Xing Scraper — Jobs, Companies & Profiles ($1.19 / 1k)
Pricing
from $1.19 / 1,000 results
Xing Scraper — Jobs, Companies & Profiles ($1.19 / 1k)
Xing scraper — jobs, companies & profiles in one actor at $1.19 / 1,000 results. Paste any xing.com URL (search, /jobs/{slug}, /pages/{slug}, /profile/{id}) or filter by keyword + location + discipline + radius. 35+ fields per row: salary, Kununu, employees, social links. JSON or CSV.
Pricing
from $1.19 / 1,000 results
Rating
0.0
(0)
Developer
Muhamed Didovic
Maintained by CommunityActor stats
3
Bookmarked
156
Total users
50
Monthly active users
17 hours ago
Last modified
Categories
Share
How it works
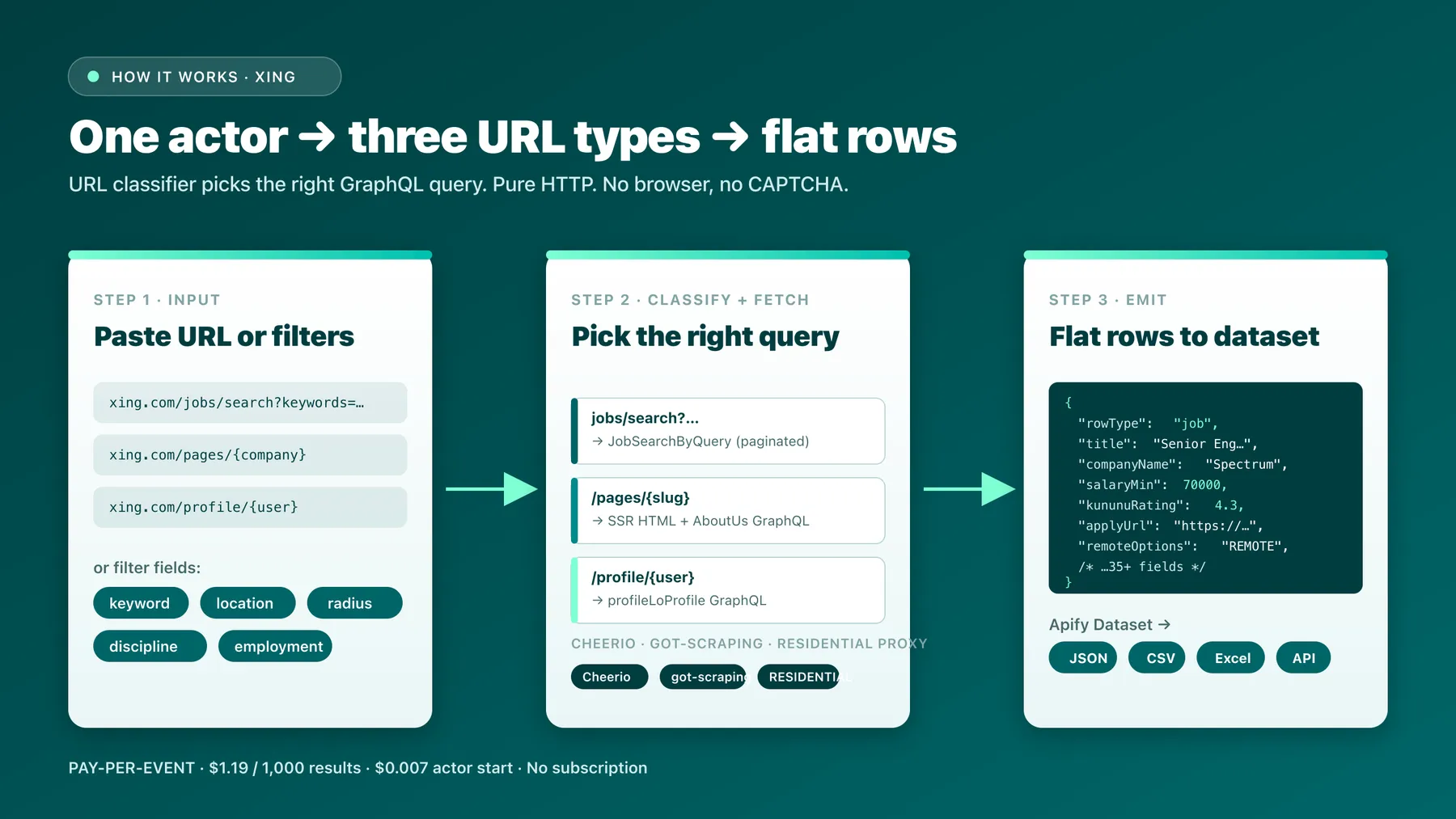
All-in-one Xing scraper at $1.19 per 1,000 results. Paste any xing.com URL — job search, single job, company page, or member profile — and get a flat row per record with 35+ fields. Or skip URLs entirely: search by keyword + location + discipline, or paste a bulk list of company slugs.
| Input you provide | Row(s) emitted |
|---|---|
xing.com/jobs/search?keywords=… | One job row per listing across all pages |
xing.com/jobs/{slug} (single job) | One job row |
xing.com/pages/{company-slug} | One company row with employees, jobs, locations |
xing.com/profile/{user} | One profile row with work timeline, education, skills |
keyword + location + discipline | Generates a canonical search URL, then same as row 1 |
companyTargets: ["bayer", "sap", …] | One company row per slug — same shape as the URL-driven path |
Pure HTTP. No browser, no third-party CAPTCHA service, no CF-bypass proxy.
Why use this scraper?
- Only Xing actor on Apify Store that handles all four URL types (jobs search, single job, company page, member profile) — most competitors only do one.
- $1.19 / 1k — matches the category leader's price while doing 3× more (jobs + companies + profiles, not jobs-only).
- Bulk-companies shortcut: paste a list of slugs (
bayer,sap,basf) without building URLs — same convenience asmaximedupre/xing-companies-scraper, but plus jobs and profiles in the same run. - Salary + Kununu rating + apply URL captured on every job row — no second fetch needed.
- Full company pages parsed from the SSR Apollo state: followers, employees with profile URLs, every job posting, all office locations with coordinates and contact info.
- Built-in filters for employment type, career level, remote option, and salary range — narrow your dataset without post-processing.
- GDPR-aware: only public profile data, no logged-in scraping, no private fields.
- Classifier. Each input URL is matched against
jobs/{slug},pages/{slug},profile/{user}, or treated as a search URL. The classifier picks the matching GraphQL operation and headers. - Fetch. Requests go through Apify Residential proxy via
got-scraping. For company pages, the SSR HTML is parsed with Cheerio for thewindow.crate.serverData.APOLLO_STATEblob; everything else is GraphQL. - Pagination. Job-search results paginate via GraphQL
offset/limituntilmaxItemsis hit or the result set ends. - Emit. Each row is flattened (no
__typename, no nested noise) and pushed to the Apify dataset. The job row is the same shape whether it came from a search page or a direct/jobs/{slug}.
Supported inputs
Job search URLs
Single job URLs
Company pages
Member profiles
Filter-only mode (no URL)
Provide keyword + location + optional discipline/radius — the actor builds the canonical search URL and runs it.
Bulk companies (URL or slug shortcut)
Skip building URLs for each company — paste the slugs directly:
Each entry can be a full URL or a bare slug (anything that follows xing.com/pages/). Entries are merged into startUrls at run time and routed to the same company row handler — so output is identical to the URL path.
Company names with spaces (e.g.
"Bayer AG") aren't auto-resolved yet — paste the slug instead. Invalid entries are skipped with a warning in the log, not silently dropped.
Advanced filters (post-fetch)
Set any of these to narrow the dataset to only matching rows:
| Filter | Works without includeListingDetails | Notes |
|---|---|---|
employmentType | ✓ | Multi-select: FULL_TIME, PART_TIME, INTERN, CONTRACTOR, FREELANCE, TEMPORARY, OTHER |
salaryMin / salaryMax | ✓ | Annual €. Set 0 to disable. Matches against the row's salary range. |
careerLevel | ✗ | Requires includeListingDetails: true — the field only appears in detail rows. |
remoteOption | ✗ | Requires includeListingDetails: true — same reason. |
Filters are applied after rows are fetched, so you still pay for the raw rows that get dropped. For typical search sizes the difference is negligible.
Unsupported
- Logged-in-only views (private profiles, premium contact info)
xing.com/communities/*,xing.com/news/*,xing.com/insights/*- Job applications (we only read, never apply)
Use cases
| Audience | What they pull |
|---|---|
| Recruiters / talent ops | Job listings (salary, employment type, apply URL) by region + discipline; build a German-market vacancy feed |
| Sales / lead-gen | Company pages — followers, employee count, office addresses, websites → outbound list |
| HR-tech & ATS vendors | Combined job + company rows to enrich applicant submissions with employer Kununu rating |
| Market researchers | Discipline + location aggregates for DACH labour-market reports |
| Recruiting CRMs | Profile timeline + skills → enrichment for German candidate records |
Input configuration
| Field | Type | Required | Notes |
|---|---|---|---|
startUrls | array of { url } | one of these is required | Mix any URL types (search, job, profile, company). |
companyTargets | array of strings | one of these is required | Bulk-companies shortcut: each entry is a full URL OR a bare slug ("bayer"). Merged into startUrls at run time. |
keyword | string | one of these is required | Job title / skill keywords. Overrides title. |
title | string | — | Alias for keyword (legacy). Ignored if keyword is set. |
location | string | — | E.g. Berlin, Munich. Used when no URL is provided, or to fill gaps when a URL omits it. |
discipline | string | — | Xing discipline label, e.g. Technology. |
radius | integer | — | Search radius in km. Default 10. |
employmentType | array of enums | — | Multi-select. Drops jobs that don't match. Default: keep all. |
careerLevel | array of enums | — | Multi-select. Requires includeListingDetails: true. |
remoteOption | array of enums | — | Multi-select (FULL_REMOTE, PARTLY_REMOTE, NON_REMOTE). Requires includeListingDetails: true. |
salaryMin | integer | — | Min annual salary in EUR. 0 disables. |
salaryMax | integer | — | Max annual salary in EUR. 0 disables. |
maxItems | integer | — | Hard cap on emitted rows. Free users capped at 100. |
maxConcurrency | integer | — | Default 10. Crank up for paid runs on big seeds. |
minConcurrency | integer | — | Default 1. |
maxRequestRetries | integer | — | Default 3. |
proxy | object | — | Apify proxy config. Defaults to RESIDENTIAL. |
Example input
Or, with no URLs:
Or, bulk-companies via slugs:
Output overview
One flat row per record. Three row shapes (job, company, profile) — same dataset, distinguish by the presence of scrapedType or the unique fields.
Job row (sample, shortened)
Company row (sample, shortened)
Profile row (sample, shortened)
Key output fields
Job rows
- Identity:
id,slug,url,title - Company:
companyName,companyLogo,companyUrl,companyAddress,companySize,kununuRating - Compensation:
salaryMin,salaryMax,salaryMedian,salaryCurrency - Classification:
employmentType,careerLevel,discipline,industry,remoteOptions - Content:
description(full text),keywords(skills list),applyUrl - Social:
socialWebsite,socialFacebook,socialTwitter,socialYoutube,socialLinkedin,socialInstagram
Company rows
- Identity:
id,name,url,profilePicture - Scale:
followers,employeesNumber,companySizeRange.min/max - About:
headline,summary,description,foundedYear,websiteUrl,legalNotice - Relations:
employees[],jobs[],locations[] - Trust:
kununuRating,industry
Profile rows
- Identity:
id,name,firstName,lastName,pageName,displayName - Status:
isPremium,occupation,location,city,country - Timeline:
timeline[](jobs in chronological order) - Education:
education[],highestEducationDegree,highestEducationSchool - Skills:
tags[],languages[],interests[],wants[]
Pricing
| Event | When | Rate |
|---|---|---|
apify-actor-start | Once at run start, per GB of allocated memory | $0.007 |
apify-default-dataset-item | Per scraped row (job / company / profile) | $0.00119 |
So a typical run that scrapes 1,000 job rows on 1 GB memory costs ~$1.19 + $0.007 ≈ $1.20 total.
Free users are capped at 100 items per run; paid users have no cap beyond maxItems and ACTOR_MAX_PAID_DATASET_ITEMS.
What makes this richer than the competition
| Capability | Jobs-only competitors | Companies-only competitors | This actor |
|---|---|---|---|
| Job listings + salary + Kununu | ✓ | ✗ | ✓ |
| Pagination across job-search results | ✓ | ✗ | ✓ |
| Company pages (followers, employees, locations) | ✗ | ✓ | ✓ |
| Member profiles (timeline, skills, languages) | ✗ | ✗ | ✓ |
| Bulk-companies shortcut (slug list, no URLs) | ✗ | ✓ | ✓ |
| Multi-select filters (employment type, salary, remote) | partial | ✗ | ✓ |
| Mixed URL types in one run | ✗ | ✗ | ✓ |
| Pure HTTP (no browser) | ✓ | ✓ | ✓ |
| Price | $1.19–$2.99 / 1k | varies | $1.19 / 1k (all-in-one) |
FAQ
Q: Do I need a Xing account or API key? No. The actor uses Xing's public GraphQL endpoint with a built-in client identity. You only need your Apify account.
Q: I have a list of 200 company names — do I have to convert each to a URL?
No. Use companyTargets and paste either URLs or bare slugs (bayer, sap, spectrumag). The actor expands each to https://www.xing.com/pages/{slug} automatically. Company names with spaces ("Bayer AG") aren't auto-resolved yet — use the slug.
Q: I set careerLevel / remoteOption but nothing was filtered. Why?
Those two filters live only in the job detail response, not in the search-results page. Set includeListingDetails: true and they'll work. employmentType and salary filters work without details.
Q: Can I scrape private profiles or premium contact info? No. The actor only reads what an unauthenticated Xing visitor would see. Private/premium fields are not exposed.
Q: Do company pages return ALL employees?
Only what Xing renders publicly on the company /pages/{slug} SSR view (typically a few dozen senior employees). For a complete employee directory you would need each member's /profile/{user} page.
Q: What if a job URL has no salary?
Salary fields will be undefined. Most Xing jobs do publish salary ranges; some companies opt out.
Q: Can I scrape Xing.de competitors (e.g. LinkedIn, Indeed)?
No — this actor only handles xing.com domains. Look at the Explore More Scrapers section below for related actors.
Q: How does pagination work?
For search URLs, the actor fetches 20 results per page and continues until either maxItems is hit or Xing returns fewer than 20 results.
Q: My run failed with a 401 / 403 — what now? Usually a stale Xing token or a flagged IP. Re-run; the proxy session rotates. If it persists, open an issue (link below) and we'll refresh the embedded token.
Q: Is there a CSV export? Yes — Apify Console offers JSON, CSV, XLSX, RSS, HTML out of the box on every dataset.
Support
- Open an issue: https://console.apify.com/actors/memo23/xing-scraper/issues
- Email: muhamed.didovic [at] gmail.com
- Bug reports: include the run ID and the URL that misbehaved.
Additional services
Need bespoke Xing extraction (e.g. industry-wide weekly company sweeps, candidate enrichment at scale, custom-field mapping into Salesforce / HubSpot / Greenhouse)? Reach out via the email above — happy to scope custom work.
Explore more scrapers
- Stepstone Scraper — DACH job board with similar pricing
- LinkedIn Jobs Scraper — global jobs at scale
- Kununu Scraper — company ratings to pair with this actor's
kununuRatingfield - Arbeitsagentur Jobs Feed — German federal jobs feed
- German Imprint Scraper — pair company
websiteUrlwith imprint contacts for outbound
🤖 For AI Agents & LLM Apps
Compact reference for AI agents calling this actor via the Apify MCP server or the Apify API (actor: memo23/xing-scraper).
Purpose: Scrape xing.com jobs, company pages, and member profiles in one actor — one flat row per record; the differentiator is mixing all three URL types (plus a filter-only search and a bulk-company slug shortcut) in a single run at ~$1.19/1k rows.
Minimal input:
Filter-only variant (no URL): { "keyword": "developer", "location": "Berlin", "maxItems": 50 }
Output: three row shapes in one dataset (tell them apart by scrapedType / unique fields). Job rows: id, url, title, companyName, companyUrl, location, country, salaryMin, salaryMax, salaryCurrency, employmentType, careerLevel, discipline, industry, remoteOptions, datePosted, validThrough, description, keywords, applyUrl, kununuRating, socialWebsite/socialLinkedin. Company rows: id, name, url, followers, employeesNumber, industry, foundedYear, websiteUrl, kununuRating, headline, summary, description, employees[], jobs[], locations[{label, city, address, postCode, coordinates {latitude, longitude}, country {countryCode}, contactInfo {phoneNumber, websiteURL}}]. Profile rows: name, isPremium, occupation, location, tags[], timeline[{time, occupation, organizationName}], education[{title, school}], languages[{name, level}], interests[].
Behaviors an agent should know:
- Provide exactly one seed:
startUrls,companyTargets, or the filter fields (keyword+location). URLs take precedence; filter fields only fill gaps a search URL omits. - Always set
maxItems(default 100) — free Apify accounts are hard-capped at 100 rows/run regardless. companyTargetsaccepts full/pages/{slug}URLs or bare slugs ("bayer"); names with spaces aren't resolved.employmentTypeand salary filters work on basic search;careerLevelandremoteOptionfilters requireincludeListingDetails: true(they only appear in job-detail rows). Filters run post-fetch, so dropped rows are still billed.- Public unauthenticated data only — no private/premium profiles or contact info. Handles
xing.comdomains only. - Billing: pay-per-event —
apify-actor-start$0.007 per GB at start, plusapify-default-dataset-item$0.00119 per row (~$1.19/1k). See the Pricing tab on the actor page.
⚠️ Disclaimer
This Actor accesses publicly available data on Xing (operated by New Work SE) for legitimate research, market intelligence, and business-analysis purposes. Use of this Actor must comply with Xing's Terms of Service and all applicable laws, including the EU General Data Protection Regulation (GDPR), the German Federal Data Protection Act (BDSG), and any other applicable jurisdictional privacy regulation. The Actor's authors are not affiliated with New Work SE or Xing.
Users must:
- Respect rate limits and avoid overloading Xing's infrastructure
- Not use scraped data to violate user privacy or Xing's Terms of Service
- Comply with GDPR when processing personal data of EU residents (lawful basis, retention limits, data-subject rights)
- Not republish scraped content in violation of copyright
- Not use the data for unsolicited bulk contact (anti-spam / UWG)
We do not store any scraped data; the Actor returns it directly to your Apify dataset for your authorized use.
SEO Keywords
xing scraper, xing jobs scraper, xing companies scraper, xing profile scraper, xing bulk company slugs, xing search by keyword, xing salary filter, xing remote jobs filter, xing api alternative, xing data extraction, xing bulk export, dach jobs scraper, germany jobs scraper, austria jobs scraper, switzerland jobs scraper, xing.de scraper, kununu data extraction, b2b lead generation germany, recruitment data dach, sales prospecting dach, talent intelligence, hr data scraper, professional network scraper, no-code xing scraper, apify xing actor, xing json export, xing csv export