Metadata Extractor
Pricing
Pay per usage
Go to Apify Store

Metadata Extractor
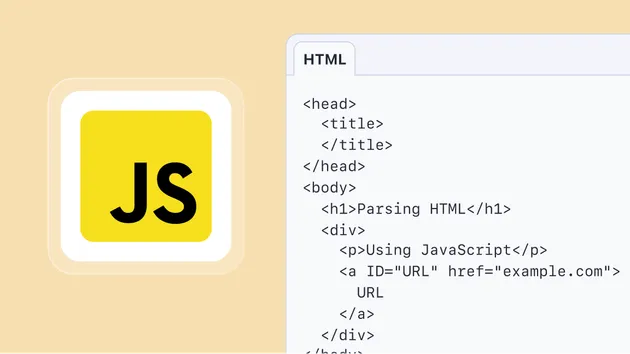
A small efficient actor that loads a web page, parses its HTML using Cheerio library and extracts the following meta-data from the <HEAD> tag, such as page title, description, author etc.
Pricing
Pay per usage
Rating
0.0
(0)
Developer
Jan Čurn
Maintained by Community
Actor stats
17
Bookmarked
1.3K
Total users
28
Monthly active users
2 years ago
Last modified
Categories
Share
The actor takes a list of URLs of web pages on input, loads the HTML, and then extracts metadata from the HTML. The result is stored as a JSON file into the default dataset.
For example, for https://www.apify.com, the JSON result looks as follows: