Snicket Jobs Scraper
Pricing
from $2.00 / 1,000 results
Snicket Jobs Scraper
Scrape snicket.org — Bradford and West Yorkshire community-sector vacancies. RSS + labelled detail-page extraction: title, organisation, salary, hours, closing date, payment schedule, contact name/email/phone, full HTML description. JSON or CSV out, billed per result
Pricing
from $2.00 / 1,000 results
Rating
0.0
(0)
Developer
Muhamed Didovic
Maintained by CommunityActor stats
0
Bookmarked
2
Total users
1
Monthly active users
4 days ago
Last modified
Share
Scrape Bradford and West Yorkshire community-sector vacancies from snicket.org. Reads the public RSS feed for fast listing, then enriches each row with detail-page structured fields: organisation, salary, hours, closing date, payment schedule, contact name, contact email, and phone number. JSON or CSV out, no compute charge per run, just per result.
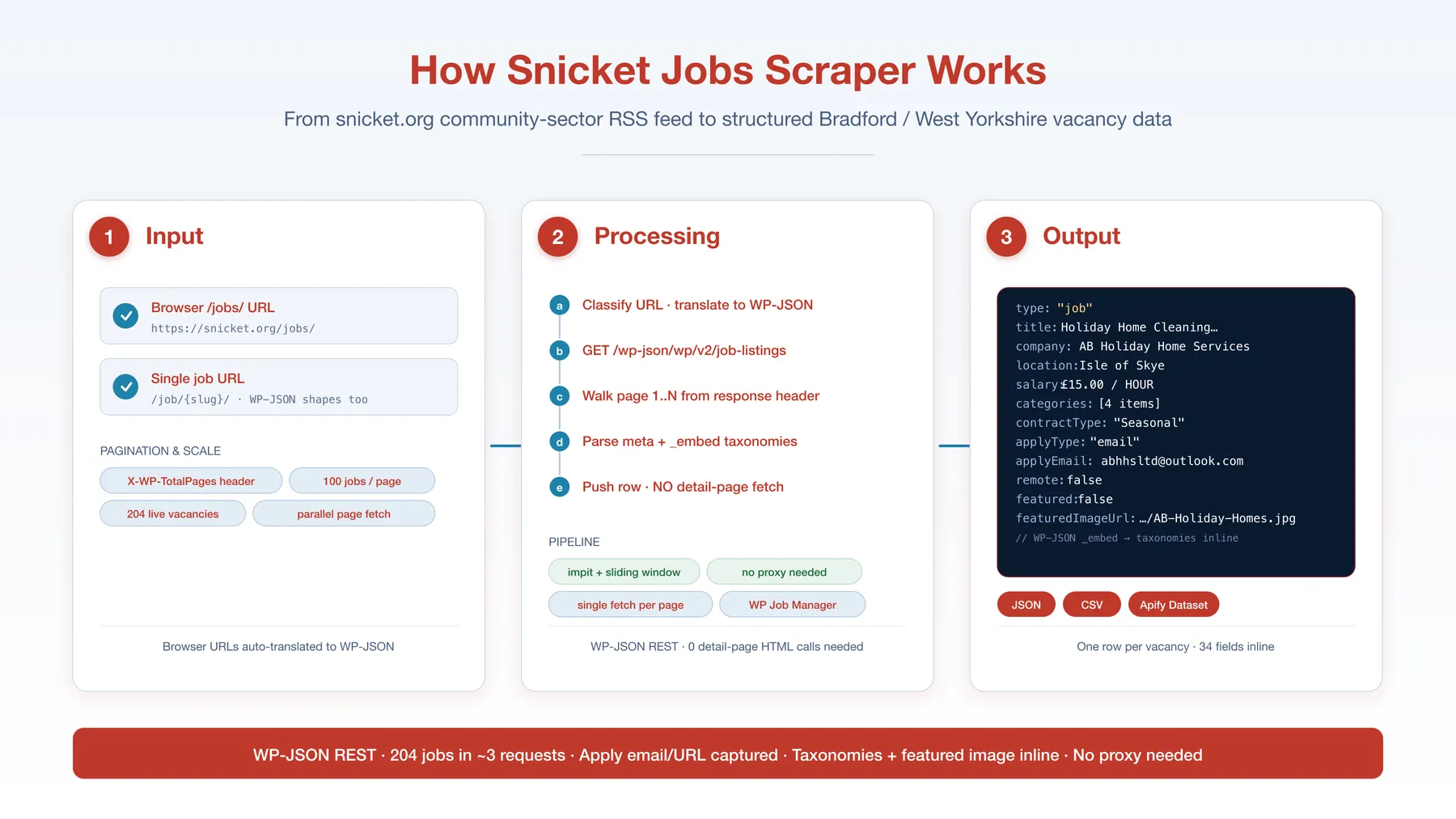
How it works
✨ Why use this scraper?
Snicket is the community-sector hub for Bradford and West Yorkshire — local charities, faith groups, mental health orgs, family support, domestic abuse services, refugee support. Tracking who's hiring across the region's third sector? Building a Bradford voluntary-sector dashboard?
- 🎯 Two starting points. The
/jobs/feed/RSS feed (default) or any direct/jobs/<slug>/URL. - ⚡ RSS feed as the primary source. One HTTP call returns up to 17 items with title, link, pubDate, author, description, and full content HTML.
- 📋 Detail-page label extraction. Each job page has a "Job Details" section with inline
Label: valuerows — Hours, Closing Date, Payment Schedule, Job Salary, Contact Name, Contact Email, Phone Number. - 📧 Apply contact captured. Contact email always populated when present — falls back to mailto in "How to Apply" section.
- 💰 Salary parsed.
Job Salary: £25,989 - £27,254→ structured{currency, min, max, raw}. - 🇬🇧 West Yorkshire community focus. Bradford, Leeds, Calderdale, Kirklees, Wakefield — small charities and large support orgs alike.
- 📤 Clean exports. One row per vacancy with merged RSS + detail enrichment. JSON + CSV exported automatically.
🎯 Use cases
| Team | What they build |
|---|---|
| Voluntary sector recruiters | Daily new-vacancy feeds for West Yorkshire third-sector jobs |
| Charity researchers | Bradford / West Yorkshire community-sector hiring trends |
| Aggregators | Real recruiter contact emails for direct applicant outreach |
| Funders | Salary intelligence across small West Yorkshire charities |
| Sector publications | Auto-populate Bradford voluntary-sector job listings |
📥 Supported inputs
| URL pattern | Behaviour |
|---|---|
https://snicket.org/jobs/feed/ | RSS feed (default) — up to 17 items |
https://snicket.org/jobs/ | Jobs archive — routed to the RSS feed |
https://snicket.org/jobs/<slug>/ | Single job — synthetic stub + detail-page fetch |
Leave startUrls empty for the default RSS feed.
Not supported: hosts outside snicket.org.
🔄 How it works
- Bucket each
startUrlas RSS feed vs direct detail URL. - Fetch the RSS feed — title, link, pubDate, author, full content HTML.
- For each item, optionally fetch the
/jobs/<slug>/detail page. - Parse the "Job Details" section — labelled
Hours: …,Closing Date: …,Payment Schedule: …,Job Salary: …,Contact Name: …,Contact Email: …,Phone Number: …. - Find the organisation — "About
- Push one merged row per vacancy to the dataset.
⚙️ Input parameters
| Parameter | Type | Default | Description |
|---|---|---|---|
startUrls | array | ["https://snicket.org/jobs/feed/"] | RSS feed or direct job URLs. Empty = default feed. |
enrichDetail | boolean | true | When true, fetches each detail page for the labelled fields above. Disable for RSS-only output. |
postedWithinHours | integer | (none) | Only return rows posted in the last N hours (24 = last day, 72 = last 3 days). Empty/0 = all. Ideal for daily monitoring runs that only want fresh postings. |
maxItems | integer | 1000 | Hard cap on rows pushed (~17 in the RSS feed at any time). |
maxConcurrency / minConcurrency | integer | 5 / 1 | Parallel detail-page fetch limits. |
maxRequestRetries | integer | 5 | Retries before a failed request is given up. |
proxy | object | No proxy | Site does not anti-bot — proxy optional. |
📊 Output overview
Each scraped vacancy is one single dataset row of type: "job". RSS-derived fields merged with the detail-page structured "Job Details" block.
📦 Output sample
🗂 Key output fields
| Group | Fields |
|---|---|
| Identifiers | type, source, jobId, slug, jobUrl, scrapedAt |
| Content | title, description (HTML, from RSS), descriptionText (plain) |
| Dates | postedDate (from RSS pubDate), closingDate (from Job Details), modifiedDate |
| Employer | companyName (from "About |
| Compensation | salary.{currency, min, max, raw}, salaryRaw, paymentSchedule (Monthly / Weekly / etc.) |
| Working pattern | hours (e.g. "35 hours per week") |
| Apply flow | applyType, applyUrl, applyEmail, externalApplyUrl |
| Contact | contactName, contactEmail, contactPhone |
| WordPress meta | authorName (RSS dc:creator) |
❓ FAQ
Why is location sometimes null?
Snicket doesn't enforce a "Location" field in their post template. When present we extract it from a dedicated heading; otherwise null.
Why does contactEmail sometimes have trailing junk (e.g. "Interview Date" appended)?
The labelled-extraction regex can over-match when the post uses a non-standard label after the email. This is rare but the email is always at the start — split on the first whitespace if needed.
Can I get the full HTML description?
Yes — see description. The plain-text version (descriptionText) drops markup but keeps line breaks.
Can I scrape private pages or applicant data?
No. Only the public RSS feed and public /jobs/<slug>/ pages.
How do I limit results?
Set maxItems. Disable enrichDetail to skip per-job HTTP calls (17 jobs in 1 fetch).
💬 Support
- For issues or feature requests, please use the Issues tab on the actor's Apify Console page.
- Author's website: https://muhamed-didovic.github.io/
- Email: muhamed.didovic@gmail.com
🛠 Additional services
- Custom output shape, additional fields, or one-off datasets: muhamed.didovic@gmail.com
- Similar scrapers for other CVS / volunteer hubs (Doing Good Leeds, VA Rotherham, VAS Sheffield, Barnsley CVS): drop an email.
- For API access (no Apify fee, just usage): muhamed.didovic@gmail.com
🔎 Explore more scrapers
See other scrapers at memo23's Apify profile — covering job boards, real estate, social media, and more.
⚠️ Disclaimer
This Actor is an independent tool and is not affiliated with, endorsed by, or sponsored by Snicket, snicket.org, or any of their subsidiaries or affiliates. All trademarks mentioned are the property of their respective owners.
The scraper accesses only the publicly available RSS feed and public job pages on snicket.org — no authenticated endpoints, recruiter-only features, or content behind a login. Users are responsible for ensuring their use complies with snicket.org's Terms of Service, applicable data-protection law (GDPR, CCPA, etc.), and any contractual obligations of their own organisation.
SEO Keywords
snicket scraper, scrape snicket.org, snicket jobs api, bradford voluntary sector jobs scraper, bradford charity jobs scraper, west yorkshire community sector jobs api, Apify snicket, west yorkshire charity recruitment data, bradford third sector jobs api, bradford community jobs scraper, rss feed scraper, west yorkshire nonprofit jobs, leeds bradford charity hiring data, wakefield charity jobs api, kirklees charity jobs scraper, charityjob alternative scraper, doing good leeds alternative scraper, vassheffield alternative scraper, barnsleycvs alternative scraper, uk cvs jobs scraper