Google Scholar Search Scraper
Pricing
$20.00/month + usage
Google Scholar Search Scraper
Extract comprehensive academic data from Google Scholar including research papers, citations, author information, and PDF links. Automate your literature review process with advanced scraping capabilities for researchers and academics.
Pricing
$20.00/month + usage
Rating
0.0
(0)
Developer
ecomscrape
Maintained by CommunityActor stats
0
Bookmarked
24
Total users
0
Monthly active users
a year ago
Last modified
Categories
Share
Contact
If you encounter any issues or need to exchange information, please feel free to contact us through the following link: My profile
Google Scholar Scraper: Extract Academic Data Efficiently
Introduction
Google Scholar provides a simple way to broadly search for scholarly literature, searching across many disciplines and sources including articles, theses, books, abstracts and court opinions from academic publishers, professional societies, online repositories, and universities. For researchers, academics, and data analysts, manually collecting this vast amount of scholarly information can be incredibly time-consuming and inefficient.
The Google Scholar Scraper addresses this challenge by automating the extraction of academic data from Google Scholar's extensive database. Whether you're conducting a systematic literature review, analyzing research trends, or building academic datasets, this scraper eliminates the tedious manual process of copying and pasting research information, allowing you to focus on analysis rather than data collection.
Overview of Google Scholar Scraper
The Google Scholar Scraper is a powerful data extraction tool designed specifically for academic researchers and professionals who need to collect large volumes of scholarly information efficiently. Google Scholar scraping enables automated data extraction including scholarly articles, citations, author information, publication years, and more, allowing researchers to quickly get large amounts of information.
This scraper stands out for its ability to handle complex search queries, navigate through pagination automatically, and extract structured data that's ready for analysis. The tool is particularly valuable for researchers conducting meta-analyses, systematic reviews, or bibliometric studies where comprehensive data collection is crucial.
Target Users:
- Academic researchers and graduate students
- Data scientists working with academic datasets
- Literature review specialists
- Bibliometric analysts
- Research institutions and libraries
- Market research companies analyzing academic trends
Input and Output Details
Example url 1: https://scholar.google.com/scholar?start=80&q=webscraping&hl=vi&as_sdt=0,5&as_ylo=2025
Example url 2: https://scholar.google.com/scholar?hl=vi&as_sdt=0%2C5&as_ylo=2025&q=llm&btnG=
Example url 3: https://scholar.google.com/scholar?hl=vi&as_sdt=0%2C5&as_ylo=2025&q=AI&btnG=
Example Screenshot of scholary information page:
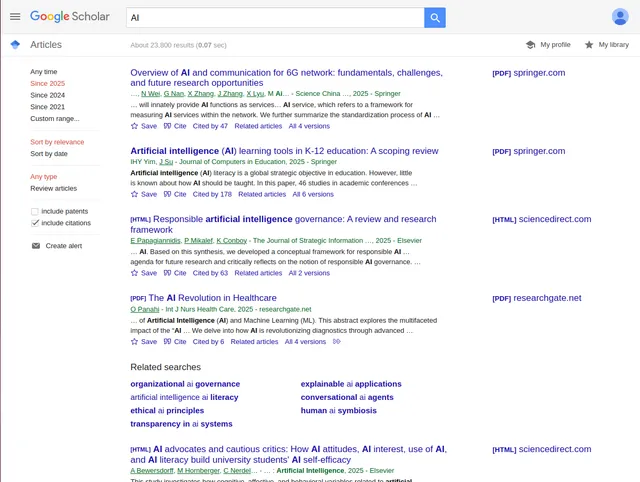
Input Format
The scraper accepts JSON configuration with several key parameters:
Input:
Key Input Parameters:
- max_retries_per_url: Controls the number of retry attempts for each URL, ensuring reliable data extraction
- proxy settings: Essential for avoiding bot detection and maintaining consistent access to Google Scholar
- max_items_per_url: Limits the number of results per search query to manage resource usage
- urls: Direct Google Scholar search result URLs with specific queries and filters
Output Format
You get the output from the Google Scholary Search Scraper stored in a tab. The following is an example of the Information Fields collected after running the Actor.
The scraper returns structured data with the following fields, each serving specific research purposes:
Core Output Fields:
- ID: Unique identifier for each academic paper, crucial for database management and avoiding duplicates
- Title: Complete paper title, essential for citation management and reference building
- Description: Abstract or summary text, providing quick content overview for relevance assessment
- URL: Direct link to the full paper or publisher page, enabling immediate access to source material
- PDF URL: Direct download link when available, facilitating full-text analysis and archival
- Displayed Link: The formatted citation link as shown on Google Scholar, useful for proper academic referencing
- Related Link: Links to related works, valuable for discovering connected research and expanding literature reviews
- Version Link: Links to different versions of the same paper, helping track paper evolution and find the most current version
- Citations: Citation count data, critical for impact analysis and identifying influential papers
How to Use the Google Scholar Scraper
Step-by-Step Guide
-
Configure Search Parameters: Set up your JSON input with specific search queries, proxy settings, and limits based on your research needs
-
Set Up Proxy Configuration: Use residential proxies from appropriate geographic locations to ensure reliable access and avoid rate limiting
-
Define Search URLs: Create targeted Google Scholar search URLs with specific keywords, date ranges, and filters relevant to your research topic
-
Monitor Extraction Process: Track the scraping progress and handle any potential errors or retries automatically
-
Process Output Data: Import the structured JSON output into your preferred analysis tools or databases
Best Practices
- Query Optimization: Use specific, well-defined search terms to get more relevant results and reduce noise in your dataset
- Rate Limiting: Configure appropriate delays and retry limits to maintain good relationship with Google Scholar's servers
- Data Validation: Always verify a sample of extracted data for accuracy before proceeding with large-scale analysis
- Incremental Processing: For large datasets, process data in batches to avoid overwhelming system resources
Common Error Handling
The scraper includes robust error handling for common issues such as network timeouts, blocked requests, and parsing errors. The retry mechanism ensures data collection continuity even when facing temporary access restrictions.
Benefits and Applications
Time and Resource Savings
The scraper enables access to large volumes of academic data including publication titles, authors, citation counts, publication years, and abstracts, which is particularly useful for researchers, analysts, and developers. This automation can reduce literature review time from weeks to hours.
Real-World Applications
- Systematic Literature Reviews: Quickly gather comprehensive paper collections for meta-analyses
- Research Trend Analysis: Track emerging topics and citation patterns across academic disciplines
- Competitive Intelligence: Monitor research activities in specific fields or institutions
- Academic Database Building: Create curated datasets for machine learning and text analysis projects
- Grant Proposal Research: Identify relevant prior work and citation opportunities for funding applications
Business Value
Research institutions can leverage this tool to enhance their research productivity, while publishers and academic service providers can use it to build comprehensive academic databases and recommendation systems.
Conclusion
The Google Scholar Scraper transforms the traditionally manual and time-intensive process of academic data collection into an efficient, automated workflow. By providing structured access to Google Scholar's vast repository of scholarly literature, researchers can focus on analysis and insight generation rather than data gathering.
Ready to accelerate your research process? Start extracting valuable academic data today and discover how automation can enhance your literature review and research capabilities.
Your feedback
We are always working to improve Actors' performance. So, if you have any technical feedback about Google Scholar Scholary Search Scraper or simply found a bug, please create an issue on the Actor's Issues tab in Apify Console.

