Reddit [Only $0.50💰] Posts | Users | Scraper
Pricing
from $0.50 / 1,000 results
Reddit [Only $0.50💰] Posts | Users | Scraper
[Only $0.50💰] A no-auth Reddit API alternative — scrape posts & full comment threads from public JSON: site-wide & subreddit search, feed browse, date filters, NSFW toggle, phrase match, proxy rotation. Works in Claude, Cursor & ChatGPT via Apify's MCP.
Pricing
from $0.50 / 1,000 results
Rating
5.0
(4)
Developer
Muhamed Didovic
Maintained by CommunityActor stats
2
Bookmarked
41
Total users
18
Monthly active users
10 days ago
Last modified
Categories
Share
Reddit Scraper
Scrape Reddit posts (and optionally full comment threads with replies) from public JSON — site-wide & subreddit search, feed browse, post/comment date filters, NSFW toggle, strict phrase/token match, proxy rotation. Legacy: deduplicated authors from subreddit listing URLs (key-value store).
How it works
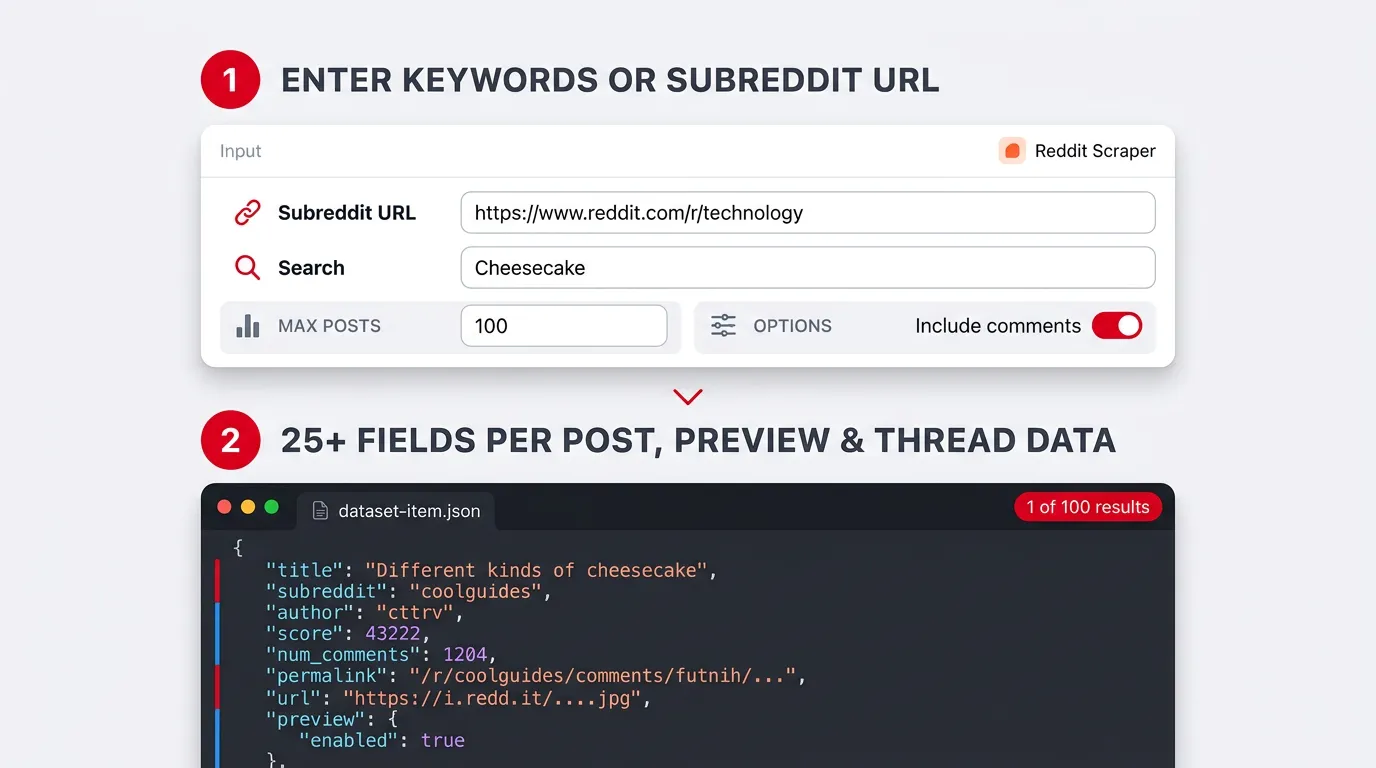
Why Use This Scraper?
- Multiple starting points — site-wide keywords, one subreddit (search or feed browse), or legacy subreddit URLs for author collection.
- Post-shaped rows — search modes write one dataset item per post, with Reddit’s own nested
preview/mediawhen present. - Optional comments — separate dataset rows per comment, with configurable caps and
morechildrendepth. - Practical filters — NSFW toggle, post/comment date windows, strict phrase and token filters, “maximize coverage” budgets, residential-friendly proxy support.
- Export-friendly — default Apify Dataset; download as JSON, CSV, Excel (CSV flattens nested keys with dots).
Overview
This actor is for research, monitoring, content analysis pipelines, and internal tools that need structured Reddit data without maintaining your own scraping stack.
- Search all of Reddit and Search one subreddit resolve into post rows in the dataset. Enable comments to add comment rows in the same dataset (
dataType: "comment", ids liket1_…). - Comments from post URLs (
postComments) takes specific post URLs and returns each post plus every comment on it (nested replies + truncated-tree expansion viamorechildren) — the focused "paste a thread, get its comments" flow. - User scraper (legacy) targets deduplicated usernames stored under the key-value key
API_DETAILS. The dataset is secondary in that mode.
The actor does not compute sentiment or topic categories; related input flags are ignored.
Supported Inputs
| You provide | When | Notes |
|---|---|---|
mode = searchGlobal | Site-wide search | Set searchQueries (string list). searchSort, searchTimeframe, includeOver18 apply. |
mode = searchSubreddit | One subreddit | subredditSearchUrl (https://…/r/name, r/name, or bare name). Empty subredditSearchQueries → feed listing; non-empty → in-subreddit search. |
mode = postComments | Comments from post URLs | postUrls — specific Reddit post URLs (e.g. https://www.reddit.com/r/webscraping/comments/1f64lbr/…). Returns each post plus all its comments (nested replies + morechildren expansion), capped by searchMaxCommentsPerPost. |
mode = subredditUsers | Legacy authors | startUrls — subreddit home URLs (e.g. https://www.reddit.com/r/webscraping). |
maxItems | All modes | Search: max posts (split across keyword lines). Legacy: max unique authors. |
proxy | All modes | Use residential or quality proxies if Reddit serves block pages or throttles. |
Search options in the Console schema also include: searchIncludeComments, searchMaxCommentsPerPost, searchListingLimitPerPage, searchPostDateFrom / searchPostDateTo, searchCommentDateFrom / searchCommentDateTo, searchForceNewSortWhenDateFiltered, searchStrictPhrase, searchStrictTokenFilter, searchMaximizeCoverage, maxConcurrency / minConcurrency / maxRequestRetries (legacy crawler), etc.
Advanced JSON-only: searchHttpTransport (internalParallel | internal), searchParallelQueryConcurrency. Legacy aliases still read in code: queries, maxPosts, includeNsfw, scrapeComments, maxComments, dateFrom / dateTo, forceSortNewForTimeFilteredRuns, strictSearch, strictTokenFilter, maximize_coverage.
Not supported: logged-in sessions, guaranteed access to private communities, compliance with your jurisdiction’s rules for Reddit data (your responsibility).
Use Cases
| Audience | Typical use |
|---|---|
| Researchers | Post and comment samples for NLP or social science. |
| Marketing & brand | Mention tracking, campaign feedback, subreddit tone. |
| Agencies | Client-ready Reddit exports on a schedule. |
| Product & data teams | Dashboards fed from Dataset webhooks. |
| Developers | Baseline Reddit HTTP + parsing without owning infra. |
How It Works
- Choose
modeand fill only the inputs that apply (Console sections match this). - The actor requests
search.json, subreddit listing or search URLs on old.reddit, or (legacy) listing JSON on www.reddit.com. - Each accepted post is mapped to a flat row (legacy Reddit field names plus optional merged aliases such as
dataType,scrapedAt,thread_url). - If
searchIncludeCommentsis on, the actor loads thread JSON, walks replies, and may call/api/morechildrenuntil per-post limits and round budgets are reached. - You export the Dataset (and for legacy mode, read
API_DETAILSfrom the Key-value store).
Input Configuration
Search all of Reddit (minimal):
Search one subreddit:
User scraper (legacy) — author list:
Output Overview
- Dataset — one JSON object per line item. Search runs are mostly
kind: "post"rows. Comments, when enabled, are additional items withdataType: "comment". - Legacy user mode — primary output is
API_DETAILS(unique usernames) in the default key-value store, not the same post schema. - Downloads — Apify offers JSON, CSV, Excel, etc. Nested objects (e.g.
preview.images) flatten in CSV. - Honest variability — Reddit omits or nulls fields by post type (text vs link vs gallery, removed authors, ads). Keys are stable when the mapper adds them; values are not.
Output Samples
Shortened post object (real shape; preview…resolutions trimmed for readability). The first record in repo data.json shows the full resolutions ladder.
Comment row (when searchIncludeComments is true) — illustrative:
Full-field sample
For every key on the first object in data.json (including all preview.images[0].resolutions[] entries), inspect that file in the repository or re-export from a fresh run. Newer runs may add merged compatibility fields (dataType, scrapedAt, reddit_fullname, thread_url, imageUrls, …) not present in older exports.
Key Output Fields
| Group | Examples | Meaning |
|---|---|---|
| Identity | kind, id, query | Post vs comment, short id, search line. |
| Content | title, body, author, created_utc | Headline, selftext, author, ISO time. |
| Engagement | score, upvote_ratio, num_comments | Reddit score, ratio, comment count. |
| Community | subreddit, subreddit_name_prefixed, subreddit_id, subreddit_subscribers | Bare name, r/…, t5_…, subscriber snapshot. |
| URLs | url, permalink, canonical_url, old_reddit_url | Outbound link, path, www thread, old.reddit thread. |
| Flags | over_18, is_self, spoiler, locked, is_video, post_hint | NSFW, text post, spoiler, lock, video, render hint. |
| Media | thumbnail, preview, media_metadata, media | Thumb; nested previews; gallery dict; embed. |
| Job context | search_scope, subreddit_search, subreddit_fetch_mode, sorts | When the mapper adds subreddit/global metadata. |
| Compatibility | dataType, scrapedAt, reddit_fullname, parsedId, username, upVotes, thread_url, imageUrls | Extra aliases on the same object for downstream tools. |
Comments: postId, parentId, communityName, category, html, authorFlair, userId, etc.
FAQ
Which URLs work?
searchGlobal uses keywords, not URLs. searchSubreddit needs a subreddit URL or r/name. subredditUsers needs subreddit home URLs in startUrls.
Posts or users?
Search modes → posts (+ optional comments). Legacy mode → usernames in API_DETAILS.
Are comments always in the dataset?
No. Turn on searchIncludeComments (or legacy scrapeComments). maxItems caps posts only; use searchMaxCommentsPerPost / maxComments for comment volume.
Why are some fields null?
Data is whatever Reddit returns for that post type and state.
Private or logged-in content?
Not supported — public JSON only.
Sentiment or categories?
Not implemented.
Support
- Issues — use the Issues tab for this actor in the Apify Console.
- Website — https://muhamed-didovic.github.io/
- Email — muhamed.didovic@gmail.com
- Store — https://apify.com/memo23
Additional Services
- Customization or full dataset delivery: muhamed.didovic@gmail.com
- Other scraping needs or actor changes: muhamed.didovic@gmail.com
- API-style usage: muhamed.didovic@gmail.com
Explore More Scrapers
Browse the author’s Apify store: https://apify.com/memo23
Reddit API alternative — works in Claude, Cursor & ChatGPT
No Reddit API keys, no OAuth, no rate-limit paperwork. This actor reads Reddit's public JSON, so it's a drop-in Reddit API alternative for market research, brand/complaint monitoring, and idea validation. Because it runs on Apify, it's automatically available over Apify's MCP server — call it as a tool directly from Claude, Cursor, ChatGPT, VS Code, or any MCP client, and pipe subreddit posts and comment threads straight into your agent or app.
SEO Keywords
Reddit scraper, Reddit API alternative, Reddit API, scrape Reddit, Reddit posts scraper, Reddit comments scraper, subreddit scraper, Reddit search, Reddit data, Reddit JSON, Reddit MCP, Reddit for Claude, Reddit for Cursor, Reddit for ChatGPT, MCP Reddit tool, Reddit market research, Reddit brand monitoring, Reddit complaints, Reddit pain points, Reddit idea validation, no-auth Reddit scraper, Reddit without API key.