Research Institution Scraper (OpenAlex)
Pricing
from $6.00 / 1,000 leads
Research Institution Scraper (OpenAlex)
Find B2B leads from universities, hospitals, research companies, and government labs via the free OpenAlex API. Filter by institution type, country, and research topic. Returns name, homepage, location, H-index, top research topics, and citation counts.
Pricing
from $6.00 / 1,000 leads
Rating
0.0
(0)
Developer
GoCreative AI
Maintained by CommunityActor stats
0
Bookmarked
2
Total users
1
Monthly active users
25 days ago
Last modified
Categories
Share
University & Research Institution Scraper (OpenAlex) — Academic B2B Leads
📊 Example output (real run)
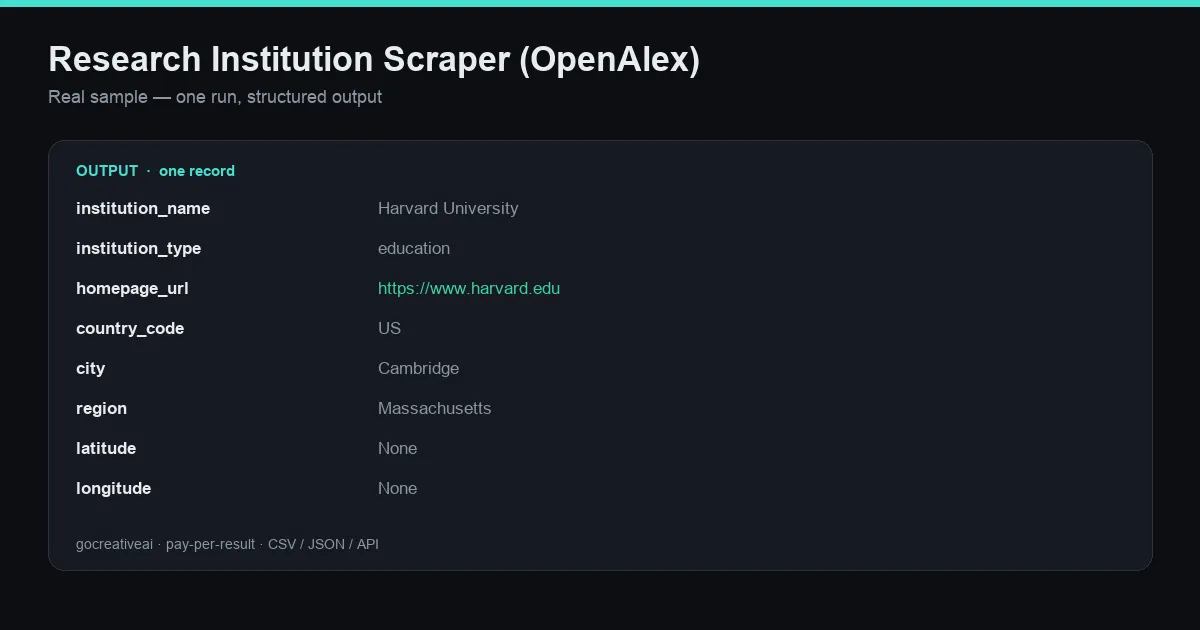
A real record from a live run — clean structured data, exported as CSV / JSON / Excel or via API.
Build a targeted list of universities, hospitals, research institutes, and government labs — with homepage, location, output volume, and research impact — from the free OpenAlex catalog of 100,000+ institutions worldwide.
No API key, no signup, no subscription. Pay only for the results you pull. Clean typed records for CSV, JSON, Excel, or direct API export.
What this scraper does
Filter the global OpenAlex institution graph by type (education, hospital, company, government, nonprofit, facility), country, and research topic / search query, and get a clean row per institution: name, type, homepage URL, country, city/region, works count, cited-by count, h-index, ROR id, and OpenAlex id.
It turns the world's open catalog of research organizations into a segmentable B2B lead list — sorted and filterable by real research output, not guesswork.
Why this instead of the alternatives
| OpenAlex Institution Scraper | Buying an academic list | Scraping university sites one by one | |
|---|---|---|---|
| Coverage | 100k+ institutions, global | Region-limited, often US-only | Whatever you have time for |
| Segmentation | By type, country, topic, output size | Fixed, pre-cut segments | None |
| Impact signal | works_count, h-index, cited-by | Rarely included | Not available |
| Freshness | Live OpenAlex (open, updated) | Stale snapshot | Manual |
| Pricing | Pay-per-result, no subscription | $$$ per list | Your time |
OpenAlex is the open successor to Microsoft Academic Graph — authoritative, free, and updated. This actor makes it queryable as leads.
Input
| Field | Description |
|---|---|
types | Institution types to include: education, healthcare, company, government, nonprofit, facility |
countries | ISO country codes to filter by (e.g. US, GB, DE) |
searchQuery | Free-text topic / name search |
minWorks | Minimum published-works count (filter out tiny/inactive institutions) |
maxResults | Cap the number of institutions returned |
Output
One structured record per institution:
institution_name · institution_type · homepage_url · country_code · city · region · latitude · longitude · works_count · cited_by_count · h_index · top_research_topics · ror_id · openalex_url
Export the full dataset as CSV, JSON, or Excel from the Apify console, or via the Apify API.
Use cases
- EdTech / research-SaaS sales — target universities and institutes by size and field
- Lab equipment & scientific vendors — reach high-output research institutions
- Grants & partnerships — find institutions active in a specific research topic
- Recruiting & academic services — segment by country, type, and output
- Market & competitive research — map the research landscape of a field or region
FAQ
Do I need an API key or OpenAlex account? No. Set your filters and run it.
Is the data authoritative? Yes — OpenAlex is a free, open, continuously-updated catalog of scholarly institutions (the open successor to Microsoft Academic Graph).
Can I schedule it? Yes — use Apify Schedules to refresh your list on a cadence.
What formats can I export? CSV, JSON, Excel, or via the Apify API.
Can I integrate it into my app? Yes — call it via the Apify API and pull results into your pipeline.