Crunchbase — 100K+ Instant Company DB, Funding Monitor ($8/1k)
Pricing
from $8.00 / 1,000 results
Crunchbase — 100K+ Instant Company DB, Funding Monitor ($8/1k)
Crunchbase two ways: live scrape (one clean row per company — funding, people, M&A, tech stack, predictions, Cloudflare handled) or the ⚡ Instant Database — 100K+ profiles served in seconds with country/size/status filters. Funding Monitor returns only NEW rounds per scheduled run. $8/1k.
Pricing
from $8.00 / 1,000 results
Rating
0.0
(0)
Developer
Muhamed Didovic
Maintained by CommunityActor stats
1
Bookmarked
41
Total users
13
Monthly active users
2 hours ago
Last modified
Categories
Share
Crunchbase Scraper — Startup Investors Database, Companies + Funding Rounds
How It Works
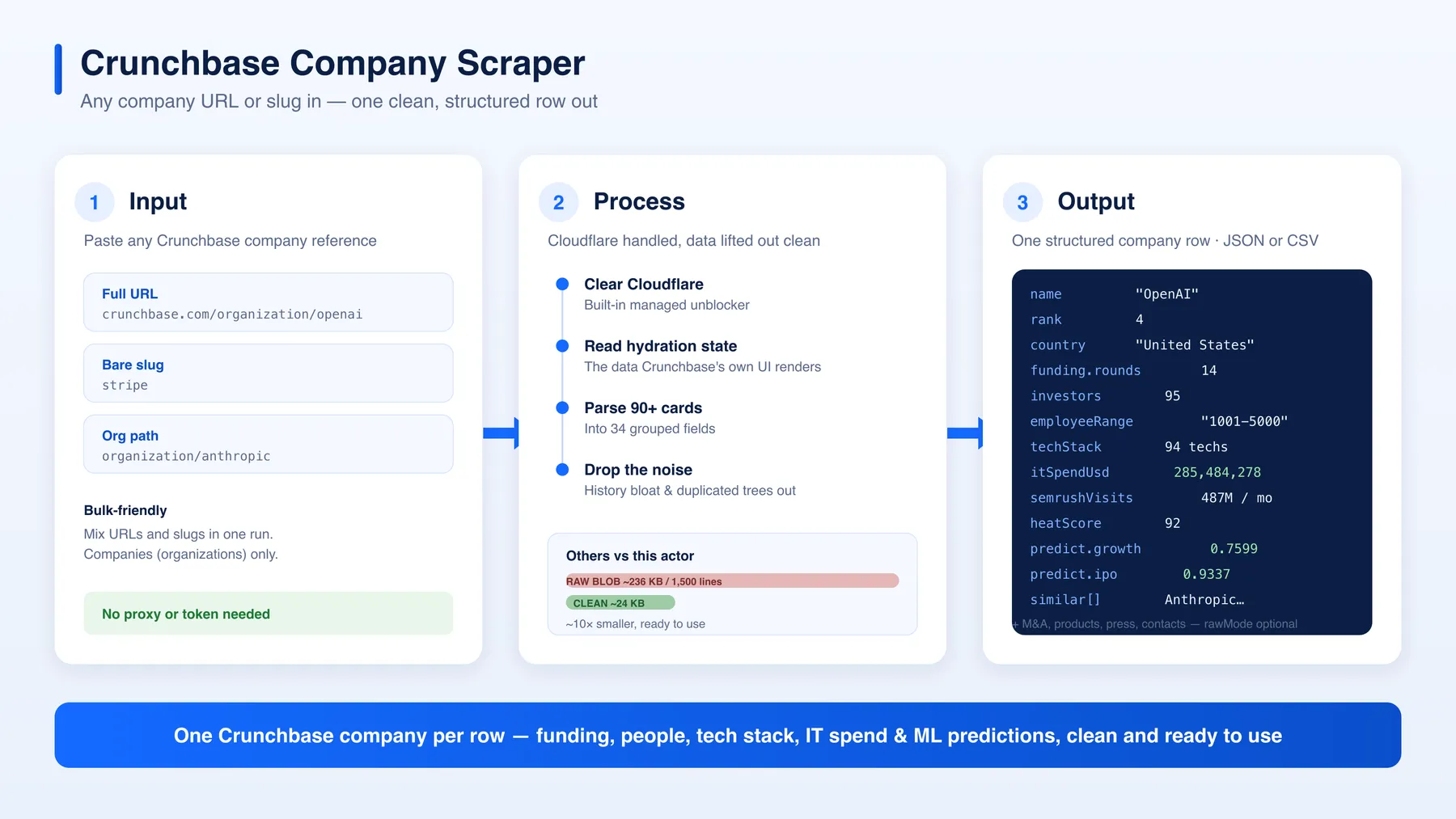
Turn any Crunchbase company URL or slug into one clean, structured row — no raw blob to untangle.
Paste a company link, a bare slug, or an organization/... path and get a ready-to-use profile: identity, funding, people, M&A, tech stack, web traffic, IT spend, and Crunchbase's own growth/funding/acquisition/IPO predictions.
Or paste a Crunchbase Discover / saved-search URL (e.g. crunchbase.com/discover/funding_rounds/…) and get one funding-round signal row per result — company, round type, and Crunchbase links — with each company enriched from its org page.
JSON or CSV out. No unblocker token to manage — Cloudflare is handled for you.
💼 NEW: Startup Investors Database — 19,000+ VC firms, accelerators & angels
Flip on investorDatabase (or set any investor filter) and the actor returns investor firm rows instead of companies: 19,000+ venture capital firms, accelerators, angel investors, family offices and grant programs, each derived from live Crunchbase funding-round participation — not a stale directory dump:
- Who they are — firm name, Crunchbase URL, inferred type (VC / Seed & Early-Stage VC / Accelerator / Angel / Grant Program / Debt), and where available HQ city + country, website, contact email, phone, description, Crunchbase rank
- How they invest — observed deal count, full stage distribution (Pre-Seed → Series D+, Grants, Debt), top stage, focus areas (industries of their actual portfolio), portfolio countries
- What they've backed — the portfolio companies themselves, with Crunchbase permalinks, ready to cross-reference against the 100K+ company database below
- Filter by name/keyword, firm type, investment stage, focus area (e.g.
Artificial Intelligence (AI),Biotechnology), country, and minimum deal count
Perfect for fundraising target lists ("US seed-stage VCs active in AI"), B2B sales to investment firms, and VC market research. Contacts are included in the row price — no per-contact surcharge, and every run logs a cost preview before a single row is billed, so you always know the bill up front. A full 19K-firm export costs ~$155; a targeted 1,000-firm list ~$8.
⚡ NEW: Instant Company Database — 100,000+ companies, zero scraping
Flip on instantDatabase (or just set any DB filter) and the actor answers from its continuously-growing database of 100K+ Crunchbase company profiles — instantly, no crawling, no waiting:
dbQuery: "ai"→ 16,446 matching companies · served in seconds · full clean profile per row (funding, people, tech stack, predictions) · filter by country, employee range, operating status, ranked by Crunchbase rank.
Every row carries source: 'instant-db' plus the date it was last refreshed. Perfect for lead lists, market sizing and enrichment backfills where "right now" beats "freshly crawled".
📡 NEW: Funding Monitor — only what's new since your last run
Turn on fundingMonitor and schedule the actor: the first run builds a baseline, and every following run with the same input returns only new funding rounds / companies — no duplicates, no re-paying for rows you already have (skipped rows are never charged). Point it at a Discover funding-rounds search on a schedule and you have a just-funded-companies alert feed: freshly funded = hiring, buying tools, warm B2B lead.
Why Use This Scraper?
- ✅ Clean structured output — 34 grouped fields, ready for a spreadsheet or a model, not a 1,500-line raw dump
- ✅ Two modes in one actor — company-page enrichment and Discover/saved-search funding-round signals
- ✅ One row per company — paste a URL, a slug, or a path and get a single tidy profile back
- ✅ Surfaces the buried gold — Aberdeen IT spend, SEMrush traffic, BuiltWith + Siftery tech stack, Crunchbase ML predictions
- ✅ Cloudflare handled for you — built-in managed unblocker, nothing to configure
- ✅ Optional raw passthrough — flip one switch to also get the full unprocessed Crunchbase cards
- ✅ Flat JSON / CSV export for analysis, CRM enrichment, or lead scoring
Overview
The Crunchbase Company Scraper is built for sales and revenue teams, investors and analysts, market researchers, and data engineers who need structured company intelligence from Crunchbase without paying for an enterprise API seat.
The actor runs in two modes. Company mode is the core: each company input — a full URL, a bare slug, or an organization/... path — resolves to exactly one company-shaped row (investor names, executives, acquisition targets, and funding-round counts all appear nested inside it). Discover mode is optional: paste a Crunchbase Discover / saved-search URL and the actor returns one funding-round signal row per result (company + round type + Crunchbase links), with each company enriched from its org page. It is not a people- or investor-search crawler.
Most Crunchbase actors on the Store dump the raw cards object Crunchbase ships to its own front-end: roughly 236 KB and 1,500 lines per company, full of 540-element history arrays, ten-times-duplicated competitor trees, and internal query stubs. This actor returns a clean ~24 KB structured row instead — about 10× smaller — with the noise dropped and the useful signals lifted to the top level. If you still want everything, rawMode adds the full cards back as a passthrough field.
Supported Inputs
Input types
| Input type | Pattern | Example |
|---|---|---|
| Full company URL | https://www.crunchbase.com/organization/{slug} | https://www.crunchbase.com/organization/openai |
| Bare slug | {slug} | stripe |
| Organization path | organization/{slug} | organization/anthropic |
Copy-pasteable startUrls
Discover / saved-search URLs (funding-round signals)
Paste a Crunchbase Discover URL — https://www.crunchbase.com/discover/<collection>/<hash> (e.g. a saved Funding Rounds search) — and the actor switches to signal mode for that input: one row per result with the funding round, round type, funded company, and Crunchbase links, each company enriched from its org page.
Anonymous cap: Crunchbase returns the first 15 results per search to anonymous callers and gates the funding amount, announced date, investors, and pagination beyond 15 behind a paid login. So signal rows carry company + round type + links; the
$amount/date come through only in optional logged-in mode with a Crunchbase Pro session. Need a tighter list? Narrow the saved search itself.
Unsupported inputs
- ❌ Person profiles —
crunchbase.com/person/{slug} - ❌ Individual funding-round, acquisition, investor, hub, or event entity pages —
crunchbase.com/funding_round/...,/acquisition/...(the Discover saved-search URL above is supported) - ❌ Ad-hoc search pages with no saved-search hash — save the search first to get a
/discover/<collection>/<hash>URL - ❌ Any host outside
crunchbase.com
Use Cases
| Audience | Use case |
|---|---|
| Sales / RevOps teams | Enrich CRM accounts with funding stage, headcount band, tech stack, and IT spend for lead scoring |
| Investors / analysts | Pull funding history, investor lists, and Crunchbase growth/IPO predictions for deal sourcing |
| Market researchers | Bulk-export competitor sets with categories, rank, and web-traffic signals |
| Data / growth engineers | Feed clean company rows into a warehouse or model without writing a Crunchbase parser |
| Agencies | Deliver client-ready company datasets without an enterprise Crunchbase license |
- Input — provide Crunchbase company URLs, slugs,
organization/...paths, or a Discover/saved-search URL - Unblock — each page is fetched through a built-in managed unblocker that clears Crunchbase's Cloudflare protection
- Extract — the actor reads Crunchbase's own hydration state (the data its front-end renders from) for complete, accurate fields
- Structure — raw cards are parsed into one clean, grouped row; history bloat and duplicated trees are dropped
- Output — export as structured JSON or flattened CSV, with optional
rawModefor the full unprocessed cards
Input Configuration
Input fields
| Field | Type | Required | Notes |
|---|---|---|---|
startUrls | array<string> | yes | Crunchbase company URLs, slugs, organization/... paths, or Discover/saved-search URLs (/discover/<collection>/<hash>) |
rawMode | boolean | optional | When true, also include the full raw Crunchbase cards as _rawCards. Default false |
maxItems | integer | optional | Hard cap on company rows emitted. Default 1000 |
maxConcurrency | integer | optional | Parallel unblocker requests. Default 3 (keep low — the premium pool is metered per success) |
maxRequestRetries | integer | optional | Retries on transient unblocker errors before giving up on a company. Default 2 |
sdoKey | string (secret) | optional | Leave blank — the actor uses its built-in unblocker by default. Advanced: paste your own scrape.do token to bill unblocker requests to your own account |
crunchbaseCookie | string (secret) | optional | Logged-in mode. Paste your own Crunchbase Cookie header to unlock the gated funding amount / date / investors on Discover results and lift the 15-result cap. Requires a Crunchbase Pro account; the session expires every few minutes, so it's for manual one-off runs, not scheduled jobs. Leave blank for anonymous signal mode — a free or stale cookie safely falls back to anonymous instead of erroring |
proxy | object | optional | Reserved for a future direct-fetch path; not required for normal runs |
Common scenarios
1. A few companies, clean output
2. Clean row plus the full raw cards
3. A larger batch with a cap
4. A Discover / saved-search URL (funding-round signals)
Output Overview
Each dataset item is a single company row containing:
- Identity — name, permalink, UUID, description, type, operating status, IPO status, global rank, aliases
- Location — city, region, country, continent, offices
- Web & contact — website, LinkedIn / Facebook / Twitter, contact email, phone, contact count
- Categories — category tags and per-category rank
- Funding — total (when public), round count, investor count, rounds, investor list
- People — employee band, current executives, advisors/board, alumni
- M&A — acquisitions, acquired-by, exits, IPO fields
- Tech stack — technology count, BuiltWith stack, Siftery products
- Signals — heat score, SEMrush traffic, Aberdeen IT spend, mobile apps
- Predictions — Crunchbase ML scores for growth, funding, acquisition, IPO
- Products / Similar / Press — products, similar companies with similarity score, recent press timeline
Some fields are null when Crunchbase no longer ships them on the default page load (see FAQ). Set rawMode: true to additionally receive the full unprocessed cards as _rawCards.
Output Samples
Bare slug start ("openai") — trimmed
Discover search start (".../discover/funding_rounds/...") — one signal row per result, trimmed
Key Output Fields
Identity
name,permalink,uuid,url,descriptionoperatingStatus,companyType,ipoStatus,rank,aliases[]
Location & contact
city,region,country,continent,offices[]website,socials.linkedin,socials.facebook,socials.twitter,contactEmail,phone
Categories & funding
categories[].name,categoryRanks[].rankfunding.totalUsd,funding.numFundingRounds,funding.numInvestors,funding.investors[],funding.rounds[]
People & M&A
people.employeeRange,people.current[],people.advisors[],people.alumni[],numContactsma.acquisitions[],ma.acquiredBy,ma.exits[],ma.ipo
Tech stack & signals
techStack.numTechnologies,techStack.builtwith[],techStack.siftery[]signals.heatScore,signals.semrush.monthlyVisits,signals.aberdeenItSpendUsd,signals.apps
Predictions, products & press
predictions.growth,predictions.funding,predictions.acquisition,predictions.ipo(each{ score, tier, generatedOn })products[],similar[].score,pressTimeline[]
FAQ
Which Crunchbase URLs are supported?
Two kinds. Company (organization) pages — a full URL (https://www.crunchbase.com/organization/openai), a bare slug (openai), or a path (organization/openai) → one company row each. And Discover / saved-search URLs (https://www.crunchbase.com/discover/<collection>/<hash>) → one funding-round signal row per result. Individual person, funding-round, acquisition, investor, hub, and event entity pages are not supported as inputs.
What do Discover / saved-search URLs return?
One row per search result: the funding round, round type (investmentType), funded company, Crunchbase links, and a gatedFields marker — with the company enriched from its org page under company. Anonymous runs return the first 15 results and leave the $ amount, announced date, and investors null (Crunchbase gates those behind a paid Pro login). To unlock them, supply a Pro session via crunchbaseCookie — see below.
Do I get company rows or people / investor rows?
Company inputs give company rows — one per input. Discover / saved-search inputs give funding-round signal rows — up to 15 per search — each with the company enriched under company. In those two modes, people, investors, and acquisition targets appear as nested fields (e.g. people.current[], funding.investors[], ma.acquisitions[]). To get investor firms as their own rows — one per VC / accelerator / angel / grant program, with deal counts, stages, focus areas, portfolio and contacts — turn on investorDatabase (see the Startup Investors Database section above).
How is the Startup Investors Database priced vs. dedicated "investor database" actors?
Every investor firm row is a normal result row at $8/1k ($0.008 per firm), contacts included. Dedicated investor-database actors on the Store commonly charge $0.04 per firm plus $0.02 per contact — 5–7× more for a comparable row. The run log prints a cost preview (💰 Cost preview: this run will bill ≈ $…) before rows stream out, so there are no billing surprises.
Do I need a proxy or an unblocker token?
No. Crunchbase is Cloudflare-protected, but the actor ships with a built-in managed unblocker, so a normal run needs nothing extra. The optional sdoKey field only exists for advanced users who want to bill unblocker requests to their own scrape.do account.
Why are funding.totalUsd and signals.semrush.globalRank sometimes null?
Crunchbase moved a few fields (notably total funding amount and the SEMrush global rank) behind a secondary request that no longer ships on the default page load. Rather than double the per-company cost, the actor returns these as null and populates everything else — round counts, investor counts, SEMrush monthly visits, IT spend, predictions, and the full tech stack all still come through.
What does rawMode do?
When true, each row keeps all the clean structured fields and adds _rawCards — the full, unprocessed Crunchbase cards object. Use it when you need a field the structured output doesn't surface. It makes rows roughly 10× larger, so leave it off unless you need it.
What's gated, and can logged-in mode unlock it?
By default the actor reads only public Crunchbase data, so Discover funding amounts / dates / investors and a few company fields (e.g. funding.totalUsd) come back null, and each search returns its first 15 results. Those are gated by Crunchbase behind a paid Pro login — a Crunchbase limit, not a scraper one. The optional crunchbaseCookie field lets you supply your own logged-in Crunchbase Pro session to unlock them. Caveat: the session token expires every few minutes, so it suits manual one-off runs, not scheduled jobs — and a free-tier or stale cookie simply falls back to the public signal output instead of erroring. Leave it blank for normal public runs.
How is it priced and how fast is it?
Each company is one dataset item and one unblocker request, billed per result (see the Apify Store pricing on this actor's page). In testing, batches run at a few companies per second with default concurrency.
Support
- For issues or feature requests, use the Issues tab of this actor.
- For customization or questions, contact the author:
- Website: https://muhamed-didovic.github.io/
- Email: muhamed.didovic@gmail.com
- All my Apify actors: https://apify.com/memo23
Additional Services
- Need a custom export shape, additional Crunchbase fields, or scheduled monitoring? Email muhamed.didovic@gmail.com.
- For a direct API of this scraper (no Apify fee, usage-based), contact the same address.
Explore More Scrapers
If you found this useful, you might also like:
- Pinterest Scraper — structured pin, board, and profile data
- More company & web-data actors — directory, jobs, reviews, and social scrapers
Full list at apify.com/memo23.
⚠️ Disclaimer
This Actor is an independent tool and is not affiliated with, endorsed by, or sponsored by Crunchbase, Inc. or any of its subsidiaries. All trademarks mentioned are the property of their respective owners.
By default the scraper accesses only publicly available Crunchbase pages — no authenticated endpoints or content behind the crunchbase.com login wall. The optional logged-in mode is opt-in and uses your own Crunchbase session and subscription that you choose to supply; if you enable it, you are responsible for using it within your own Crunchbase account terms. Users are responsible for ensuring their use complies with Crunchbase's Terms of Service, applicable data-protection law (GDPR, CCPA, etc.), and any contractual obligations of their own organization.
SEO Keywords
crunchbase scraper, scrape crunchbase, crunchbase company scraper, crunchbase API, crunchbase.com scraper, Apify crunchbase, company data scraper, company funding scraper, startup data scraper, tech stack scraper, firmographic data, company enrichment data, lead enrichment scraper, investor data scraper, market research data, competitive intelligence scraper, sales prospecting data, company profile API, business intelligence scraper, startup funding data, crunchbase funding rounds scraper, crunchbase discover scraper, funding round data, startup funding rounds, saved search scraper, startup investors database, startup investor data scraper, VC database, venture capital firms database, VC firms list, angel investors list, investor contacts database, find investors for startup, investor leads, accelerator list, seed investors database, VC deal data, investor portfolio data, fundraising target list, investor firm database