
Best Practices:
Method Selection:
- Use URL-based scraping for complex searches with multiple filters or specific category targeting
- Use filter-based scraping for simple keyword and location searches
- Combine both approaches: use filters for broad business discovery, then URLs for targeted extraction
Scraping Strategy:
- Use specific location-based searches for higher relevance
- Always use German (DE) residential proxies for best access and geographic accuracy
- Implement reasonable delays between requests
- Regularly validate contact information accuracy for optimal campaign results
Filter Optimization:
- Location Strategy: Use specific cities or postal codes in
regionfor targeted local searches - Radius Strategy:
- Use 5000 meters (5 km) for neighborhood-level searches
- Use 10000 meters (10 km) for city district searches
- Use 20000 meters (20 km) for broader regional searches
- Keyword Strategy: Use specific German business terms for better results (e.g., "italienische restaurants" instead of just "restaurants")
Advanced Filter Combinations:
- Local restaurants:
keyword: "restaurants", region: "10115", radius: 5000(Berlin postal code with 5 km radius) - City-wide doctors:
keyword: "ärzte", region: "München", radius: 10000 - Regional hotels:
keyword: "hotels", region: "Hamburg", radius: 20000 - Specific services:
keyword: "apotheke", region: "Köln", radius: 5000
Common Issues:
Empty Results:
- For filter-based: Verify keyword spelling in German
- Try broader
radiusvalues if location seems too specific - Test with larger cities or well-known postal codes
- Ensure business category exists in the specified region
Location Format Issues:
- Use German city names (e.g., "München" not "Munich")
- Postal codes should be 5 digits (e.g., "10115")
- Try different location formats if one doesn't work
Radius Configuration:
- Radius is specified in meters (not kilometers)
- Common values: 5000 (5km), 10000 (10km), 20000 (20km)
- Larger radius = more results but less location precision
Proxy Issues:
- Always use German (DE) proxies for gelbeseiten.de
- Enable
ignore_url_failuresto handle temporary connection issues - Increase
max_retries_per_urlto 3-5 if experiencing frequent timeouts
Use Cases:
- Local Business Research: Use small radius (5000m) with specific postal codes
- City-wide Analysis: Use medium radius (10000m) with city names
- Regional Market Research: Use large radius (20000m) for broader coverage
- Competitive Analysis: Compare business density across different regions using consistent radius values
Benefits and Applications
Time Efficiency: Automates manual research that would typically require hours or days, reducing data collection time by up to 95% compared to manual methods.
Business Applications: Ideal for B2B sales prospecting, competitive analysis, market entry research, and local business partnership identification. Sales teams can build comprehensive prospect databases quickly, while marketing agencies can develop targeted campaigns based on geographic and industry segmentation.
Data Accuracy: Provides structured, consistent data formatting that eliminates manual transcription errors and ensures standardized information across all records.
Scalability: Capable of processing multiple search queries and thousands of business records efficiently, making it suitable for both small-scale research and enterprise-level data collection projects.
Conclusion
The Gelbeseiten.de Business Search Scraper represents an essential tool for any business requiring systematic access to German market data. By automating the extraction of comprehensive business information from Germany's leading directory, this scraper enables efficient market research, lead generation, and competitive analysis. Transform your German business intelligence gathering today with this powerful, reliable scraping solution.
Einführung (deutsche Version)
Gelbeseiten.de Business Search Scraper – Zusammenfassung für Führungskräfte
Einführung
Gelbeseiten.de dient als Deutschlands führendes Unternehmensverzeichnis und Telefonbuch und bietet umfassende Informationen zu Unternehmen aus allen Branchen. Für Unternehmen, die im B2B-Vertrieb, in der Marktforschung oder bei der Lead-Generierung tätig sind, ist der manuelle Zugriff auf dieses umfangreiche deutsche Unternehmensdaten-Repository zeitaufwändig und ineffizient. Als Deutschlands umfassendstes Branchenverzeichnis bietet Gelbe Seiten Verbrauchern eine breite Palette digitaler Services und stellt somit eine wertvolle Ressource für die Datenerfassung dar.
Der Gelbeseiten.de Business Search Scraper erfüllt das wichtige Bedürfnis einer automatisierten Datenerfassung von dieser Plattform und ermöglicht es Unternehmen, wertvolle Geschäftsdaten systematisch und ohne manuellen Aufwand zu extrahieren. Dieses Werkzeug verwandelt stundenlange manuelle Recherche in wenige Minuten automatisierter Datensammlung und bietet strukturierten Zugriff auf die umfangreiche Unternehmenslandschaft Deutschlands.
Überblick über den Scraper
Der Gelbeseiten.de Business Search Scraper ist ein fortschrittliches Datenextraktions-Tool, das speziell für die automatisierte Gewinnung von Unternehmensdaten aus Deutschlands führendem Branchenverzeichnis entwickelt wurde. Dieser Scraper navigiert effizient durch Unternehmenslisten, extrahiert umfassende Firmendaten unter Beachtung der Webseitenprotokolle und stellt dabei die Datenqualität sicher.
Wichtige Vorteile sind automatisierte Proxy-Rotation zur Vermeidung von Erkennung, konfigurierbare Extraktions-Limits und strukturierte Ausgabedateien, die direkt im Geschäftsalltag nutzbar sind. Der Scraper ist besonders wertvoll für Vertriebsteams bei der Marktforschung, Unternehmen zur Wettbewerbsanalyse oder Marketingagenturen, die gezielte Interessentenlisten für den deutschen Markt aufbauen möchten.
Das Tool richtet sich an professionelle Anwender, die zuverlässigen und skalierbaren Zugang zu deutschen Unternehmensdaten benötigen, darunter Vertriebsprofis, Marktforscher, Teams für Geschäftsentwicklung und Digitalagenturen mit Fokus auf den deutschen Geschäftsmarkt.
Eingabe- und Ausgabedetails
Beispiel-URL: https://www.gelbeseiten.de/suche/restaurants/berlin
Beispiel-Screenshot einer Unternehmensinformationsseite:
Eingabeformat
Der Scraper akzeptiert die Konfiguration über ein JSON-Objekt mit mehreren wichtigen Parametern:
Scrapen mit URLs:
Der urls Parameter: Liste der Geschäftsverzeichnis-URLs, die Sie scrapen möchten. Sie können URLs einzeln hinzufügen oder den Bereich "Massenbearbeitung" verwenden, um eine vorbereitete Liste hinzuzufügen.
Der ignore_url_failures Parameter: Wenn auf true gesetzt, läuft der Scraper weiter, auch wenn einige URLs nach Erreichen der maximalen Anzahl von Wiederholungsversuchen nicht gescrapt werden können. Dies stellt sicher, dass eine problematische URL Ihren gesamten Scraping-Job nicht stoppt.
Wenn Sie eine Liste von URLs zum Scrapen bereitstellen, werden alle Optionen im Bereich "Scrapen mit Suchfiltern" deaktiviert. Das System sammelt nur Daten von den von Ihnen angegebenen URLs.
Scrapen mit Suchfiltern:
Der keyword Parameter: Der Suchbegriff zum Finden von Unternehmen (z.B. "restaurants", "ärzte", "hotels", "apotheke").
Der region Parameter: Geben Sie den Standort für die Suche nach Unternehmen ein. Sie können verwenden:
- Stadtnamen (z.B. "Berlin", "München", "Hamburg")
- Postleitzahlen (z.B. "10115", "80331")
- Spezifische Adressen oder Stadtteile
Der radius Parameter: Geben Sie den Suchradius in Metern vom angegebenen Standort an:
- 5000 - 5 km Radius
- 10000 - 10 km Radius
- 20000 - 20 km Radius
- Benutzerdefinierte Werte können je nach Bedarf festgelegt werden
Bei Verwendung von Suchfiltern zum Scrapen müssen Sie das Feld urls leer lassen (oder auf null setzen) in der Konfiguration "Scrapen mit URLs".
Allgemeine Optionen:
Der max_items_per_url Parameter: Begrenzt die Anzahl der Unternehmenseinträge, die von jeder Auflistungsseite oder Suchergebnisseite extrahiert werden. Der Standardwert ist 20, was eine überschaubare Stapelgröße bietet und gleichzeitig eine umfassende Datensammlung ermöglicht.
Der max_retries_per_url Parameter: Legt die maximale Anzahl von Wiederholungsversuchen für jede URL oder Suchfilter fest, wenn der Scrape als Bot erkannt wird oder die Seite nicht geladen werden kann. Der Standardwert ist 2, was ein gutes Gleichgewicht zwischen Gründlichkeit und Effizienz bietet.
Der proxy Parameter: Die Proxy-Konfiguration ist wesentlich für die Wahrung der Anonymität und die Vermeidung von Erkennung. Die Option für Residential Proxys stellt sicher, dass Ihre Scraping-Aktivitäten als legitimes Browsen erscheinen, wodurch das Risiko einer Sperrung oder Ratenbegrenzung verringert wird. Sie sollten ein Land wählen, das dem Standort der Website entspricht, die Sie scrapen (z.B. Deutschland/DE für gelbeseiten.de).
Ausgabeformat
Sie erhalten die Ausgabe des Gelbeseiten.de Business Search Scraper als tabellarisch gespeicherte Daten. Nachfolgend ein Beispiel der erfassten Informationsfelder nach Ausführung des Actors.
Der Scraper liefert strukturierte Firmendaten im folgenden Format:
Business Data Fields:
- ID: Eindeutige Kennung für jeden Firmeneintrag, wichtig zur Dublettenerkennung und für das Datenbankmanagement
- URL: Direkter Link zum Firmenprofil auf Gelbeseiten.de, für Verifizierung und weiteren Informationszugriff
- Name: Offizieller Firmenname wie auf der Plattform registriert, unerlässlich zur Lead-Identifizierung und Ansprache
- Logo: Bild-URL des Firmenlogos, sofern vorhanden – wertvoll für visuelle Zuordnung und Präsentationsunterlagen
- Bewertung (Rating): Kundenzufriedenheits-Score, in der Regel auf einer 5-Punkte-Skala, spiegelt Servicequalität und Ruf wider
- Gesamtbewertungen (Total Ratings): Anzahl der Kundenrezensionen, gibt Kontext zur Verlässlichkeit der Bewertungen und zur Popularität
- Branche (Business Field): Branchenkategorie oder Sektor, ermöglicht gezielte Marktsegmentierung
- E-Mail: Kontaktadresse zur direkten Kontaktaufnahme und für Lead Nurturing Kampagnen
- Telefon: Hauptkontakt-Nummer für sofortige Ansprache und Qualifizierung
- Webseite: Offizielle Firmenwebseite zur umfassenden Recherche und Analyse der digitalen Präsenz
- Adresse: Komplette Anschrift einschließlich Straße, Stadt und Postleitzahl für lokale Marktanalysen
- Öffnungszeiten (Open Hours): Informationen zum Betriebszeitplan, wichtig für die zeitliche Planung der Ansprache und zur Einschätzung der Erreichbarkeit
Diese strukturierte Ausgabe ermöglicht die direkte Integration in CRM-Systeme, E-Mail-Marketing-Plattformen und Vertriebsdatenbanken.
Gebrauchsanweisung
Schritt 1: Wählen Sie Ihren Scraping-Ansatz
Option A - Ziel-URLs vorbereiten: Identifizieren Sie spezifische Gelbeseiten.de-Suchseiten, indem Sie auf die Website navigieren und die Such- und Filterfunktionen verwenden. Suchen Sie nach Ihrer Ziel-Geschäftskategorie und Ihrem Standort. Kopieren Sie die vollständigen resultierenden Suchseiten-URLs mit allen Parametern.
Option B - Suchfilter verwenden: Definieren Sie Ihre Suchkriterien mithilfe der integrierten Filter:
- Setzen Sie
keywordfür bestimmte Geschäftstypen (z.B. "restaurants", "ärzte", "hotels") - Geben Sie
regionein, um bestimmte Standorte anzusprechen (Stadtnamen, Postleitzahlen oder Stadtteile) - Setzen Sie
radius(in Metern), um den Suchbereich um den Standort herum zu definieren (z.B. 5000 für 5 km, 10000 für 10 km)
Schritt 2: Parameter konfigurieren
Setzen Sie geeignete Wiederholungslimits (empfohlen: 2-3 über max_retries_per_url), aktivieren Sie die Proxy-Nutzung mit deutschen (DE) Residential Proxys für optimale Leistung und passen Sie die Elementlimits (max_items_per_url) basierend auf Ihrem Datenbedarf an (20-50 Elemente pro URL sind typischerweise optimal). Aktivieren Sie ignore_url_failures für robustes Scraping.
Schritt 3: Extraktion ausführen Geben Sie Ihre Konfiguration ein und überwachen Sie den Scraping-Prozess. Das Tool verarbeitet automatisch die Paginierung und Datenextraktion unter Beachtung der Ratenlimits.
Schritt 4: Datenverarbeitung Überprüfen Sie die extrahierten Daten auf Vollständigkeit und Genauigkeit. Die strukturierte Ausgabe kann direkt in Excel, Google Sheets oder Unternehmensdatenbanken importiert werden.
Best Practices:
Methodenauswahl:
- Verwenden Sie URL-basiertes Scraping für komplexe Suchen mit mehreren Filtern oder spezifischer Kategorieausrichtung
- Verwenden Sie filterbasiertes Scraping für einfache Stichwort- und Standortsuchen
- Kombinieren Sie beide Ansätze: Verwenden Sie Filter für breite Geschäftsentdeckung, dann URLs für gezielte Extraktion
Scraping-Strategie:
- Verwenden Sie spezifische standortbasierte Suchen für höhere Relevanz
- Verwenden Sie immer deutsche (DE) Residential Proxys für besten Zugang und geografische Genauigkeit
- Implementieren Sie angemessene Verzögerungen zwischen Anfragen
- Validieren Sie regelmäßig die Genauigkeit der Kontaktinformationen für optimale Kampagnenergebnisse
Filter-Optimierung:
- Standortstrategie: Verwenden Sie spezifische Städte oder Postleitzahlen in
regionfür gezielte lokale Suchen - Radius-Strategie:
- Verwenden Sie 5000 Meter (5 km) für Suchen auf Stadtteil-Ebene
- Verwenden Sie 10000 Meter (10 km) für Stadtbezirkssuchen
- Verwenden Sie 20000 Meter (20 km) für breitere regionale Suchen
- Stichwort-Strategie: Verwenden Sie spezifische deutsche Geschäftsbegriffe für bessere Ergebnisse (z.B. "italienische restaurants" statt nur "restaurants")
Erweiterte Filterkombinationen:
- Lokale Restaurants:
keyword: "restaurants", region: "10115", radius: 5000(Berliner Postleitzahl mit 5 km Radius) - Stadtweite Ärzte:
keyword: "ärzte", region: "München", radius: 10000 - Regionale Hotels:
keyword: "hotels", region: "Hamburg", radius: 20000 - Spezifische Dienstleistungen:
keyword: "apotheke", region: "Köln", radius: 5000
Häufige Probleme:
Leere Ergebnisse:
- Für filterbasiert: Überprüfen Sie die Rechtschreibung des Stichworts auf Deutsch
- Versuchen Sie breitere
radius-Werte, wenn der Standort zu spezifisch erscheint - Testen Sie mit größeren Städten oder bekannten Postleitzahlen
- Stellen Sie sicher, dass die Geschäftskategorie in der angegebenen Region existiert
Standortformat-Probleme:
- Verwenden Sie deutsche Stadtnamen (z.B. "München" nicht "Munich")
- Postleitzahlen sollten 5-stellig sein (z.B. "10115")
- Probieren Sie verschiedene Standortformate aus, wenn eines nicht funktioniert
Radius-Konfiguration:
- Radius wird in Metern angegeben (nicht in Kilometern)
- Gängige Werte: 5000 (5km), 10000 (10km), 20000 (20km)
- Größerer Radius = mehr Ergebnisse, aber weniger Standortpräzision
Proxy-Probleme:
- Verwenden Sie immer deutsche (DE) Proxys für gelbeseiten.de
- Aktivieren Sie
ignore_url_failures, um temporäre Verbindungsprobleme zu handhaben - Erhöhen Sie
max_retries_per_urlauf 3-5, wenn häufige Timeouts auftreten
Anwendungsfälle:
- Lokale Geschäftsrecherche: Verwenden Sie kleinen Radius (5000m) mit spezifischen Postleitzahlen
- Stadtweite Analyse: Verwenden Sie mittleren Radius (10000m) mit Stadtnamen
- Regionale Marktforschung: Verwenden Sie großen Radius (20000m) für breitere Abdeckung
- Wettbewerbsanalyse: Vergleichen Sie die Geschäftsdichte über verschiedene Regionen hinweg mit konsistenten Radius-Werten
Vorteile und Einsatzgebiete
Zeiteffizienz: Automatisiert eine sonst stunden- oder tagelange Recherche. Die Datensammlung erfolgt so bis zu 95% schneller als manuell.
Geschäftsanwendungen: Ideal für B2B-Leadgenerierung, Wettbewerbsanalyse, Markteintrittsstudien und Identifikation lokaler Unternehmenschancen. Vertriebsteams erstellen im Handumdrehen umfassende Prospekt-Datenbanken, Marketingagenturen entwickeln zielgerichtete Kampagnen basierend auf geografischer und branchenspezifischer Segmentierung.
Datenqualität: Liefert strukturierte, einheitlich formatierte Datensätze, vermeidet Übertragungsfehler und sorgt für Standardisierung über alle Einträge hinweg.
Skalierbarkeit: Kann effizient mehrere Suchanfragen und tausende Firmeneinträge verarbeiten, geeignet für kleine Projekte ebenso wie für großangelegte unternehmensweite Datenerhebung.
Fazit
Der Gelbeseiten.de Business Search Scraper ist ein essentieller Helfer für alle Unternehmen, die systematisch auf Marktdaten aus Deutschland zugreifen wollen. Durch die Automatisierung der Extraktion umfassender Unternehmensinformationen aus Deutschlands führendem Branchenverzeichnis ermöglicht der Scraper effiziente Marktforschung, Leadgenerierung und Wettbewerbsanalyse. Starten Sie noch heute mit der gezielten Erfassung deutscher Firmendaten – mit dieser leistungsstarken und zuverlässigen Scraping-Lösung!
Related Actors
- Gelbeseiten.de Business Details Scraper: Your comprehensive tool for extracting valuable business information from Gelbeseiten extensive directory platform.
Your feedback
We are always working to improve Actors' performance. So, if you have any technical feedback about Gelbeseiten.de Business Search Scraper or simply found a bug, please create an issue on the Actor's Issues tab in Apify Console.