Next.co.uk Product Search Scraper
Pricing
$20.00/month + usage
Next.co.uk Product Search Scraper
Advanced Next.co.uk product scraper for extracting comprehensive fashion, homeware, and children's clothing data. Automated solution for market research, competitor analysis, and product monitoring with detailed output fields including pricing, categories, and product specifications.
Pricing
$20.00/month + usage
Rating
0.0
(0)
Developer
ecomscrape
Maintained by CommunityActor stats
0
Bookmarked
8
Total users
1
Monthly active users
8 months ago
Last modified
Categories
Share
Contact
If you encounter any issues or need to exchange information, please feel free to contact us through the following link: My profile
Next.co.uk Scraper: Extract Fashion & Home Product Data - Automated Market Intelligence Tool
Introduction
Next.co.uk stands as one of the UK's leading fashion and homeware retailers, offering the latest in women's, men's & children's fashion plus homeware, beauty, designer brands & more. With online revenue amounting to US$2,418.2m in 2024, Next represents a goldmine of valuable product data for businesses, researchers, and analysts looking to understand fashion trends, pricing strategies, and market dynamics.
The Next.co.uk scraper addresses the critical need for automated data collection from this major retail platform. Manual data gathering from such a vast catalog would be time-consuming and impractical, especially when dealing with thousands of products across multiple categories. This scraper transforms hours of manual work into minutes of automated data extraction, providing structured, actionable insights for market intelligence and competitive analysis.
Overview of the Next.co.uk Scraper
The Next.co.uk product scraper is a sophisticated data extraction tool designed specifically for harvesting comprehensive product information from Next's extensive online catalog. This scraper efficiently navigates through various product categories including women's fashion, men's clothing, children's wear, homeware, and furniture collections.
Key strengths of this scraper include its ability to handle dynamic content, respect rate limits to avoid detection, and extract detailed product specifications that would otherwise require extensive manual research. The tool is particularly valuable for fashion retailers, market analysts, pricing specialists, and business intelligence professionals who need regular access to Next's product data.
Target users include e-commerce businesses conducting competitor analysis, fashion trend researchers, pricing analysts, supply chain professionals, and marketing teams developing market positioning strategies. The scraper is also beneficial for academic researchers studying retail trends and consumer behavior patterns.
Input and Output Details
Example url 1: https://www.next.co.uk/shop/gender-women/0-homepage-feat-newin-latestarrivals-last7days?p=1#0
Example url 2: https://www.next.co.uk/shop/department-homeware-productaffiliation-bedroomfurniture/category-beds
Example Screenshot of product information page:
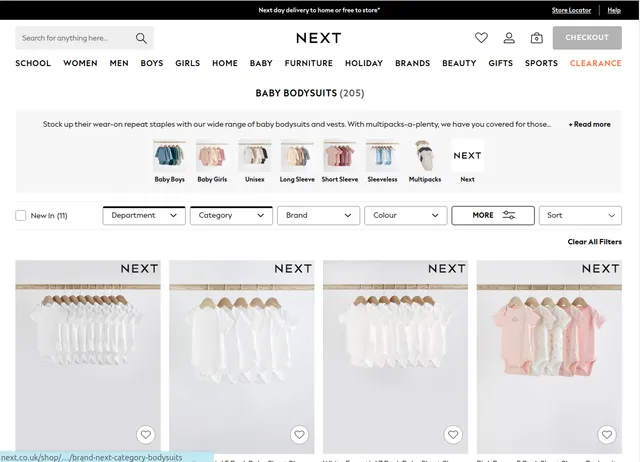
Input Format
The scraper accepts configuration through a JSON object with several key parameters:
Scrape with URLs:
The urls parameter: List of product list page URLs that you want to scrape. You can add URLs one by one, or use the Bulk edit section to add a prepared list.
The ignore_url_failures parameter: If set to true, the scraper will continue running even if some URLs fail to be scraped after reaching the maximum number of retries. This ensures that one problematic URL doesn't stop your entire scraping job.
When you provide a list of URLs for scraping, all options in the "Scrape with search filters" section will be disabled. The system will only collect data from the URLs you specified.
Scrape with Search Filters:
The keyword parameter: The search keyword to find products (e.g., "dress", "shirt", "jeans", "shoes").
The sort_by parameter: Sort products by various criteria:
"score"- Most Relevant (best matches first)"popular"- Most Popular (trending items)"title"- Alphabetical (A to Z)"price"- Price (low to high)"price rev"- Price (high to low)
The page parameter: Starting page number for scraping, useful for continuing interrupted scrapes or targeting specific result ranges.
When using search filters for scraping, you need to leave the urls field empty (or set it to null) in the "Scrape with URLs" configuration.
General Options:
The max_items_per_url parameter: Limits the number of products extracted from each product list page or search results page. The default value is 20, providing a manageable batch size while allowing for comprehensive data collection.
The max_retries_per_url parameter: Sets the maximum number of retry attempts for each URL or search filters if the scrape is detected as a bot or the page fails to load. The default value is 2, providing a good balance between thoroughness and efficiency.
The proxy parameter: Proxy configuration is essential for maintaining anonymity and avoiding detection. The residential proxy option ensures that your scraping activities appear as legitimate browsing, reducing the risk of being blocked or rate-limited. You should choose a country that matches the location of the website you're scraping (e.g., UK/GB for next.co.uk).
Output Format
You get the output from the Stockx.com Product Search Scraper stored in a tab. The following is an example of the Information Fields collected after running the Actor.
The scraper returns comprehensive product data in a structured format with the following fields:
Core Product Information:
- Title: Complete product name and description
- ID: Unique product identifier from Next's system
- Base URL: Product's main webpage link
Visual Assets:
- Image CDN URL: Content delivery network base URL for images
- Product Image URL Part: Specific image path component
- Large Image Path: High-resolution image location
- Use PDP Image: Boolean indicating product detail page image usage
Product Classification:
- Category: Primary product category (e.g., "Dresses", "Beds", "Bodysuits")
- Brand: Brand name or manufacturer
- Department: Store department classification (Women's, Men's, Children's, Homeware)
- Fit: Size or fit specifications
- Type: Detailed product type classification
Commercial Data:
- Currency Code: Pricing currency (typically GBP for UK site)
- Colourways: Available color options and variants
Marketing Indicators:
- Show New In: Boolean indicating new arrival status
- Sale Sash: Promotional badge information
- Sale Sash Position: Placement of sale indicators
Each field serves specific analytical purposes: pricing data enables competitive analysis, category information supports market segmentation, and visual assets facilitate product comparison and catalog management.
Usage Guide
Step 1: Configuration Setup Configure your input JSON with appropriate proxy settings and target URLs. Select representative product listing pages that cover your areas of interest.
Step 2: URL Selection Choose URLs from Next's category pages, search results, or specific product collections. Ensure URLs point to product listing pages rather than individual product pages for optimal results.
Step 3: Execution Run the scraper with your configured parameters. The tool will automatically navigate through pages, extract data, and handle any temporary access issues through retry mechanisms.
Best Practices:
- Use residential proxies to maintain access reliability
- Set reasonable item limits to avoid overwhelming the system
- Target specific categories rather than attempting site-wide scraping
- Schedule regular runs during off-peak hours for better performance
Common Issues and Solutions:
- Rate limiting: Reduce
max_items_per_urland increase delays - Proxy blocks: Rotate proxy countries and use fresh IP addresses
- Data inconsistencies: Validate output fields and handle missing data appropriately
Benefits and Applications
The Next.co.uk scraper delivers significant time savings by automating what would otherwise require hundreds of hours of manual data collection. A task that might take a team days to complete manually can be accomplished in minutes with comprehensive accuracy.
Real-world applications include competitive pricing analysis, trend forecasting, inventory planning, and market research. Fashion retailers can monitor competitor pricing strategies, while analysts can track seasonal trends and product lifecycle patterns. The data enables informed decision-making for product sourcing, pricing strategies, and market positioning.
Business value extends to improved market intelligence, reduced research costs, and enhanced competitive positioning. Organizations can respond quickly to market changes, optimize their product mix, and identify emerging opportunities in the fashion and homeware sectors.
Conclusion
The Next.co.uk scraper represents a powerful solution for automated product data extraction from one of the UK's premier retail platforms. With comprehensive output fields and reliable extraction capabilities, it transforms complex data gathering into a streamlined, efficient process.
Ready to unlock valuable market insights from Next.co.uk? Start extracting comprehensive product data today and gain the competitive edge your business needs in the dynamic fashion and homeware market.
Related Actors
- Next.co.uk Product Details Scraper: A specialized data extraction solution engineered to harvest comprehensive product information from Next.co.uk's exclusive sneaker and streetwear marketplace.
Your feedback
We are always working to improve Actors' performance. So, if you have any technical feedback about Next.co.uk Product Search Scraper or simply found a bug, please create an issue on the Actor's Issues tab in Apify Console.