Instagram Scraper
Pricing
from $1.50 / 1,000 results
Instagram Scraper
Extract Instagram posts, reels, profiles, places, hashtags, carousels, and comments. Get data from Instagram using one or more Instagram URLs or search queries: content, context, metrics, metadata. Export scraped data, run the scraper via API, schedule and monitor runs or integrate with other tools.
Pricing
from $1.50 / 1,000 results
Rating
4.7
(508)
Developer
Apify
Maintained by ApifyActor stats
4.2K
Bookmarked
342K
Total users
37K
Monthly active users
19 hours
Issues response
2 days ago
Last modified
Categories
Share
What can Instagram Scraper do?
Instagram Scraper extracts public data from across Instagram in a single tool: posts and reels from a profile, comments on a single video, mentions of a brand, profile details for a creator, place metadata for a city, or volume and reach for a hashtag. Add a URL match it with one of the 5 available content types and you can:
| 📦 What you can extract | ⚙️ Features & integrations |
|---|---|
|
📷 Posts and carousels from profiles, hashtagged posts, or tagged posts |
🔎 Search Instagram by user, hashtag, or place |
If you're in the market for influencer discovery, trend tracking, competitor monitoring, local business discovery, content and image analysis, UGC discovery, sentiment analysis, campaign performance tracking, brand monitoring, and more, you can get it all from a single tool.
What data can I scrape from Instagram?
Instagram Scraper is the unofficial Instagram API that 300K+ users rely on to pull the public data Instagram cut off from its official API in 2020. No Business or Creator account, no OAuth, no limits on public data. You get the content, context, engagement metrics, and metadata behind any social media insight:
-
Posts and reels: what was posted, how it landed, who's around it. Captions, hashtags, mentions, image and video URLs, carousel children, engagement (likes, comments, views, plays, first + latest comments), and context (location, owner, tagged users, co-authors, music). Plus
shortCode,url,type, andproductTypefor joining and filtering. -
Mentions: who's tagging you. Same shape as a post, filtered to posts where a target profile is tagged. Drop in a profile URL, get every public post pointing at it.
-
Comments: what people are saying. Text, author identity (username, ID, profile pic, verified status), timestamp, likes, replies, and links to the comment and parent post.
-
Profiles: who's behind the account. Bio, full name, follower/following counts, posts and highlight reel counts, verified and business status.
-
Hashtags: how big and how reachable. Post count, posts per day, related-tag clusters bucketed by reach tier (frequent, average, rare). Useful for finding less-saturated adjacent tags.
-
Places: where it happened. Name, coordinates, address (city, country, category), post count, top and latest posts.
You can scrape from an existing list of URLs (profile, post, reel, hashtag, or place), or discover and scrape by running a search query for matching profiles, hashtags, or places.
Need more? Try these dedicated scrapers for features and data not covered by the main Instagram Scraper:
- 📢 Instagram Ads Scraper: ads and creatives data with pricing enrichment
- 🎞️ Instagram Reel Scraper: reels with share counts and transcripts, plus a reels download option
- 👤 Instagram Profile Scraper: profile extraction with location and verification data
- 🤝 Brand Collaboration Scraper: find brand and influencer collaborations across Instagram
- 💬 Export Instagram Comments and Posts: scrape posts and their comments in one run
How much will scraping Instagram cost?
Instagram Scraper uses a pay-per-event (PPE) pricing model, where one result equals one scraped item (a post, reel, comment, profile, hashtag, or place). On the Free plan, it costs $2.70 per 1,000 results, with no discount applied.
Paid plans offer discounted rates and higher monthly credit. For example, the Starter plan charges $2.30 per 1,000 results, which allows you to scrape over 16,900 results per month. The Scale and Business plans reduce the price to $1.90 with 104,700 results per month, and $1.50 with 666,000 results per month, respectively. Check the pricing tab for full details.
How do I use Instagram Scraper?
Instagram Scraper was designed to be easy to start with, even if you've never scraped a website before. Here's how to extract Instagram data with this tool:
- Create a free Apify account using your email.
- Open Instagram Scraper in Apify Console.
- Pick what you want to scrape under Content to scrape: Posts, Reels, Comments, Mentions, or Details for profiles, hashtags, or places.
- Paste one or more Instagram URLs matching that content type.
- Set how many results you want per URL under Results limit, and optionally filter by date.
- Alternatively, run a search query. Enter one or more keywords and pick a search type: hashtag, profile, or place.
- Click Save & Start and wait for the data to be extracted.
- Download your dataset in JSON, CSV, Excel, or XML, or pull it programmatically via the Apify API.
For a step-by-step walkthrough with screenshots, follow our How to scrape Instagram tutorial 📝, or watch this video guide:
⬇️ Input
Instagram Scraper has two input modes: scrape by URL when you already know which pages to scrape, or discover by search query when you don't. Pick one mode per run; you can't mix them, and URLs always take priority if both are filled in.
Mode 1: Scrape by URL
- Paste one or more Instagram URLs (or profile IDs). Use Bulk edit to add many at once. Then choose:
- Content to scrape — the result type (posts, reels, comments, mentions, or details)
- Results limit — how many results per URL
- Filter by date (optional) — only return content newer than a date or relative period (UTC)
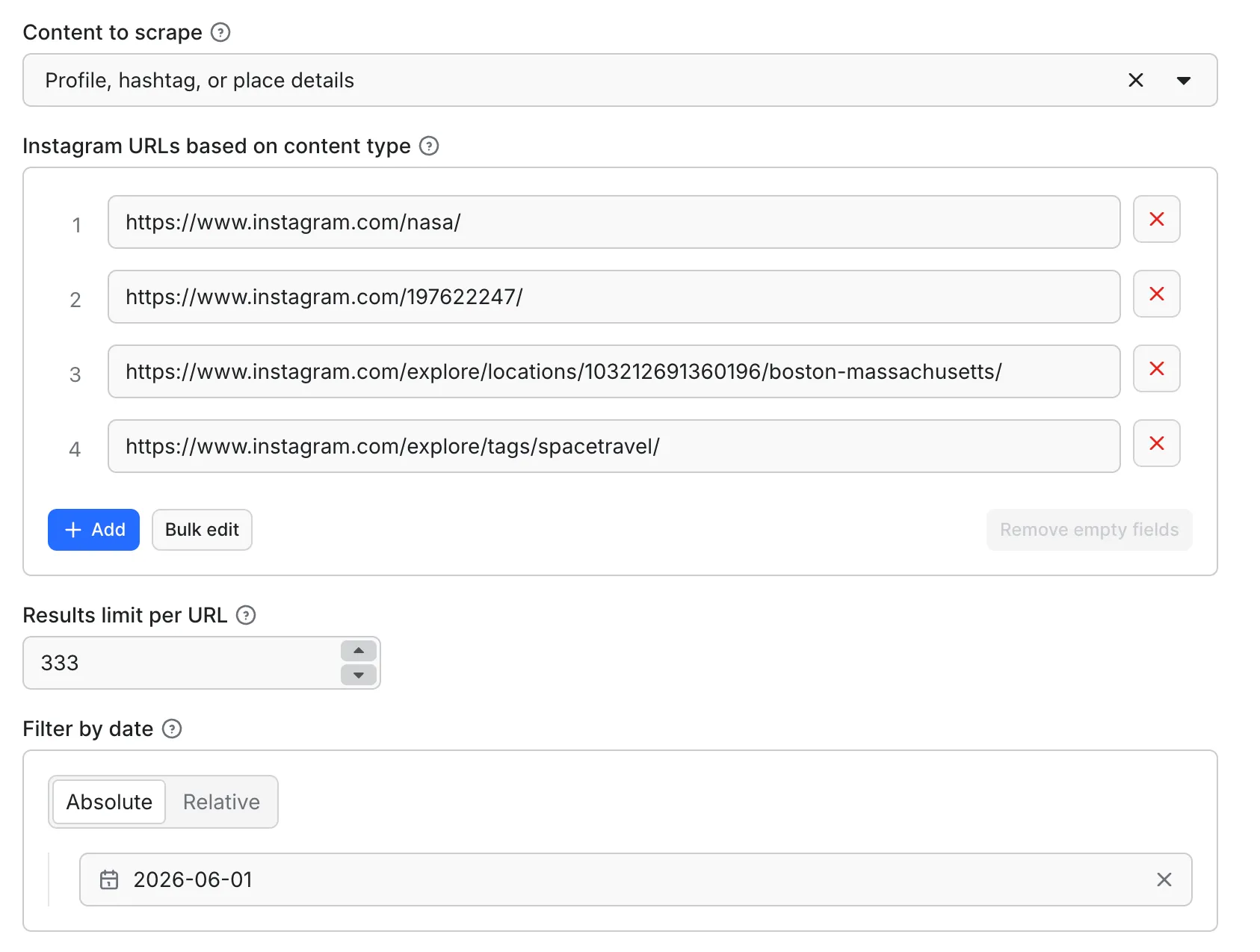
The URL type drives what's returned:
| Paste this URL | And you can get |
|---|---|
| Profile URL or Profile ID | Profile details, posts, reels, or profile mentions |
| Post URL or Reel URL | Post/reel details or its comments |
| Hashtag URL | Hashtagged posts or reels, or hashtag volume |
| Location URL or Audio URL | Place or audio details |
Mode 2: Discover by search query
Enter one or more keywords (comma-separated, e.g. travel, fitness) and pick a search type. Enter hashtags as plaintext (travel, not #travel).
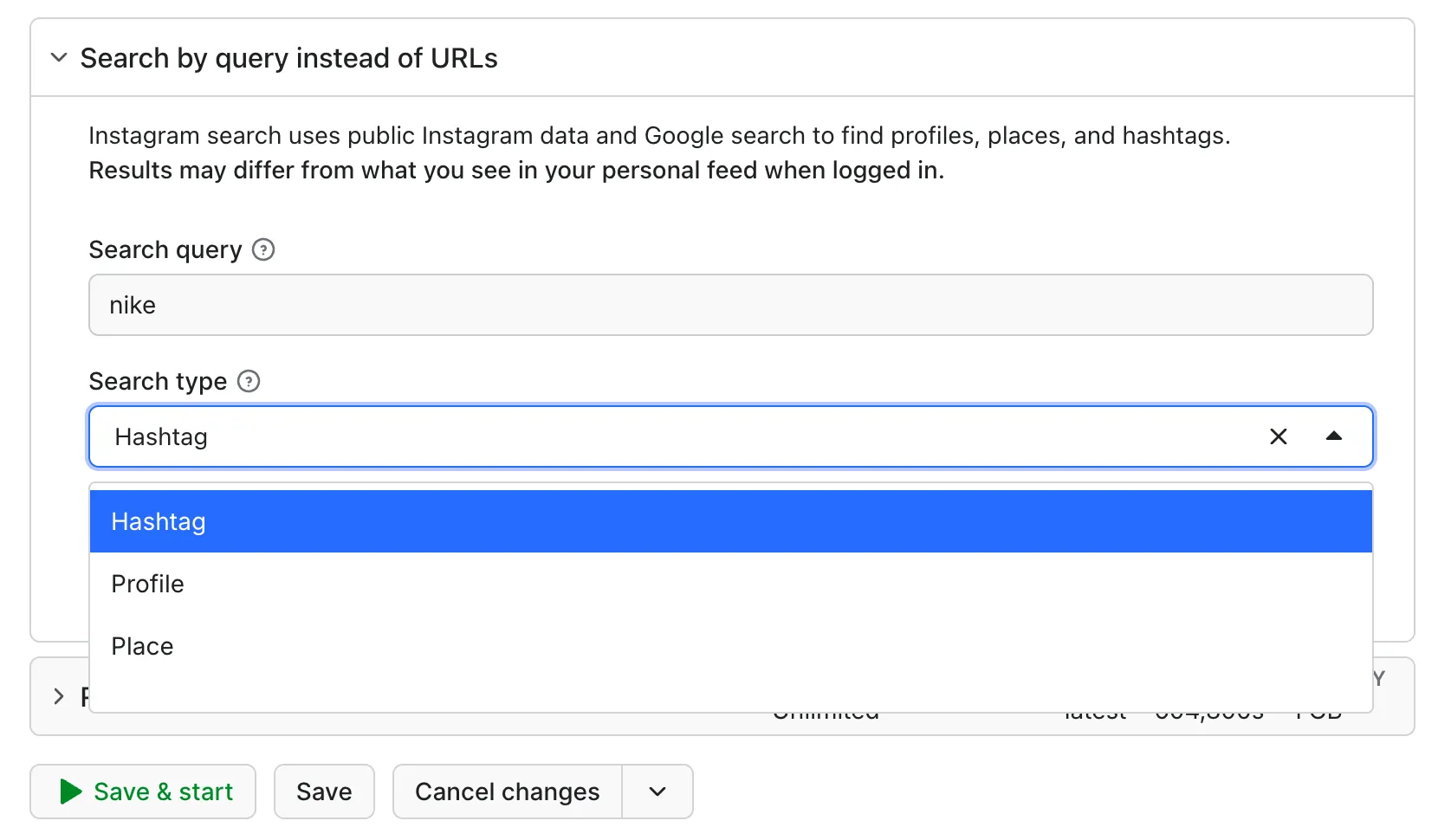
| Search type | What it returns |
|---|---|
hashtag | Hashtag volume and related hashtags matching your query |
place | Tagged places and small businesses matching your query |
user | Users (and content from users) matching your query |
⬆️ Output and setup
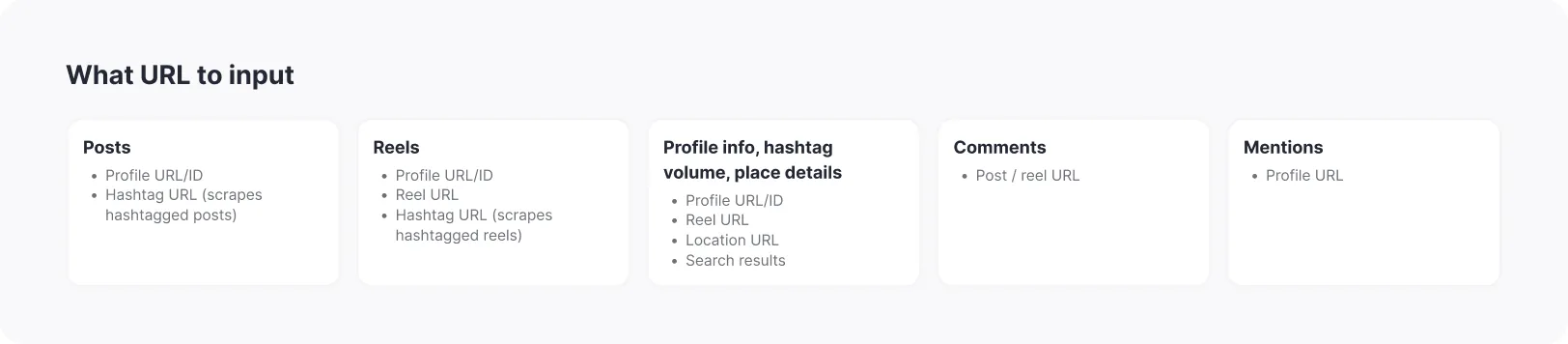
The most important thing to know is that URL type drives output schema. Hashtag, location, audio, and explore URLs return their respective metadata even when paired with another content mode.
Results land in a dataset in the Storage tab. View as a table, download in JSON, CSV, Excel, or XML, or pull via API. Note that different outputs cannot be combined in a single run. Each content type produces a different output schema. Samples below.
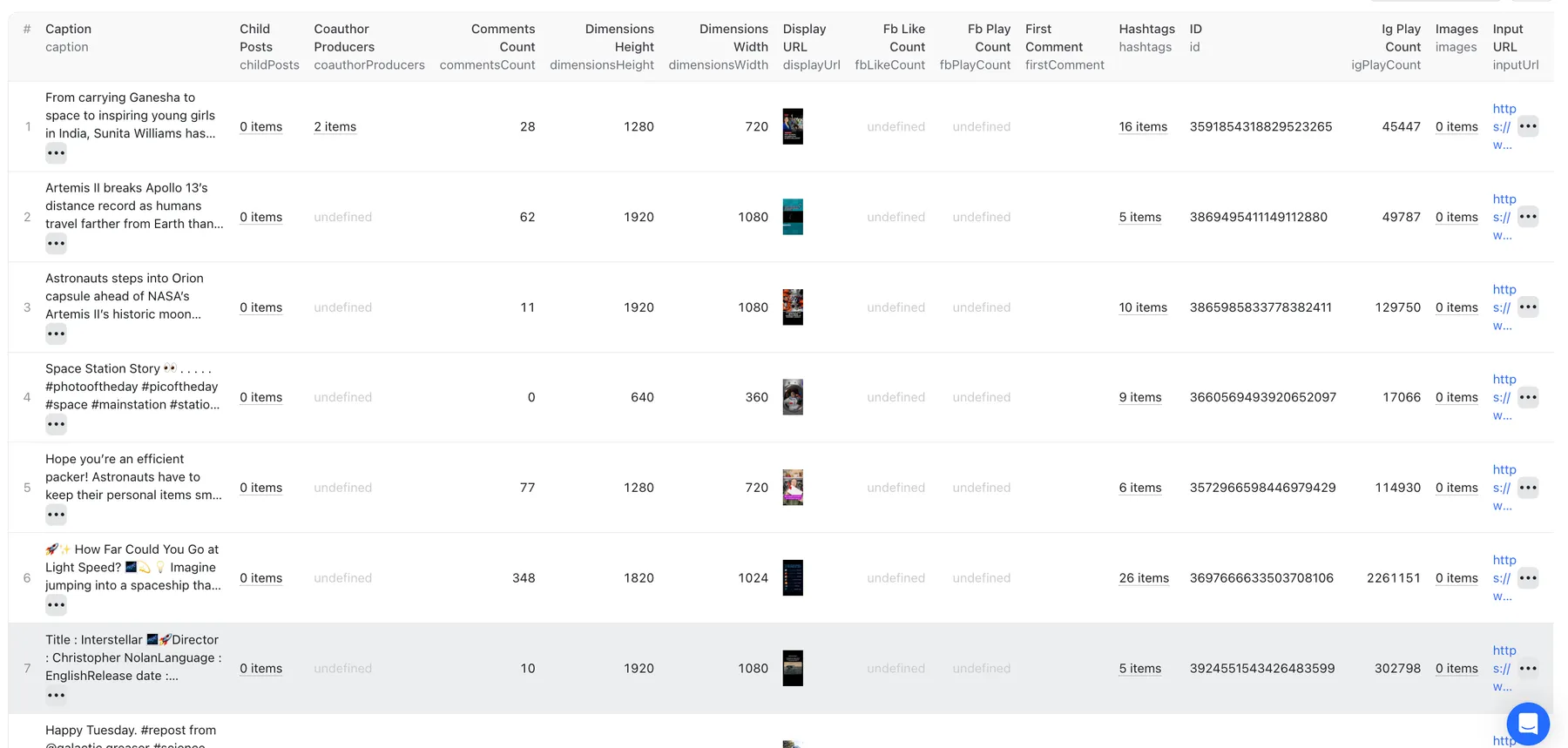
📸 Posts and carousels
Posts and carousels from a profile, hashtag, or place. Note: you can extract posts from a known list of profiles, or you can discover posts by hashtags and places.
Supported URL inputs:
https://www.instagram.com/natgeo/(profile)https://www.instagram.com/197622247/(profile ID)https://www.instagram.com/p/DLNsnpUTdVS/(post)https://www.instagram.com/explore/tags/crossfit/(hashtag)https://www.instagram.com/explore/locations/7538318/copenhagen/(place)
Posts data sample
🎞️ Reels
Reels from a profile, hashtag, or reel page. Note: you can extract reels from a known list of profiles, or you can discover reels by hashtags and places.
Supported URL inputs:
https://www.instagram.com/natgeo/(profile)https://www.instagram.com/humansofny/reels/(reels section)https://www.instagram.com/reel/CigMSGeD4Hd/(single reel)https://www.instagram.com/reels/CigMSGeD4Hd/(plural form)https://www.instagram.com/explore/tags/crossfit/(hashtag)
Or a search query:
searchType: "hashtag", e.g."travel"or"travel, fitness"
Reels data sample
💬 Comments
Comments from a single post or reel. Search queries are not supported for comments; only direct post or reel URLs.
Supported URL inputs:
https://www.instagram.com/p/DN8-GjPkgjS/(post, shortCode)https://www.instagram.com/p/3369450800358839406/(post, ID)https://www.instagram.com/reel/CigMSGeD4Hd/(reel, shortCode)https://www.instagram.com/reel/3515099125383817606/(reel, ID)
Comments data sample
👤 Profile details
Profile metadata: bio, followers, posts count, verified status.
Supported URL inputs:
https://www.instagram.com/nike/(username)https://www.instagram.com/13460080/(profile ID)https://www.instagram.com/humansofny/reels/(reels section)
Profile data sample
📍 Place details
Location metadata: name, coordinates, category, post count.
Supported URL inputs:
https://www.instagram.com/explore/locations/7538318/copenhagen/(with slug)https://www.instagram.com/explore/locations/7538318/(ID only)
Place details sample
🏷️ Mentions
Posts where a profile is tagged. Requires a known profile URL or ID.
Supported URL inputs:
https://www.instagram.com/nike/(profile)https://www.instagram.com/197622247/(profile ID)https://www.instagram.com/humansofny/reels/(profile reels section)
Mentions data sample
#️⃣ Hashtag details
Hashtag metadata: name, post count, related tags, reach tiers.
Supported URL input:
https://www.instagram.com/explore/tags/crossfit/(hashtag)
Hashtag details sample
💈 Place search
Discover Instagram places by keyword. Useful for small business discovery: the search query works best when it combines a city and a local business type, e.g. vintage shop copenhagen.
Search query format:
- Set
searchTypeto"place" - Set
searchto one or more keywords (comma-separated for multiple)
Place search data sample
👥 Profile search
Discover Instagram profiles by keyword. Returns matching users along with their recent posts.
Search query format:
- Set
searchTypeto"profile" - Set
searchto one or more keywords, e.g."nike"or"nike, adidas"(comma-separated for multiple)
Profile search data sample
👁️ Hashtag search
Discover related hashtags by keyword. Useful for finding adjacent or less-saturated tags around a topic.
Search query format:
- Set
searchTypeto"hashtag" - Set
searchto one or more keywords, e.g."travel"or"travel, fitness"(comma-separated for multiple)
Hashtag search data sample
Notes and exceptions
- URL type drives output schema. Hashtag, location, audio, and explore URLs return their respective metadata even when paired with another content mode.
- URLs take priority over search queries; they can't be combined.
- Multiple search words are allowed; you just need to comma-separate them.
- Profile IDs are interchangeable with usernames anywhere a profile URL is accepted.
_uandprofilecardsegments are stripped automatically, soinstagram.com/_u/natgeo/profilecard/works as a profile URL.- Story URLs (
instagram.com/stories/emiliavizcarra/) are reduced to the username before scraping. - Share URLs (
instagram.com/share/BAC6cDeb_-) are resolved to the canonical post URL via a redirect. - Location URLs accept the ID alone, without the trailing slug:
instagram.com/explore/locations/7538318/is valid. - Date filters use UTC.
- Not supported: numeric post IDs in URL form (
instagram.com/p/3369450800358839406/) forposts,reels,mentions, anddetailsmodes. Use the shortCode form. (This format works forcomments.)
What can you do with data after scraping Instagram?
Instagram Scraper is a very versatile tool that can handle hundreds of use cases. Here are a few tips on most common ways people get and interpret public Instagram data:
🎯 Influencer vetting and partnership research
Follower count is a weak signal to find and filter influencer partnerships. Score creators on engagement quality, audience authenticity, and posting consistency instead. Here's how to find and vet Instagram creators using Instagram Scraper:
Recipe:
-
Find creators in your niche. Run
postsorreelswith a hashtag URL likeinstagram.com/explore/tags/fitness/. You'll get a pool of recent posts with creator usernames and engagement numbers. -
Profile each candidate. Run
detailson the profile URLs (or IDs) from step 1 to pull bios, follower counts, verified status, and business category. -
Score real engagement. Run
postsorreelson the top 20–50 profile URLs to compare engagement rates, posting cadence, and format mix. -
Audit audience sentiment. Run
commentson the top-performing post URLs from step 3 to read actual reactions and spot bot patterns.
Re-run steps 2-3 weekly to catch follower drop-offs before signing. Send results to a creator CRM, Google Sheets, or your scoring dashboard.
🔥 Trend tracking and UGC intelligence
Trends move fast on Instagram, and the hashtags that drove reach last quarter rarely do today. Track what's gaining traction, which creators set the pace, and what's already saturated. Here's how to discover trends and UGC using Instagram Scraper:
Recipe:
-
Monitor a target hashtag's content. Run
postsorreelswith a hashtag URL likeinstagram.com/explore/tags/cleanbeauty/to see recent content under the tag and its engagement. -
Measure hashtag size and reach. Run
detailson the same hashtag URL to get post count, posts-per-day, and frequent/average/rare usage buckets. -
Find adjacent, less-saturated tags. Run
detailson the hashtag URL (or a hashtag search query) to surface related tags grouped by reach tier.
Daily runs for fast-moving categories (fashion, beauty, fitness). Weekly runs for steadier verticals (B2B, home, finance). Send output to trend dashboards, content planning tools, or Slack for daily digests.
💯 Competition or campaign monitoring
Track what your competitors post, when they post, and how their audience reacts. The same workflow applies to monitoring your own campaigns. Here's how to track competitors, influencers, or campaigns using Instagram Scraper:
Recipe:
-
Track competitor stats. Run
detailson a competitor profile URL likeinstagram.com/competitor/to capture follower growth, bio updates, and posts count. -
Compare content output. Run
postsorreelson the same profile URL to see engagement rates, top-performing content, and format mix. -
Read audience reactions. Run
commentson the top competitor post URLs from step 2 to hear what their audience actually says. -
Map their hashtag strategy. Run
detailson the hashtag URLs they use to see reach tier and related-tag clusters.
Run weekly. Send results to a competitive intelligence dashboard, a shared sheet, or your strategy doc.
🔔 Brand monitoring and mentions
Instagram doesn't expose comments to search, which makes true real-time brand monitoring harder than on Twitter or Reddit. Combine three angles to get as close as possible. Here's how to work with brand mentions using Instagram Scraper:
Recipe (run all three in parallel, then deduplicate):
-
Catch caption mentions. Run
postswith a search query of your brand name (setsearchTypeto"user") to find posts where your brand appears in the caption text. -
Track branded hashtag UGC. Run
postsorreelswith a branded hashtag URL likeinstagram.com/explore/tags/yourbrand/to capture content from fans, customers, and creators who chose to tag you. -
Capture @-tag mentions. Run
mentionson your own profile URL likeinstagram.com/yourbrand/to find posts where your account is @-tagged.
Combine all three for the widest realistic net. Comments stay out of reach because Instagram doesn't expose comment text to search. Send results to a brand monitoring dashboard, your CRM, or Slack for daily alerts.
🏙️ Local business discovery and lead generation
Many local businesses (salons, restaurants, gyms, boutiques) are active on Instagram but missing from Google Maps, Yelp, and traditional B2B lists. Here's how to find local businesses using Instagram Scraper:
Recipe:
-
Discover places by category and city. Run
detailswith a search query likevintage shop copenhagen(setsearchTypeto"place") to get a list of tagged Instagram places matching your query. -
Get place data. Run
detailson each place URL likeinstagram.com/explore/locations/318767455/to capture coordinates, category, post count, and the linked business profile. -
Enrich with profile info. Run
detailson the linked profile URL from step 2 to pull the business's bio, follower count, contact info, and recent posts.
Use cases include market entry research, competitive mapping, hyper-local partnership prospecting, and CRM enrichment. Export to CSV or send to your CRM via API.
Want to get other data from Instagram?
You can use the other dedicated scrapers below if you want to scrape specific Instagram data:
Want Threads data too? Instagram and Threads share usernames, so the Threads Profile Scraper works the same way.
❓ Frequently Asked Questions
Can I scrape multiple content types in a single run?
No. Each run produces one content type, controlled by the Content to scrape parameter. To collect both posts and comments, run the Actor twice or chain runs via webhooks ot using MCP.
Can I combine URLs and search queries?
No. URLs always take priority over search queries, and they cannot be combined in the same run.
What's the difference between Posts, Reels, and Mentions output?
All three return media items with the same schema. The difference is which items come back: Posts returns the feed of a profile/hashtag/place, Reels filters to reel content (productType: "clips"), and Mentions returns posts where the target profile is tagged.
How many results can I scrape?
It depends on the content type, input, and what Instagram exposes publicly. There's no fixed cap. Open the target URL in an incognito window to see what's available to logged-out users, and test with a small run first. Free plan users are limited to one page of comments per post (~15 comments); paid plans don't have this restriction.
How do I exclude pinned posts?
Set "skipPinnedPosts": true (works with resultsType: "posts"). Two useful combinations:
- Skip old pinned posts, keep recent ones:
"skipPinnedPosts": true+"onlyPostsNewerThan": "1 day"keeps pinned posts from the last day and skips older ones. - Scrape only pinned posts:
"skipPinnedPosts": false+"onlyPostsNewerThan": "0 minutes".
How do I scrape only recent posts?
Use "onlyPostsNewerThan" with resultsType: "posts". Accepted formats:
- Relative:
"1 day","2 months","3 years" - Date only:
"2024-09-05" - Date with time:
"2024-09-05T13:22:04" - Date with time in UTC:
"2024-09-05T13:22:04Z"(theZdenotes UTC) - With milliseconds:
"2024-09-05T13:22:04.123"
Instagram applies UTC internally, so the filter compares against UTC regardless of your local timezone.
Can I scrape the newest comments first?
Yes. Set "isNewestComments": true when resultsType: "comments". Free plans use the default order.
Can I get comment replies?
Yes, on paid plans. Set "includeNestedComments": true when resultsType: "comments". Each reply is returned as a separate result, so the total count will exceed your resultsLimit.
Can I get extra profile statistics?
Set "addProfileStatistics": true when resultsType: "details". This adds a statistics object to each profile result with fields like account type (1 = Personal, 2 = Business, 3 = Creator) and other profile-level data. Works for private profiles too.
Why is likesCount sometimes -1?
When a creator hides the like count on a reel or post, Instagram doesn't expose it. The scraper returns -1 to indicate the value isn't publicly available.
Is it legal to scrape Instagram?
Our social media scrapers only collects data that is publicly available on Instagram. It does not access private content. You should be aware that some public data may be considered personal data under regulations like the GDPR. Only scrape data if you have a legitimate reason. For guidance, see our blog on the legality of web scraping.
Can I integrate Instagram data with other services?
Yes. Scraped Instagram data can be integrated with almost any cloud service or web app. Apify supports Zapier, n8n, Slack, Make, Airbyte, Gumloop, CrewAI, IFTTT, Lindy, GitHub, Google Sheets, Google Drive, and more. You can also use webhooks to trigger actions whenever a run finishes, like sending notifications or syncing datasets.
Can I use Instagram Scraper with the Apify API?
Yes. The Apify API provides programmatic access to run Actors, fetch datasets, monitor performance, and manage tasks. For Node.js, use the apify-client NPM package. For Python, use the apify-client PyPI package. Full API docs are available in the Apify API reference.
Can I get Instagram data through an MCP server?
Yes. You can connect to an MCP server using clients like ClaudeDesktop or LibreChat, or build your own integration. For Instagram Scraper:
- Start a Server-Sent Events (SSE) session to receive a
sessionId. - Send API messages using that
sessionIdto trigger the scraper. - The message starts the Instagram Scraper with the provided input.
- The response should be: Accepted.
Learn more in the MCP setup guide.
Instagram Scraper not working?
The Apify team constantly improves Actor performance. If you find bugs or technical issues, please create an issue on the Actor's Issues tab.