Google News Scraper · Full Article Bodies + Entities
Pricing
from $2.50 / 1,000 results
Google News Scraper · Full Article Bodies + Entities
Scrape Google News with full publisher article bodies, not just snippets. Decodes the CBM redirect to the publisher page, extracts Article JSON-LD (title, body, author, image, keywords), and runs entity extraction (orgs/tickers/locations). 4 input kinds. Flat per-article billing. Pure HTTP
Pricing
from $2.50 / 1,000 results
Rating
5.0
(1)
Developer
Muhamed Didovic
Maintained by CommunityActor stats
0
Bookmarked
19
Total users
18
Monthly active users
5 days ago
Last modified
Share
Google News Scraper — Articles, Bodies & Entities
How it works
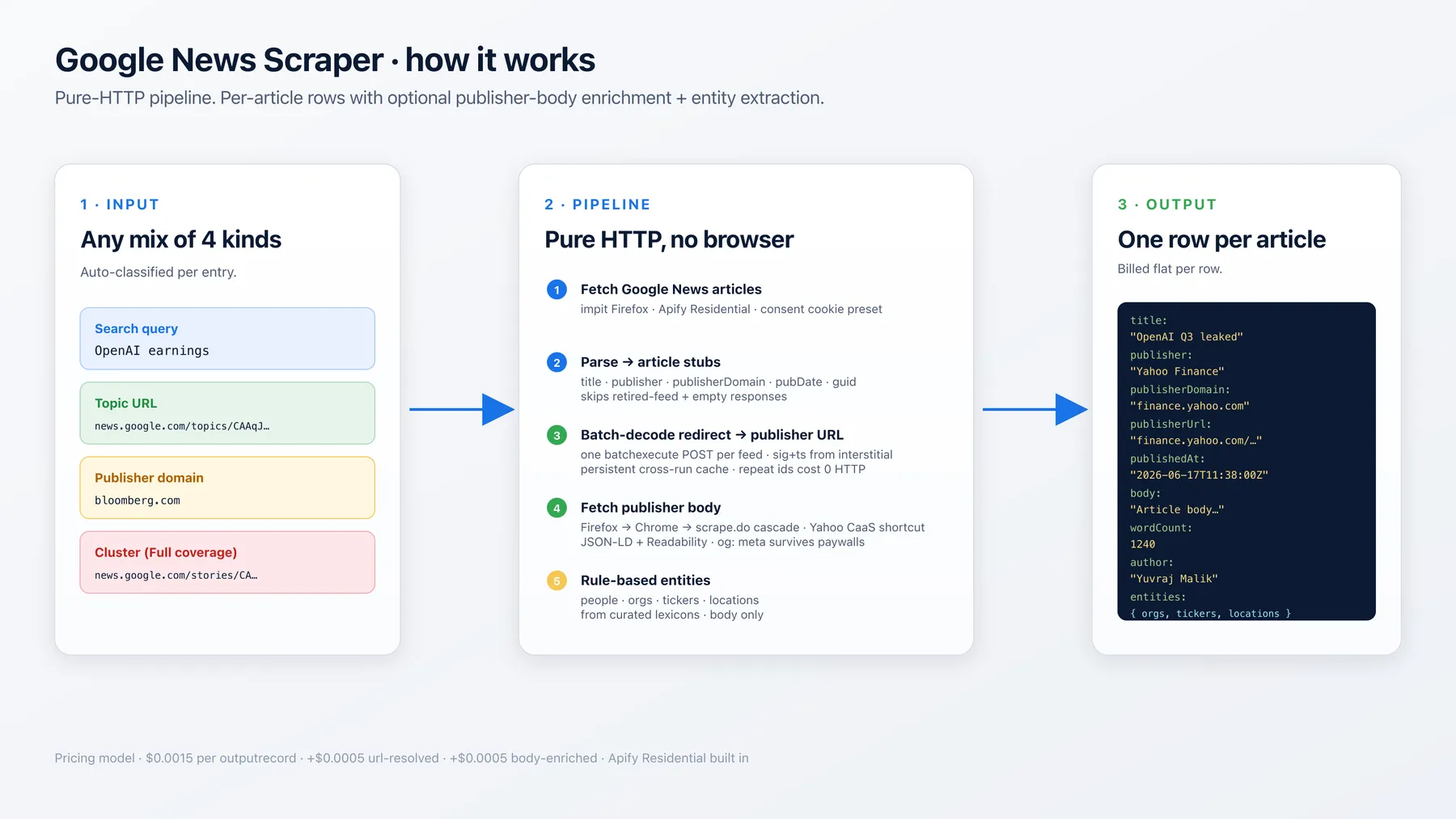
All-in-one Google News scraper. Paste any mix of search queries, topic URLs, publisher domains, or Full-coverage cluster URLs — the actor auto-classifies each input and emits one structured row per article. Optional follow-through resolves the Google News redirect to the real publisher URL and extracts the full article body, headline, author, section, image, and keywords from Article / NewsArticle JSON-LD (with a readability-style fallback when JSON-LD is missing).
| Input kind | Example | Becomes |
|---|---|---|
| Search query | OpenAI earnings | RSS feed for that query |
| Topic URL | https://news.google.com/topics/CAAqJ… | RSS feed for that topic |
| Publisher domain | bloomberg.com | RSS feed for site:bloomberg.com |
| Cluster (Full coverage) | https://news.google.com/stories/CA… | RSS feed for that story + nested clusterAggregate per row |
One row per article. JSON + CSV. Pure HTTP, no Puppeteer / Playwright / headless Chromium / third-party paywall-bypass service.
Why use this Google News scraper
- All four URL kinds in one actor. No need to glue together a query scraper + topic scraper + publisher scraper — one input list, auto-classified.
- Full publisher article body, not just snippets. Google News only shows ~150-character snippets. Most competitor actors stop there. We resolve each Google News redirect (via the same
batchexecutecall Google's own client uses — no JS execution required) and extract the canonical body from the publisher'sArticleJSON-LD. - Structured entity extraction built in. Rule-based extraction of orgs / tickers / locations from curated lexicons (~zero false positives). Lives on every body-enriched row at no extra cost.
- Flat per-article billing. One article = one row = one result. Buyer cost is
rows × per-result-price— no nested-array math. - Locale-aware. Pass
country+languageto scope the feed (e.g.country: "DE", language: "de"for German news). Time-window filters (since/until) drop articles outside the date range before they hit your billing.
Overview
| Field | Detail |
|---|---|
| Source | news.google.com (RSS feeds) + publisher pages (when enrichBody:true) |
| Pricing | $0.0025 per article (result) · +$0.0005 url-resolved · +$0.0005 body-enriched (Cloudflare/Akamai bypass included free) |
| Anti-bot | None on Google News RSS · walled publishers (Bloomberg/FT/WSJ/Yahoo) bypassed automatically |
| Runtime | ~1-3 s per RSS query (100 articles per feed) · ~2-3 s extra per body-enriched article |
| Output | JSON + CSV, one row per article |
| Scope | Global · all Google News locales (country + language params) |
Supported Inputs
The actor accepts every entry in your input list and auto-classifies it as one of four kinds. Mix and match freely.
| Input | Example | What you get |
|---|---|---|
| Search query (bare string) | OpenAI earnings | Up to 100 articles matching the query, ordered by Google News relevance |
| Search query (URL) | https://news.google.com/search?q=OpenAI+earnings | Same as above — URL form is canonicalised |
| Topic URL | https://news.google.com/topics/CAAqJ… | The most recent articles in that topic feed |
| Publisher domain | bloomberg.com / www.bloomberg.com | Up to 100 most recent Google-News-indexed articles from that publisher |
| Cluster URL (Full coverage) | https://news.google.com/stories/CA… | Every article in the cluster + nested clusterAggregate per row (source count, languages, first-seen timestamp) |
Use Cases
| Buyer | Why they want this |
|---|---|
| RAG pipeline operators | Need clean full-body articles with stable IDs and timestamps — much cleaner than scraping each publisher directly. |
| Brand & competitor monitoring | Track every mention of a brand across all news outlets — paste the brand as a query, get all coverage. |
| Financial / equity research | Per-article ticker + org extraction, time-window filtering, full body for sentiment models. |
| Newsroom / media analysis | Track topic clusters ("Full coverage") to measure how many distinct publishers covered a given story. |
| Compliance / regulatory monitoring | Filter by since / until to catch news within a reporting window. |
| Sentiment / topic-modelling researchers | One actor produces both the SERP-level metadata (publisher, date, language) and the body content needed for downstream NLP. |
How It Works
Google News is Cloudflare-free for the RSS feeds we use. The actor breaks past the typical pitfalls of news scraping with a pure-HTTP pipeline:
- Resolve inputs to RSS feeds. Every URL kind (search / topic / publisher / cluster) has a
/rss/...variant. The classifier emits the canonical RSS URL and the rest of the pipeline only deals with that. - Fetch RSS via impit Firefox + Apify Residential US. First-attempt 200 OK; no warmup, no rotation.
- Parse RSS into per-article stubs. Each item gives us
title,googleNewsUrl(Google's redirect),pubDate,publisher,publisherDomain(via<source url>), andguid. - Decode the Google News redirect → publisher URL (when
enrichBody:true). The CBM token in the Google News URL is base64-encoded protobuf with no plaintext URL inside — but we can call the same/_/DotsSplashUi/data/batchexecuteendpoint Google News' own JS client uses, passing the signature + timestamp scraped from the interstitial. Zero browser, zero JS execution. - Fetch the publisher article + extract canonical fields.
Article/NewsArticle/BlogPostingJSON-LD when present (most major publishers ship this); readability-style heuristic over<article>,<main>,[itemprop="articleBody"]when not. - Run rule-based entity extraction. Curated lexicons for orgs and locations + regex for stock tickers. High precision, low false-positive rate.
Cluster URLs additionally produce a denormalised clusterAggregate (source count, languages, first-seen) on every row from that cluster — useful for measuring story spread.
Input Configuration
| Field | Type | Required | Notes |
|---|---|---|---|
startInputs | string[] | yes | Any mix of search queries, Google News URLs (search / topic / cluster), or publisher domains. Auto-classified. |
maxItems | integer | no | Safety cap on total dataset rows. Default 500. Free-tier users are capped at 50. |
maxArticlesPerInput | integer | no | Per-input cap. RSS feeds return up to ~100 articles. Default 100, 0 = no per-input cap. |
enrichBody | boolean | no | Follow each Google News redirect to the publisher and extract full body + Article JSON-LD. Default false. Charges an extra body-enriched event per article. |
extractEntities | boolean | no | Rule-based entity extraction (orgs / tickers / locations). Defaults to true when enrichBody is on, false otherwise. |
country | string | no | Google News country code (gl=). Default US. |
language | string | no | Google News language code (hl=). Default en. |
since | string | no | ISO date (YYYY-MM-DD). Drops articles older than this. |
until | string | no | ISO date. Drops articles newer than this. |
proxy | object | no | Apify Residential US recommended (and is the default). Google News is open enough that datacenter proxies usually work too, but residential keeps you out of edge-case rate-limits. |
Example input
That input yields one row per matched article (up to ~100 across all three inputs), each with the full publisher body, author, section, image, and rule-based entities.
Output Overview
One row per article, with the rowType discriminator set to "news-article". Same shape regardless of which input kind produced it (cluster URLs add a clusterAggregate nested object; all other kinds leave it null).
Output Samples
Cluster-URL rows include a populated clusterAggregate:
Key Output Fields
| Field | Type | Always populated? | Notes |
|---|---|---|---|
title | string | ✅ | Cleaned title — the trailing - Publisher suffix from Google News titles is stripped. |
publisher | string | null | usually | Human-readable publisher name (Yahoo Finance, Bloomberg). |
publisherDomain | string | null | usually | Hostname only, www. stripped (finance.yahoo.com). |
googleNewsUrl | string | ✅ | The Google News redirect URL — the stable identifier across runs. |
publisherUrl | string | null | when enrichBody:true | The resolved publisher article URL. |
publishedAt | string | null | usually | ISO 8601 timestamp. |
guid | string | null | usually | Google's per-article ID — useful for deduping across runs. |
body | string | null | when enrichBody:true and publisher isn't paywalled | Plain text, whitespace-normalised. |
wordCount | number | null | when body is present | Whitespace-split count. |
author | string | null | when JSON-LD ships it | Comes from Article.author.name. |
entities.orgs / .tickers / .locations | string[] | when extractEntities:true | Lexicon-checked — very low false-positive rate. |
entities.people | string[] | reserved | Always [] in v0.1 — rule-based Capitalised-Bigram NER is too noisy to ship. A real NER path is on the v1.1 roadmap. |
clusterAggregate | object | when sourceKind === "cluster" | null otherwise. |
FAQ
Q: Why don't all articles get a body extracted?
A: Some publishers (Bloomberg, WSJ, FT, NYT premium tier) are hard-paywalled — the article URL renders an empty body or a login wall. We surface this honestly: bodyExtracted: false and body: null for paywalled articles. The Google News URL, publisher name, headline, and date are always present.
Q: How fresh is the data? A: RSS feeds are Google's live index — typically articles appear within 5-15 minutes of publication. No caching on our side.
Q: Will scraping the same query twice return duplicates?
A: Filter on guid (or googleNewsUrl) to dedupe across runs — both are stable per-article identifiers.
Q: What happens if I pass a query with no results?
A: The RSS feed returns 0 items, the actor logs 0 eligible items, no rows emitted, no events charged.
Q: Does the publisher follow-through use my Apify proxy credits twice?
A: Yes — one HTTP hop to resolve the CBM redirect via batchexecute, one hop to fetch the publisher page. Apify Residential bytes scale linearly with enrichBody:true. Most publisher pages are 200-500 KB.
Q: Why is the people array always empty?
A: Rule-based "Capitalised Bigram" detection produces too many false positives ("Microsoft Just", "Strong Buy") to be useful at scale. We intentionally skip it in v0.1. Proper NER (via LLM) is on the v1.1 roadmap.
Q: How is the date window enforced?
A: since and until are applied AFTER the RSS feed is fetched but BEFORE rows are emitted, so you only pay for articles inside your window.
Q: Can I scrape Google News in another language?
A: Yes — set country: "DE", language: "de" for German news, country: "JP", language: "ja" for Japanese, etc. Any valid Google News locale works.
Q: What's the difference between a topic URL and a cluster URL?
A: A topic is a long-running stream (e.g. "Business", "Technology"). A cluster (Google calls it "Full coverage") is a single news story with multiple publishers covering it — cluster rows additionally carry clusterAggregate with sourceCount so you can measure how widely the story has been covered.
Support
Issues, feature requests, or custom output shapes? Open a ticket on the actor's Apify page or message the maintainer directly.
Additional Services
- memo23/capterra-scraper — software product reviews from Capterra
- memo23/trustradius-scraper — B2B software reviews from TrustRadius
- memo23/glassdoor-scraper-ppr — jobs, reviews, salaries, interviews from Glassdoor
Explore More Scrapers
Looking for a similar pattern on a different site? See the full list of memo23 actors on the Apify Store.
⚠️ Disclaimer
This actor is intended for research, archival, and journalistic purposes. Every scraped article belongs to the publisher of record — respect their terms of service, copyright, and any robots.txt directives. The actor:
- Honours
robots.txtfor publisher pages (Google News' ownrobots.txtallows the surfaces we use). - Does not bypass paywalls. If a publisher's article is paywalled, we leave
body: nullrather than attempt circumvention. - Does not store, redistribute, or republish article content beyond the per-run dataset delivered to the buyer.
Buyers are responsible for downstream use of scraped content under fair-use, licensing, and applicable data-protection law in their jurisdiction.
SEO Keywords
google news scraper, google news api alternative, news article extractor, news scraping, full article body scraper, publisher content extraction, news rag pipeline, brand monitoring, competitor news monitoring, financial news scraping, news sentiment data, news ner entities, news cluster aggregator, full coverage scraper, multi-publisher news, news article body, news json-ld, news article metadata, google news rss, real-time news, apify news scraper, bloomberg news, reuters news, wsj news, financial times news, yahoo finance news, seeking alpha articles, news search api, news topic feed, news cluster api, news language filter, news time window filter