Infojobs Jobs Search Scraper
Pricing
$20.00/month + usage
Infojobs Jobs Search Scraper
Automate job data collection from InfoJobs.net, Spain's leading employment portal with over 3 million professionals. Extract comprehensive job listings including salaries, contract types, company details, and location data for market analysis, recruitment automation, and competitive intelligence.
Pricing
$20.00/month + usage
Rating
0.0
(0)
Developer
ecomscrape
Maintained by CommunityActor stats
0
Bookmarked
12
Total users
0
Monthly active users
8 months ago
Last modified
Categories
Share
Contact
If you encounter any issues or need to exchange information, please feel free to contact us through the following link: My profile
InfoJobs.net Job Scraper: Extract Spain's Job Market Data Efficiently
Introduction: Unlocking Spain's Premier Job Market Data
InfoJobs is the largest and most successful online job search platform in Europe, operating primarily in Spain with over 2.8 million CVs and 35,000 companies. For recruiters, market analysts, job aggregators, and HR professionals, accessing this vast repository of employment data can provide invaluable insights into Spain's job market trends, salary benchmarks, and hiring patterns.
However, manually collecting job listings from InfoJobs.net is time-consuming and inefficient, especially when tracking multiple job categories, locations, or monitoring market changes over time. This is where the InfoJobs.net Job Scraper becomes essential—automating the extraction of detailed job information at scale while maintaining data accuracy and structure.
Scraper Overview: Comprehensive Job Data Extraction
The InfoJobs.net Job Scraper is a professional-grade data extraction tool designed to systematically collect detailed job posting information from InfoJobs.net. This scraper navigates through job search result pages and extracts complete job details including position information, company data, compensation details, and employment conditions.
Key Capabilities:
- Automated extraction from multiple search result pages simultaneously
- Proxy rotation support to ensure uninterrupted data collection
- Configurable retry mechanisms for reliable data capture
- Structured output format ready for analysis and integration
- Batch processing with customizable limits per URL
Ideal For:
- Recruitment Agencies: Building comprehensive job databases and identifying hiring trends
- Market Research Analysts: Tracking salary ranges, contract types, and industry demands
- Job Aggregation Platforms: Populating databases with Spanish market opportunities
- HR Departments: Competitive intelligence and compensation benchmarking
- Career Advisors: Understanding job market landscape for client guidance
Input Configuration Explained
Example Screenshot of jobs list by query page:
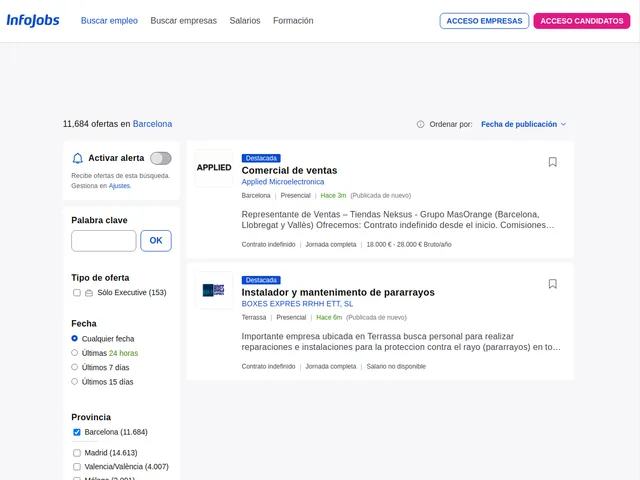
Input Format
The scraper accepts configuration through a JSON object with several key parameters:
Scrape with URLs:
The urls parameter: List of job list page URLs that you want to scrape. You can add URLs one by one, or use the Bulk edit section to add a prepared list.
The ignore_url_failures parameter: If set to true, the scraper will continue running even if some URLs fail to be scraped after reaching the maximum number of retries. This ensures that one problematic URL doesn't stop your entire scraping job.
When you provide a list of URLs for scraping, all options in the "Scrape with search filters" section will be disabled. The system will only collect data from the URLs you specified.
Scrape with Search Filters:
The keyword parameter: The search keyword to find jobs (e.g., "software engineer", "marketing manager", "accountant").
The sort_by parameter: Sort jobs by various criteria:
"PUBLICATION_DATE"- Publication date (newest first)"RELEVANCE"- Relevance (most relevant first)
The since_date parameter: Filter jobs by posting date:
"ANY"- Any time"_24_HOURS"- 24 hours ago"_7_DAYS"- 7 days ago"_15_DAYS"- 15 days ago
The only_foreign_country parameter: If set to true, the scraper will scrape jobs from other countries only (jobs outside Spain).
The page parameter: Starting page number for scraping, useful for continuing interrupted scrapes or targeting specific result ranges.
When using search filters for scraping, you need to leave the urls field empty (or set it to null) in the "Scrape with URLs" configuration.
General Options:
The max_items_per_url parameter: Limits the number of job listings extracted from each job list page or search results page. The default value is 20, providing a manageable batch size while allowing for comprehensive data collection.
The max_retries_per_url parameter: Sets the maximum number of retry attempts for each URL or search filters if the scrape is detected as a bot or the page fails to load. The default value is 2, providing a good balance between thoroughness and efficiency.
The proxy parameter: Proxy configuration is essential for maintaining anonymity and avoiding detection. The residential proxy option ensures that your scraping activities appear as legitimate browsing, reducing the risk of being blocked or rate-limited. You should choose a country that matches the location of the website you're scraping (e.g., Spain for infojobs.net).
Comprehensive Output Data Structure
You get the output from the infojobs.net Jobs Search Scraper stored in a tab. The following is an example of the Information Fields collected after running the Actor.
Output Fields Explained
Code (string, unique identifier)
- Purpose: Unique job posting identifier assigned by InfoJobs
- Usage: Track specific listings, avoid duplicates, create reference links
- Example: "7893456"
Title (string)
- Purpose: Job position name/title
- Usage: Job categorization, keyword analysis, matching candidates to positions
- Example: "Senior Software Engineer" or "Marketing Manager"
Description (string, full HTML or text)
- Purpose: Complete job description including responsibilities, requirements, and benefits
- Usage: Detailed analysis, skills extraction, job requirement matching
- Note: May contain HTML formatting tags
City (string)
- Purpose: Specific city or municipality where the job is located
- Usage: Geographic analysis, location-based filtering, commute planning
- Example: "Barcelona", "Madrid", "Valencia"
URL (string, full job posting link)
- Purpose: Direct link to the original job posting on InfoJobs.net
- Usage: User redirection, verification, accessing full details not captured
- Example: "https://www.infojobs.net/offer/of12345678..."
Contract Type (string)
- Purpose: Employment contract category
- Usage: Job stability analysis, contract type distribution studies
- Common values: "Indefinido" (permanent), "Temporal", "Freelance", "Prácticas" (internship)
Salary (string)
- Purpose: Compensation information when disclosed
- Usage: Salary benchmarking, compensation analysis, market rate research
- Format: May include ranges, "A convenir" (negotiable), or specific amounts
- Example: "30.000€ - 40.000€ bruto/año"
Workday (string)
- Purpose: Work schedule type
- Usage: Work-life balance analysis, schedule preference filtering
- Common values: "Completa" (full-time), "Parcial" (part-time), "Indiferente"
Teleworking (string/boolean)
- Purpose: Remote work availability
- Usage: Remote work trend analysis, filtering remote opportunities
- Values: Indicates if position offers remote, hybrid, or on-site work only
Published At (date/timestamp)
- Purpose: Job posting publication date and time
- Usage: Freshness sorting, trend analysis, job posting velocity tracking
- Format: ISO date format or InfoJobs timestamp
Company Name (string)
- Purpose: Hiring company's name (may be anonymized by some employers)
- Usage: Employer analysis, company hiring activity tracking, reputation research
- Example: "Tech Solutions SL" or "Confidencial"
Company Link (string, URL)
- Purpose: Link to company profile page on InfoJobs
- Usage: Company information research, employer branding analysis
- Note: May be null for confidential postings
States (string/array)
- Purpose: Autonomous communities or regions where job is available
- Usage: Regional market analysis, multi-location job identification
- Example: "Cataluña", "Comunidad de Madrid"
Upsellings (array/object)
- Purpose: Premium features purchased by employer for the listing
- Usage: Understanding employer investment level, priority job identification
- Examples: Featured placement, highlighted listing, urgent tags
Executive (boolean)
- Purpose: Indicates if position is executive/management level
- Usage: Filtering senior roles, executive market analysis, leadership opportunity tracking
How to Use the Scraper: Step-by-Step Guide
Step 1: Choose Your Scraping Approach
Option A - URL-Based Scraping: Navigate to InfoJobs.net and create search queries with your desired filters (keywords, location, job category, date range). Copy the complete URLs from your browser after applying filters.
Option B - Filter-Based Scraping: Use the built-in search filters to automatically generate search queries:
- Define your search
keyword(e.g., "software engineer", "marketing") - Select
sort_bycriteria (publication date or relevance) - Set
since_dateto filter by posting date (24 hours, 7 days, 15 days, or any) - Toggle
only_foreign_countryif you want jobs from other countries - Specify the starting
pagenumber
Step 2: Configure Input Parameters
For URL-Based Scraping:
Create your JSON input with the collected URLs in the urls array. Leave filter parameters empty or null.
For Filter-Based Scraping:
Set up your configuration with search parameters (keyword, sort_by, since_date, etc.). Leave the urls field empty or set it to null.
Configure appropriate proxy settings. For scraping Spanish jobs, consider using Spanish (ES) or European proxies for better results.
Step 3: Set Extraction Limits
Determine how many jobs you need per search page or URL (max_items_per_url). For comprehensive market research, set higher limits (50-100). For quick snapshots, 20-50 items per URL is sufficient.
Step 4: Execute and Monitor
Run the scraper and monitor progress. The retry mechanism will handle temporary failures automatically. Enable ignore_url_failures to ensure one failed URL or search query doesn't stop your entire job.
Step 5: Process Output Data
Export data in your preferred format (JSON, CSV, Excel) for analysis, database integration, or further processing.
Best Practices:
- Choose the right method: Use URL-based scraping for complex, multi-filter queries; use filter-based scraping for simpler, keyword-driven searches
- Refine your filters: When using filter-based scraping, start broad and narrow down based on results
- Use appropriate date filters: Set
since_dateto focus on recent job postings and avoid outdated listings - Test before scaling: Start with a small
max_items_per_urlto verify your configuration works correctly - Handle pagination: For URL-based scraping, include pagination URLs; for filter-based, use the
pageparameter to continue from where you left off
Best Practices
- Use Residential Proxies: RESIDENTIAL proxy type provides better success rates than datacenter proxies
- Respect Rate Limits: Add appropriate delays between requests to avoid overwhelming the server
- Update URLs Regularly: Search result URLs may expire; regenerate them periodically
- Verify Data Quality: Spot-check extracted records against source pages to ensure accuracy
- Handle Null Values: Some fields (like salary, company name) may be empty for certain listings
- Time Your Scraping: Run during off-peak hours for better performance and lower detection risk
Common Issues and Solutions
Problem: Low success rate or blocked requests Solution: Switch to RESIDENTIAL proxies and ensure proxy country matches target region (Spain/EU)
Problem: Missing or incomplete data fields Solution: Some employers don't disclose all information (salary, company name). This is expected behavior.
Problem: URLs returning no results Solution: Verify the search URL works manually in a browser. InfoJobs may have updated their URL structure.
Benefits and Real-World Applications
Time Efficiency
Manual job data collection from InfoJobs would require hours of copying and pasting. This scraper automates the entire process, collecting hundreds or thousands of job listings in minutes, allowing your team to focus on analysis rather than data gathering.
Business Applications
Recruitment Intelligence: Build comprehensive databases of available positions, track which companies are hiring in specific sectors, and identify talent pools in different regions.
Compensation Research: Aggregate salary data across industries, positions, and locations to create accurate compensation benchmarks for your organization or clients.
Market Analysis: Monitor job market trends, identify growing sectors, track employment patterns, and forecast hiring demands across Spain's autonomous communities.
Competitive Intelligence: Track competitor hiring activities, understand their workforce expansion plans, and identify skill sets they're prioritizing.
Job Aggregation Services: Power job boards and aggregation platforms with fresh, structured data from Spain's leading employment marketplace.
Conclusion
The InfoJobs.net Job Scraper transforms how you access and utilize Spain's premier job market data. By automating the extraction of comprehensive employment information, you gain competitive advantages in recruitment, market research, and business intelligence. Whether you're analyzing salary trends across Catalonia, tracking tech industry hiring in Madrid, or building a comprehensive Spanish job database, this scraper provides the reliable, structured data foundation you need.
Start extracting valuable job market insights today and transform raw data into actionable intelligence for your organization.
Related Actors
- infojobs.net Jobs Details Scraper: A specialized data extraction tool engineered to harvest detailed jobs information from infojobs's jobs marketplace.
Your feedback
We are always working to improve Actors' performance. So, if you have any technical feedback about infojobs.net Jobs Search Scraper or simply found a bug, please create an issue on the Actor's Issues tab in Apify Console.