CharityJob.co.uk [Only$1.5💰] Scraper (/w EMAILS)
Pricing
from $1.50 / 1,000 results
CharityJob.co.uk [Only$1.5💰] Scraper (/w EMAILS)
[Only$1.5💰] Scrape UK charity-sector job postings from CharityJob.co.uk — title, salary band, workplace type, employer, posted/closing dates, full description. Works with any search URL, filter combo or single job URL. Optional company enrichment adds website domain and About copy. JSON or CSV out.
Pricing
from $1.50 / 1,000 results
Rating
5.0
(1)
Developer
Muhamed Didovic
Maintained by CommunityActor stats
0
Bookmarked
13
Total users
3
Monthly active users
3 days ago
Last modified
Categories
Share
CharityJob.co.uk Scraper
Turn CharityJob.co.uk into structured job-market data you can actually use. Scrape full job postings — title, salary band, workplace type, employer, closing date, full HTML description — straight from search URLs or single job pages. Optional one-shot organisation enrichment adds the company website domain and "About us" copy. JSON or CSV out, no compute charge per run, just per result.
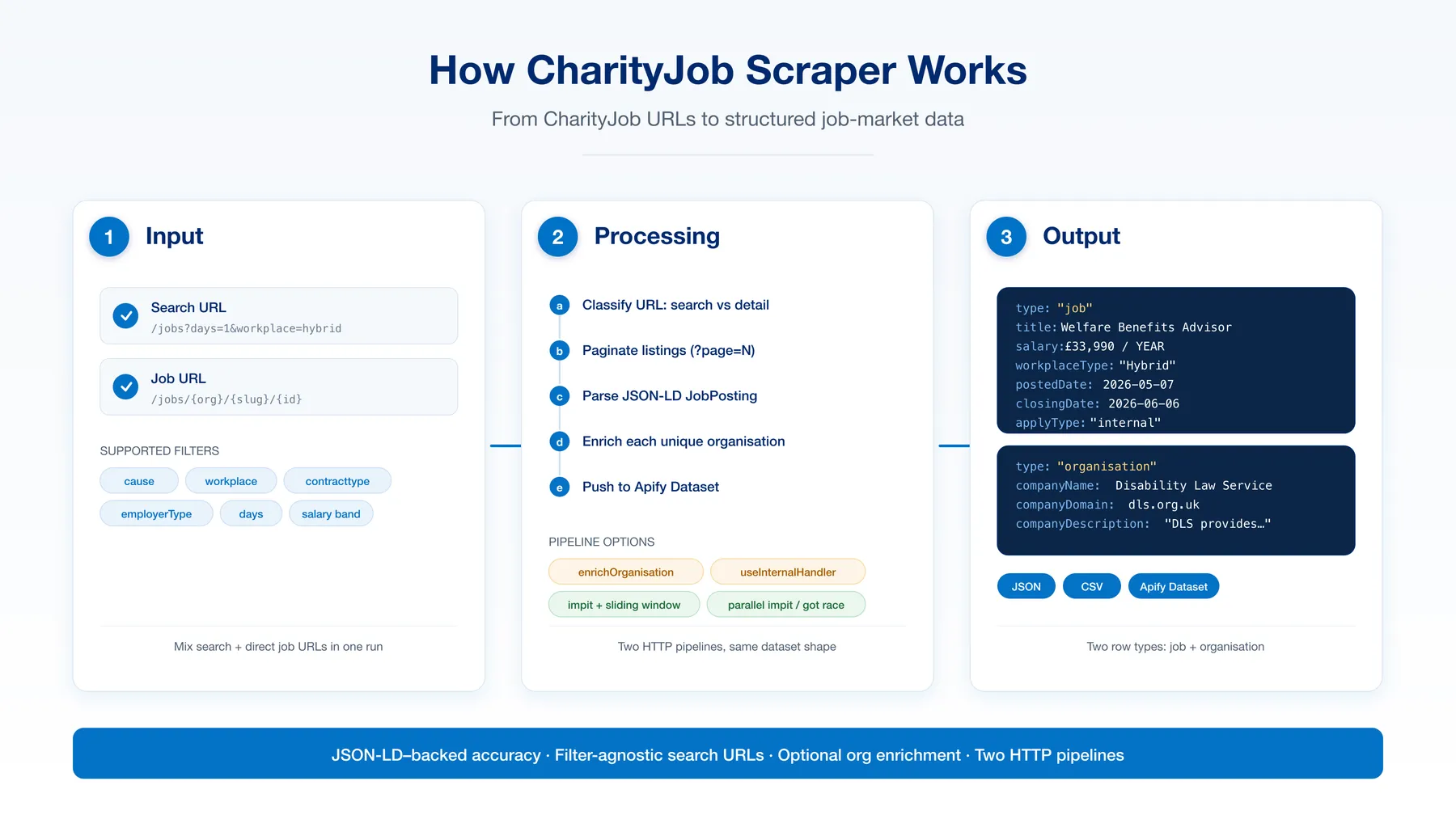
How it works
✨ Why use this scraper?
Trying to track UK charity-sector hiring without paying for a recruitment SaaS? Building salary benchmarks across causes? Need a clean dataset for analysis instead of copy-pasting from job boards?
- 🎯 Two starting points. Paste a CharityJob search URL (any combination of filters supported by the site) or a direct job URL — both classified automatically.
- 📋 JSON-LD–backed accuracy. Title, salary, location, posting/closing dates, employment type, and industries come from the page's
application/ld+jsonblock — same data the site itself ships to Google for Jobs. - 🏢 Optional org enrichment. One extra fetch per unique company adds
companyDescriptionandcompanyDomain, deduplicated across the run. - 🔁 Two HTTP pipelines. Strict impit-only mode (sliding-window concurrency, proxy rotation, parallel impit/got race on tough pages) or
CheerioCrawlerwithImpitHttpClient— switch via one boolean. - 🧰 Filter-agnostic. Cause, workplace, contract type, employer type, salary band, days-since-posted — every CharityJob filter combination just works through the URL.
- 📤 Clean exports. Dataset rows are stable JSON; CSV export is generated automatically at the end of every run.
🎯 Use cases
| Team | What they build |
|---|---|
| Recruitment / agencies | Daily new-vacancy feeds for direct-employer listings, sliced by cause and workplace type |
| Charity-sector analysts | Hiring-trend dashboards across UK third-sector causes (mental health, climate, refugee support, etc.) |
| Compensation & benefits | Salary benchmarks for charity roles by contract type, region, and employer size |
| Talent acquisition (in-house) | Competitive intelligence on what other charities are paying and how they're framing roles |
| Researchers / journalists | Longitudinal datasets on workforce shifts in the UK voluntary sector |
| Job aggregators | Source-of-truth feed of new charity vacancies to ingest into their own platform |
📥 Supported inputs
You can pass two kinds of URL in startUrls. Each URL is classified automatically.
| URL pattern | Behaviour |
|---|---|
https://www.charityjob.co.uk/jobs?<any-filters> | Search — paginates ?page=2, ?page=3, … and fans out to every job link found |
https://www.charityjob.co.uk/jobs/{org-slug}/{job-slug}/{numeric-id} (with or without ?tsId=) | Detail — routed straight to the job parser, no listing crawl |
Filter parameters that map to CharityJob's own URL params (multi-value where supported):
cause, workplace (on-site/hybrid/remote), contracttype (full-time/part-time/permanent/contract/temporary/internship), employerType (direct-employer/recruitment-agency), days (1/3/7/14), minsalary, maxsalary, joblevel, applytype.
Easiest workflow: apply your filters on charityjob.co.uk in the browser, copy the URL out of the address bar, paste into startUrls.
Not supported:
- Volunteer listings (
/volunteer-jobs/...) - Organisation profile URLs as a starting point (they're fetched automatically as enrichment)
- Hosts outside
www.charityjob.co.uk/charityjob.co.uk
🔄 How it works
- Classify each
startUrlas a search URL or a single job URL. - Walk every search result page (
?page=N), collecting unique job links untilmaxItemsis reached or the last page is hit. - Fetch each job detail page, parse the JSON-LD
JobPostingblock + supplementary HTML (workplace label, apply button class, organisation slug). - Enrich each unique organisation once (when
enrichOrganisationis on) by fetching/organisation/{slug}for company description + outbound website domain. - Push to dataset and export — JSON rows during the run, plus
data.csvanddata.jsonat the end.
⚙️ Input parameters
Search
| Parameter | Type | Required | Default | Description |
|---|---|---|---|---|
startUrls | array | * | — | Full charityjob.co.uk URLs (search and/or detail). When provided, filter fields below are ignored. |
cause | array | * | — | One or more cause slugs (human-rights, mental-health, education, …). Used only when startUrls is empty. |
workplace | array | No | — | Multi-select of on-site, hybrid, remote. |
contractType | array | No | — | Multi-select: full-time, part-time, permanent, contract, temporary, internship. |
employerType | string | No | — | direct-employer or recruitment-agency. |
days | string | No | — | 1, 3, 7, or 14 — limits posting age. |
minSalary / maxSalary | integer | No | — | Salary band in GBP. |
* Either startUrls or cause is required. If both are empty the actor will use the schema's default search URL.
Options
| Parameter | Type | Default | Description |
|---|---|---|---|
enrichOrganisation | boolean | true | Fetch each unique /organisation/{slug} page once for companyDescription + companyDomain. |
maxItems | integer | 1000 | Hard cap on jobs collected. Pagination stops when the cap is reached. |
maxConcurrency / minConcurrency | integer | 10 / 1 | Parallel HTTP request limits. |
maxRequestRetries | integer | 5 | Retries before a request is given up. |
proxy | object | Apify residential | Apify proxy configuration. |
📊 Output overview
Each scraped job is one single dataset row. When enrichOrganisation is true, organisation fields (description, domain, headquarters, banner image) are merged into the same row — no separate organisation rows, so the dataset row count equals the job count exactly. For external-apply jobs (CharityJob's "Redirect to recruiter" flow), the actual recruiter URL is captured into externalApplyUrl.
📦 Output sample
One merged row per job (organisation enrichment + external apply URL inline; trimmed to the most useful fields):
🗂 Key output fields
| Group | Fields |
|---|---|
| Identifiers | type, jobId, jobReference (employer's internal ref, when present), jobUrl, scrapedAt |
| Role | title, description (full HTML), industry[], tags[] (job-specific, separate from industry) |
| Dates | postedDate (ISO date), postedDateLabel (human), closingDate (ISO date), closingDateLabel ("24 May 2026 at 23:30"), closingDateTime (precise ISO datetime including cut-off time) |
| Employer | companyName, companyProfileUrl, organisationSlug, organisationType (e.g. Registered Charity), organisationSizeBand (e.g. 501 - 1000), logoUrl |
| Location | location, postcode, addressLocality, addressRegion, country, workplaceType (On-site/Hybrid/Remote) |
| Compensation | salary.{currency,min,max,unit,raw}, employmentType[], contractType, hours |
| Application resources | attachments[] — array of {name, url, type} for PDF/Doc job descriptions, person specs, application packs |
| Apply flow | applyType (internal / external / unknown), applyUrl, externalApplyUrl (resolved recruiter destination for redirect-to-recruiter jobs), agencyContactRestriction (boolean — true when the employer has flagged "no contact from agencies") |
| Accreditations | accreditations[] — known UK employer accreditations detected in the description prose (Disability Confident, Living Wage Employer, Mindful Employer, Investors in People, Stonewall Diversity Champion, B Corp, Race at Work Charter) |
Company enrichment (merged into the same row when enrichOrganisation: true) | companyTagline, companyDescription, companyWebsite, companyDomain, companyHeadquarters.{postcode,country,mapEmbedUrl}, companyBannerImage, companyBenefits[] (e.g. Cycle to work scheme, Enhanced pension, Mental wellbeing support), companyMedia[] (YouTube videos / images from the org's CharityJob profile) |
❓ FAQ
Which CharityJob URLs are supported?
Search URLs (/jobs?...) and single job URLs (/jobs/{org}/{slug}/{id}). Volunteer listings, organisation pages used as starting points, and any host outside www.charityjob.co.uk are skipped.
Does externalApplyUrl show the actual recruiter URL?
Yes — for jobs marked applyType: "external" (CharityJob's "Redirect to recruiter" button), the actor performs a 2-step flow against CharityJob's apply endpoints to retrieve the real recruiter destination (e.g. https://jobs.crisis.org.uk/..., https://app.beapplied.com/apply/...). Internal-apply jobs return applyUrl only.
Can I scrape private pages, premium recruiter listings, or candidate profiles? No. The scraper accesses only publicly available pages — no logged-in content, no recruiter-only views, no candidate data.
How do I limit results?
Set maxItems. Pagination short-circuits as soon as the cap is reached, so a maxItems: 50 run stops fetching listing pages roughly halfway through page 4 (the site shows ~15 jobs per page).
💬 Support
- For issues or feature requests, please use the Issues tab on the actor's Apify Console page.
- Author's website: https://muhamed-didovic.github.io/
- Email: muhamed.didovic@gmail.com
🛠 Additional services
- Custom output shape, additional fields, or one-off datasets: muhamed.didovic@gmail.com
- Need this scraper customised, or want a similar scraper for TotalJobs / other UK job boards? Drop an email.
- For API access (no Apify fee, just a usage fee for the API): muhamed.didovic@gmail.com
🔎 Explore more scrapers
If this CharityJob.co.uk Scraper was useful, see other scrapers and actors at memo23's Apify profile — covering job boards, real estate, social media, and more.
⚠️ Disclaimer
This Actor is an independent tool and is not affiliated with, endorsed by, or sponsored by CharityJob.co.uk or any of its operators, subsidiaries, or affiliates. All trademarks mentioned are the property of their respective owners.
The scraper accesses only publicly available job-listing and organisation-profile pages — no authenticated endpoints, recruiter-only features, candidate accounts, or content behind the charityjob.co.uk login wall. Users are responsible for ensuring their use complies with charityjob.co.uk's Terms of Service, applicable data-protection law (GDPR, CCPA, etc.), and any contractual obligations of their own organisation.
SEO Keywords
charityjob scraper, scrape charityjob, charityjob api, charityjob.co.uk scraper, Apify charityjob, charity jobs scraper, nonprofit jobs scraper, third sector jobs scraper, uk charity jobs data, charity sector hiring data, charity salary benchmarks, nonprofit recruitment data, charity vacancies api, fundraising jobs scraper, policy jobs scraper, mental health jobs uk, uk job board scraper, charity recruitment intelligence, third sector talent pipeline, voluntary sector hiring trends, totaljobs alternative scraper