Willhaben Jobs Search Scraper
Pricing
$20.00/month + usage
Willhaben Jobs Search Scraper
The Willhaben.at Jobs Scraper automates the extraction of job listings from Austria's largest digital marketplace. Collect comprehensive employment data including job titles, locations, salaries, company information, and employment details from over 17,000+ active listings for recruitment analytics,
Pricing
$20.00/month + usage
Rating
0.0
(0)
Developer
ecomscrape
Maintained by CommunityActor stats
0
Bookmarked
10
Total users
1
Monthly active users
8 months ago
Last modified
Categories
Share
Contact
If you encounter any issues or need to exchange information, please feel free to contact us through the following link: My profile
Willhaben.at Jobs Scraper: Extract Austrian Employment Data Efficiently
Introduction: Why Scrape Willhaben.at Jobs?
Willhaben is Austria's largest digital marketplace and one of the most visited websites in the country, attracting millions of unique users monthly. The platform's jobs section hosts thousands of active employment opportunities across various industries, making it a goldmine for recruitment professionals, HR analysts, market researchers, and business intelligence teams.
With over 400,000 unique users accessing willhaben jobs monthly, the platform represents a comprehensive snapshot of Austria's employment market. However, manually collecting and analyzing this data is time-consuming and impractical. This is where automated job scraping becomes invaluable—enabling professionals to extract, analyze, and leverage employment data at scale for informed decision-making.
Overview: What is the Willhaben.at Jobs Scraper?
The Willhaben.at Jobs Scraper is a specialized data extraction tool designed to automate the collection of job listings from willhaben.at's employment section. This scraper navigates through job search results pages, extracts comprehensive job information, and delivers structured data ready for analysis or integration into your systems.
Key Capabilities
This scraper offers several powerful features that make it essential for employment data collection:
- Multi-URL Processing: Extract jobs from multiple search queries simultaneously, allowing you to gather data across different job categories, locations, or keywords in a single run
- Comprehensive Data Extraction: Captures all critical job information including titles, descriptions, company details, locations, salary ranges, employment types, and metadata
- Residential Proxy Support: Built-in proxy configuration ensures reliable data collection without triggering anti-bot mechanisms
- Customizable Volume Control: Set limits on items per URL to manage data collection scope and optimize scraping costs
- Error Resilience: Automatic retry mechanisms and failure handling ensure maximum data collection success
Who Benefits from This Scraper?
The Willhaben.at Jobs Scraper serves diverse professional needs:
- Recruitment Agencies: Monitor competitor job postings, identify hiring trends, and discover potential client companies
- HR Professionals: Benchmark salaries, analyze employment terms, and understand market compensation standards
- Business Analysts: Track industry hiring patterns, identify growth sectors, and conduct market research
- Job Aggregators: Build comprehensive job databases by collecting listings from Austria's leading employment platform
- Academic Researchers: Study employment trends, labor market dynamics, and economic indicators
Input Configuration Explained
Example url 1: https://www.willhaben.at/jobs/suche?keyword=Tankstelle
Example url 2: https://www.willhaben.at/jobs/suche/vollzeit
Example url 3: https://www.willhaben.at/jobs/suche?keyword=Teilzeit&page=2
Example Screenshot of jobs list by query page:
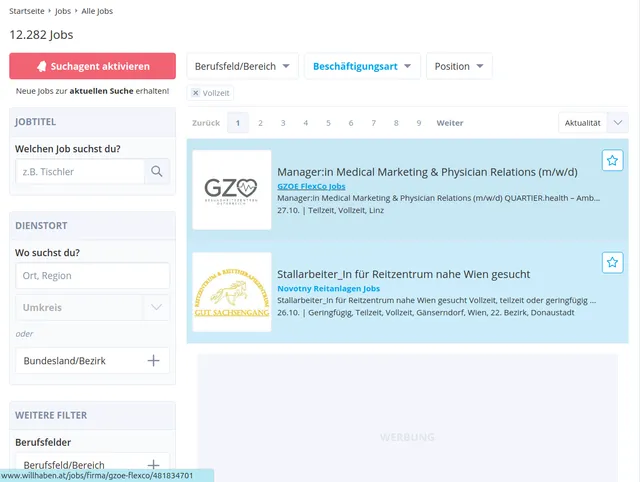
Input Format
The scraper accepts configuration through a JSON object with several key parameters:
Scrape with URLs:
The urls parameter: Add the URLs of the job list pages you want to scrape. You can paste URLs one by one, or use the Bulk edit section to add a prepared list.
The ignore_url_failures parameter: If set to true, the scraper will continue running even if some URLs fail to be scraped after the maximum number of retries is reached. This ensures that one problematic URL doesn't stop your entire scraping job.
When you provide a list of URLs for scraping, all options in the "Scrape with search filters" section will be disabled. The system will only collect data from the URLs you specified.
Scrape with Search Filters:
The keyword parameter: Enter the keyword to search for items (e.g., "software engineer", "marketing manager", "accountant").
The job_type parameter: Filter jobs by employment type:
"110"- Full-time"113"- Part-time"109"- Freelance"11796"- Slightly
The position parameter: Filter jobs by position level:
"13540"- Group/Team Leadership"13541"- Teach"13539"- Management"13542"- Employee"13543"- Internship"13544"- Project management"28428"- Traineeship
The published_date parameter: Filter jobs by publishing date:
""- Any"last_24_hours"- Last 24 hours"last_72_hours"- Last 3 days"last_week"- Last 7 days
The sort_by parameter: Sort jobs by specific criteria:
"publish_date_desc"- Newest first"relevance"- Relevance
The page parameter: Specify the page number to start scraping from, useful for continuing interrupted scrapes or targeting specific result ranges.
When using search filters for scraping, you need to leave the urls field empty in the "Scrape with URLs" configuration.
General Options:
The max_items_per_url parameter: Limit the number of items per URL or search filters you want to scrape. The default value is 20, providing a manageable batch size while allowing for comprehensive data collection.
The max_retries_per_url parameter: Limit the number of retries for each URL or search filters if the scrape is detected as a bot or the page fails to load. The default value is 2, providing a good balance between thoroughness and efficiency.
The proxy parameter: Proxy configuration is essential for maintaining anonymity and avoiding detection. The residential proxy option ensures that your scraping activities appear as legitimate browsing, reducing the risk of being blocked or rate-limited. You should choose a country that matches the location of the website you're scraping (e.g., Austria/AT for willhaben.at).
Comprehensive Output Data Structure
You get the output from the willhaben.at Jobs Search Scraper stored in a tab. The following is an example of the Information Fields collected after running the Actor.
The scraper extracts the following fields for each job listing:
ID (string): A unique identifier assigned by willhaben.at to each job posting. This serves as a primary key for database storage and enables tracking of specific listings over time for monitoring purposes such as identifying when jobs are reposted or removed.
Title (string): The job position name as advertised by the employer. This is the main heading job seekers see and typically includes the role name and sometimes seniority level. Use this field for job categorization, keyword analysis, and matching candidates to positions.
Slug Title (string): A URL-friendly version of the job title, formatted with hyphens instead of spaces and special characters removed. This is used in the job's web address and can serve as a human-readable unique identifier in your systems.
Creation Date (datetime): The timestamp when the job listing was first created in willhaben's system. This helps you identify the freshest opportunities and calculate how long positions remain open—valuable for understanding hiring urgency and market competition.
URL (string): The direct link to the job's detail page on willhaben.at. Essential for linking users to full job descriptions, application forms, and enabling candidates to apply directly through the platform.
First Publish Date (datetime): When the job was first made visible to the public. This may differ from creation date if employers prepared listings in advance. Use this to track actual market exposure time.
Last Reorder Date (datetime): Indicates when the employer paid to promote or "bump" the listing to appear higher in search results. Recent reorder dates suggest active hiring and employer investment in filling the position quickly.
Is Expired (boolean): Flags whether the job listing is still active (false) or has been closed/expired (true). Critical for filtering current opportunities and cleaning outdated data from your database.
Overpay (boolean): Indicates if the position offers above-market compensation. This premium feature allows employers to highlight competitive salaries, helping you identify high-value opportunities or benchmark competitive compensation packages.
Top Job (boolean): Marks featured or promoted listings that employers paid to highlight. These positions typically receive more visibility and may indicate urgency or importance to the hiring company.
Position (string): The specific job role or title, sometimes more detailed than the Title field. May include department information, specialization areas, or seniority indicators that help with precise job classification.
Job Locations (array): Contains one or more geographic locations where the job is based. Can include cities, regions, or indicate remote work options. Essential for location-based filtering and understanding geographic hiring patterns.
Description (string): The complete job posting text including responsibilities, requirements, qualifications, benefits, and company information. This rich-text field is valuable for natural language processing, keyword extraction, and skills analysis.
Company (string): The hiring organization's name. Use this to track which companies are actively hiring, analyze employer hiring patterns, identify potential clients for B2B services, or monitor competitor recruitment activities.
Last Modified Date (datetime): The most recent timestamp when any aspect of the listing was updated. Helps identify jobs with recent changes to descriptions, requirements, or terms—potentially indicating hiring challenges or evolving role needs.
Salary (string): The compensation offered, when disclosed. May be formatted as a range, fixed amount, or text description. Critical for salary benchmarking, compensation analysis, and understanding market rates across industries and positions.
Salary Time Frame (string): Specifies the pay period for the stated salary (e.g., "per month", "per year", "per hour"). Essential for normalizing salary data across listings and accurately comparing compensation packages.
Employment Time (string): Indicates the duration or schedule of employment such as "full-time", "part-time", "contract", or specific hour requirements. Helps job seekers filter by availability and analysts understand employment type distribution.
Employment Modes (array): Details work arrangement options like "on-site", "remote", "hybrid", or specific flexibility terms. Increasingly important for modern work preference analysis and understanding employer flexibility offerings.
Brand New (boolean): Flags listings posted within the last 24-48 hours. Valuable for applications prioritizing fresh opportunities or monitoring real-time hiring activity.
Internal Application (boolean): Indicates if the position is an internal promotion opportunity versus external hiring. Useful for understanding company growth patterns and internal mobility rates.
Data Utilization Strategies
The extracted data supports numerous business applications:
- Salary Benchmarking: Aggregate salary data by position, industry, and location to establish competitive compensation ranges
- Hiring Trend Analysis: Track which companies are hiring, in what roles, and at what frequency to identify market expansion
- Skills Gap Analysis: Extract required skills from descriptions to understand in-demand competencies
- Geographic Insights: Map job concentration by region to identify economic hotspots or underserved markets
- Competitive Intelligence: Monitor competitor hiring patterns, organizational growth, and strategic priorities
- Job Board Enrichment: Populate job aggregator platforms with comprehensive Austrian employment data
How to Use the Willhaben.at Jobs Scraper
Option 1: Implementation with URLs
Step-by-Step Implementation
Step 1: Define Your Data Collection Scope Identify the job categories, keywords, locations, or companies you want to target. Browse willhaben.at/jobs manually to construct appropriate search URLs that capture your target listings.
Step 2: Configure Input Parameters Create your JSON input configuration:
- Add your target URLs to the
urlsarray - Set
max_items_per_urlbased on your data volume needs (default: 20) - Configure proxy settings with
apifyProxyCountry: "AT"for optimal results - Set
max_retries_per_urlto 2-3 for reliability - Enable
ignore_url_failuresto ensure one problematic URL doesn't stop your entire scraping job
Step 3: Execute the Scraper Run the scraper through your preferred platform. Monitor the execution log for progress updates and any error messages.
Step 4: Retrieve and Validate Data Download the extracted data in your preferred format (JSON, CSV, Excel). Validate data completeness by checking key fields like Title, Company, and URL.
Step 5: Process and Analyze Import data into your database, analytics platform, or business intelligence tools. Apply filters, aggregations, and visualizations to derive insights.
Option 2: Implementation with Search Filters
Setting Up Search Criteria
Instead of manually creating URLs, use search filters to automatically generate job searches. This method is ideal for systematic job data collection across different criteria.
Step 1: Define Search Keywords
- Enter a
keywordparameter to search for specific job types (e.g., "software engineer", "marketing manager", "accountant") - Use job titles, skill names, or industry terms
- Keywords should match common job posting terminology
Step 2: Configure Job Type
Select the job_type parameter based on employment type:
"110"- Full-time positions"113"- Part-time positions"109"- Freelance opportunities"11796"- Slightly (minor employment)
Step 3: Set Position Level
Use the position parameter to filter by seniority or role type:
"13540"- Group/Team Leadership"13541"- Teaching positions"13539"- Management roles"13542"- Employee level"13543"- Internships"13544"- Project management"28428"- Traineeships
Step 4: Filter by Recency
Configure published_date to focus on recent postings:
"last_24_hours"- Most recent (24 hours)"last_72_hours"- Last 3 days"last_week"- Last 7 days- Leave empty for all dates
Step 5: Choose Sorting Method
Set sort_by to organize results:
"publish_date_desc"- Newest first (recommended for tracking new postings)"relevance"- Most relevant to search criteria
Step 6: Configure Pagination
- Set
pageparameter to start from a specific result page - Useful for resuming interrupted scrapes or targeting specific result ranges
Best Practices for Filter-Based Scraping
Keyword Strategy: Use targeted keywords for better results:
- Specific job titles: "Software Engineer", "Marketing Manager", "Data Analyst"
- Skills: "Python Developer", "SEO Specialist", "Project Manager"
- Industry terms: "Finance", "Healthcare", "IT", "Construction"
Job Type Selection: Choose appropriate employment types:
- Full-time for permanent positions and career opportunities
- Part-time for flexible work arrangements
- Freelance for contract or project-based work
- Combine multiple job types by running separate searches
Position Level Filtering: Target the right seniority level:
- Use "Employee" for entry-level and mid-level positions
- Select "Management" or "Group/Team Leadership" for senior roles
- Choose "Internship" or "Traineeship" for junior opportunities
- Filter by "Project management" for specialized PM roles
Date Filtering Strategy: Balance freshness with coverage:
- Use "last_24_hours" for daily job alerts
- Select "last_week" for weekly market analysis
- Leave empty for comprehensive historical data
- Newer postings typically have higher response rates
Sorting Optimization:
- Use "Newest first" (
publish_date_desc) to track new opportunities - Use "Relevance" for keyword-focused searches
- Consider running both sorts for comprehensive coverage
Progressive Search Strategy: For comprehensive job market coverage:
- Start with broad keywords and full-time positions
- Run separate searches for different job types (part-time, freelance)
- Filter by specific position levels for targeted results
- Combine results from multiple date ranges
Data Validation and Quality Control
After extraction, verify that:
- Job titles match your keyword criteria
- Employment types correspond to your
job_typefilter - Position levels align with your
positionsetting - Posting dates fall within your
published_daterange - Results are sorted according to your
sort_bypreference - No duplicate job postings across searches
Common Issue Resolution
Empty Results:
- Broaden your keyword if too specific
- Remove or adjust position level filter
- Extend
published_daterange or remove date filter - Verify keyword spelling and terminology
Keyword Matching Issues:
- Test keywords on Willhaben.at directly first
- Use German job titles for better results (e.g., "Softwareentwickler" instead of "Software Developer")
- Try synonyms or related terms
- Avoid overly specific or niche terminology
Job Type Filtering:
- Verify correct job type code from available options
- Try removing job type filter for broader results
- Check if your target jobs exist on Willhaben.at
Position Level Filtering:
- Not all jobs specify position level clearly
- Remove position filter if getting no results
- Try multiple position levels in separate searches
Date Range Issues:
- Newly posted jobs may not appear in "last_24_hours" immediately
- Adjust date filter if expecting more results
- Consider website's posting delay in timing your scrapes
Sorting Problems:
- Relevance sorting depends on keyword match quality
- Newest first always works regardless of keyword
- Use newest first for time-sensitive job hunting
Advanced Search Techniques
Multi-Keyword Strategy: Run separate searches for:
- Different job title variations
- Related skills and specializations
- Industry-specific terminology
- Company name variations
Comprehensive Employment Coverage: For complete job market analysis:
- Search all job types separately (full-time, part-time, freelance)
- Cover all position levels with individual searches
- Combine results to understand full market landscape
Time-Based Monitoring: Track job market changes over time:
- Daily scrapes with "last_24_hours" filter
- Weekly comparisons using "last_week" filter
- Historical analysis by removing date filters
- Track posting frequency and patterns
Position-Level Analysis: Understand job distribution by seniority:
- Separate searches for each position level
- Compare volume across experience levels
- Identify trends in hiring for different roles
Tips for Optimal Results
- Schedule Regular Runs: Job data changes frequently; schedule daily or weekly scraping to maintain current information
- Use Specific Searches: Targeted keywords and filters yield more relevant results than broad queries
- Monitor for Changes: Track posting dates to identify new listings and market trends
- Respect Rate Limits: While residential proxies reduce detection risk, implement reasonable delays between large scraping operations
- Data Deduplication: Track job IDs to prevent duplicate records when combining multiple scraping runs
- Combine Both Methods: Use URLs for specific, complex searches and filters for systematic coverage
Handling Common Issues
Empty Results: Verify your search criteria are valid. Check if keywords and filters return results when tested manually on Willhaben.at.
Incomplete Data: Some fields may be null if employers didn't provide that information. This is normal—not all listings include salary, exact locations, or all metadata.
Proxy Errors: If encountering frequent failures, ensure your proxy configuration is correct with apifyProxyCountry: "AT" for Austrian proxies. Consider increasing max_retries_per_url.
Rate Limiting: If the scraper is blocked, reduce max_items_per_url, increase delays between requests, or ensure residential proxies are properly configured.
Filter Conflicts: If using search filters produces unexpected results, test the same filter combination manually on Willhaben.at to verify expected behavior.
Language Issues: Willhaben.at is primarily in German. Use German keywords and terminology for best results, though some English terms may work for international job postings.
Benefits and Real-World Applications
Time and Cost Efficiency
Manual job data collection from willhaben.at is prohibitively time-consuming. Copying information from even 100 job listings could take 3-4 hours, and maintaining updated data requires repeating this process regularly. The scraper automates this task in minutes, freeing your team to focus on analysis and decision-making rather than data entry.
Practical Use Cases
Recruitment Optimization: Agencies use the scraper to monitor which companies are hiring in their specialization areas, enabling proactive client outreach and candidate matching.
Market Research: Business analysts track hiring volumes by industry and region to identify growth sectors and inform investment decisions or market entry strategies.
Compensation Planning: HR departments aggregate salary data to establish competitive pay scales, ensuring they attract talent without overpaying relative to market standards.
Competitive Analysis: Companies monitor competitor hiring patterns to understand rival expansion plans, technological focus areas, and talent acquisition strategies.
Job Aggregation: Employment platforms syndicate willhaben.at listings to provide comprehensive job coverage for Austrian job seekers, increasing their platform value.
Business Value
Access to structured, comprehensive job market data provides significant competitive advantages. Organizations can make data-driven hiring decisions, optimize recruitment budgets, identify emerging skill demands early, and respond quickly to market changes. For recruitment businesses, this intelligence directly translates to faster placements, better client service, and increased revenue.
Conclusion
The Willhaben.at Jobs Scraper transforms how organizations access and utilize Austrian employment market data. By automating the extraction of comprehensive job information from the country's leading employment platform, it enables businesses to make informed decisions based on current market intelligence rather than intuition or outdated information.
Whether you're optimizing recruitment strategies, conducting market research, benchmarking compensation, or building job aggregation services, this scraper provides the foundation for data-driven success in the Austrian employment market.
Ready to unlock the power of automated job data collection? Configure your scraper today and gain instant access to actionable employment market intelligence.
Related Actors
- willhaben.at Jobs Details Scraper: A specialized data extraction tool engineered to harvest detailed jobs information from willhaben's.
Your feedback
We are always working to improve Actors' performance. So, if you have any technical feedback about willhaben.at Jobs Search Scraper or simply found a bug, please create an issue on the Actor's Issues tab in Apify Console.