Competitive Intelligence Meta-Agent
Pricing
Pay per event
Competitive Intelligence Meta-Agent
Meta-agent orchestrating pricing, sentiment, and news data. Combines 3+ specialized Actors with LLM-based task parsing and intelligent aggregation. MCP-ready for seamless agent integration.
A powerful meta-agent orchestrator that combines multiple specialized data collection actors to provide comprehensive competitive intelligence analysis. This actor intelligently aggregates pricing, sentiment, and news data with advanced deduplication, aggregation, and performance monitoring.
Overview
The Competitive Intelligence Meta-Agent is designed for market researchers, business analysts, and competitive intelligence professionals who need to gather and analyze multi-source competitive data efficiently. By orchestrating 3+ specialized actors in parallel, it delivers comprehensive insights while optimizing API costs and execution time.
Key Features
Data Orchestration
- Parallel Sub-Actor Execution: Execute multiple data collection actors concurrently using asyncio for maximum efficiency
- Flexible Configuration: Define any number of sub-actors with custom input parameters
- Intelligent Error Handling: Exponential backoff retry logic with maximum retries for resilient operations
- Timeout Management: Configurable timeout per sub-actor with fallback strategies
Data Aggregation & Processing
- Smart Deduplication: Remove duplicate items based on configurable key fields (ID, URL, title)
- Sentiment Analysis Aggregation: Combine sentiment data from multiple sources with consolidated metrics
- Total mentions, positive/negative/neutral counts
- Positive sentiment ratio
- Average sentiment score
- Pricing Data Consolidation: Aggregate pricing information across sources
- Min/max/average prices
-
Source diversity metrics
- Price comparison analytics
Performance & Monitoring
- Execution Metrics: Track performance of each sub-actor
- Execution time per actor
- Success/failure status
-
Items processed count
- Error tracking
- Comprehensive Logging: Detailed logs for debugging and monitoring
- Performance Optimization: Parallel execution significantly reduces total runtime
Integration Ready
- MCP Protocol Support: Ready for Model Context Protocol integration with AI agents
- Structured Output: JSON-formatted results for seamless downstream processing
- Extensible Architecture: Easy to add new data aggregation strategies
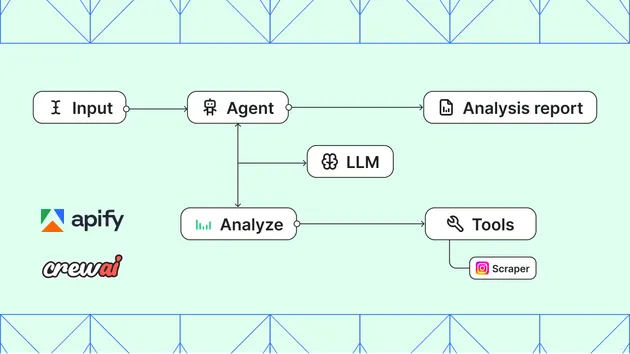
How It Works
Architecture
Input Request↓[Sub-Actor Config 1] → Actor Call → Results[Sub-Actor Config 2] → Actor Call → Results[Sub-Actor Config 3] → Actor Call → Results↓Data Aggregation├─ Deduplication├─ Sentiment Analysis├─ Pricing Consolidation└─ Source Grouping↓Output: Comprehensive Competitive Intelligence```### Execution Flow1. **Initialization**: Parse input configuration and initialize orchestrator2. **Parallel Execution**: Launch all sub-actors concurrently3. **Error Handling**: Automatically retry failed actors with exponential backoff4. **Data Collection**: Gather results from all sub-actors5. **Aggregation**: Deduplicate, classify, and aggregate data6. **Analysis**: Generate sentiment and pricing analyses7. **Output**: Return comprehensive results with performance metrics## Input Schema```json{"request": "string - The analysis request or query (e.g., 'analyze competitor pricing')","sub_actors": [{"actor_id": "string - Apify actor ID or username/actor-name","input_data": "object - Input parameters for the sub-actor","timeout_secs": "integer - Custom timeout for this actor (optional, default: parent timeout)"}],"timeout_secs": "integer - Global timeout in seconds (30-3600, default: 300)"}```## Output Schema```json{"timestamp": "ISO8601 datetime","analysis_request": "string - The original analysis request","execution_summary": {"total_sub_actors": "integer","successful_runs": "integer","failed_runs": "integer","total_items_collected": "integer","deduplicated_items": "integer","total_unique_items": "integer"},"aggregated_data": {"all_items": "array - Deduplicated items from all sources","sentiment_analysis": {"total_mentions": "integer","positive_count": "integer","negative_count": "integer","neutral_count": "integer","positive_ratio": "float (0-1)","average_sentiment_score": "float"},"pricing_analysis": {"min_price": "float","max_price": "float","average_price": "float","price_count": "integer","source_count": "integer"},"items_by_source": "object - Items grouped by source"},"performance_metrics": [{"actor_id": "string","execution_time": "float (seconds)","status": "string (success/failed)","items_count": "integer","error_message": "string or null"}]}```## Usage Examples### Example 1: Competitor Pricing Analysis```json{"request": "Analyze competitor pricing for Product X","sub_actors": [{"actor_id": "username/ecommerce-price-scraper","input_data": {"urls": ["amazon.com/ProductX", "walmart.com/ProductX"],"extract": ["price", "rating"]},"timeout_secs": 300},{"actor_id": "username/marketplace-price-monitor","input_data": {"product": "Product X","markets": ["ebay", "alibaba"]},"timeout_secs": 300}],"timeout_secs": 600}```### Example 2: Comprehensive Market Analysis```json{"request": "Market sentiment and competitive analysis","sub_actors": [{"actor_id": "username/news-sentiment-analyzer","input_data": {"keywords": ["competitor1", "competitor2"],"date_range": "last_30_days"}},{"actor_id": "username/social-media-monitor","input_data": {"brands": ["competitor1", "competitor2"],"platforms": ["twitter", "reddit"]}},{"actor_id": "username/review-scraper","input_data": {"products": ["competitor1_product", "competitor2_product"],"sites": ["trustpilot", "g2"]}}]}```### Example 3: Minimal Configuration```json{"request": "Basic competitive intelligence","sub_actors": [],"timeout_secs": 300}```## Configuration Best Practices### Sub-Actor Selection1. **Choose Complementary Data Sources**: Select actors that provide different data types2. **Prioritize High-Quality Data**: Prefer actors with good reliability records3. **Balance Coverage and Cost**: More actors = more data but higher costs### Timeout Configuration- **Web Scraping**: 300-600 seconds (data availability can be variable)- **API-based Data**: 60-180 seconds (more reliable)- **News/Social Media**: 180-300 seconds (depends on data volume)### Key Field SelectionThe actor uses ID, URL, and title for deduplication. Ensure your data contains these fields for optimal results.### Error Handling Strategy- **Critical Actors**: Increase max_retries in code if some actors are unreliable- **Timeout Handling**: Set generous timeouts for initial runs, adjust based on actual execution time- **Partial Failures**: The meta-agent continues if some sub-actors fail, aggregating successful results## Performance Considerations### Execution Time Optimization- Parallel execution: 3 actors each taking 300s sequentially = 300s total (vs 900s serial)- Network I/O: Async operations prevent blocking on API calls- Deduplication: O(n) complexity with hashable fields ensures fast deduplication### Memory Usage- Scales with total items total_items_collected- Deduplication uses a set, keeping memory footprint Minimal- For very large datasets (>100k items), consider processing in batches### Cost Optimization- Parallel execution reduces total run time, lowering compute costs- Deduplication prevents duplicate processing downstream- Smart retry logic minimizes failed API calls## Monitoring & Debugging### Performance MetricsThe output includes detailed performance metrics for each sub-actor:- Execution time helps identify slow actors- Success/failure status highlights reliability issues- Item counts show data collection effectiveness### LoggingAll operations are logged with Actor.log:- INFO: Main execution milestones- WARNING: Non-critical failures and retries- EXCEPTION: Critical errors with full stack traces## Advanced Configuration### Custom Aggregation StrategiesThe DataAggregator class can be extended for specific needs:- Add custom sentiment algorithms- Implement domain-specific pricing analysis- Create specialized deduplication logic### Integration with LLM AgentsMCP-ready design allows seamless integration:- Define tool schemas for LLM consumption- Return structured output for AI-friendly parsing- Support for multi-step analysis workflows## Troubleshooting### Common Issues**Issue**: Sub-actors timing out**Solution**: Increase timeout_secs or optimize sub-actor input complexity**Issue**: Low deduplication rate**Solution**: Verify sub-actors return data with ID, URL, or title fields**Issue**: Memory errors with large datasets**Solution**: Reduce number of sub-actors or implement batch processing**Issue**: Inconsistent sentiment scores**Solution**: Ensure all sub-actors use compatible sentiment scoring (0-1 range)### Support Resources- Review performance_metrics in output for detailed error messages- Check logs for Actor.log.exception entries- Validate input schema against examples above## PricingThis actor uses the **Pay per event** pricing model. Each execution is charged based on:- API calls to sub-actors- Data processing operations- Result aggregation complexityParallel execution and deduplication help minimize costs by reducing redundant processing.## Requirements- Node.js or Python runtime for sub-actors- Apify API token (automatically provided in Apify platform)- Sub-actor actor IDs or usernames for Orchestration## RepositoryFor updates, documentation, and community contributions, visit the Apify marketplace.---**Version**: 1.0**Last Updated**: 2025-12-27**Author**: Competitive Intelligence Team}}
-
- Success/failure status
- Execution time per actor
-
- Min/max/average prices
- Positive sentiment ratio
- Total mentions, positive/negative/neutral counts