🧩Reddit Community Analyzer
Pricing
Pay per event
🧩Reddit Community Analyzer
Analyze Reddit communities deeply with the Reddit Community Analyzer. Gain insights into subreddit engagement, user sentiment, and trending topics for data-driven decisions.
Pricing
Pay per event
Rating
5.0
(2)
Developer

NextAPI
Actor stats
2
Bookmarked
6
Total users
3
Monthly active users
3 hours ago
Last modified
Categories
Share
Reddit Community Analyzer
Map any subreddit's DNA in seconds.
Don't just scrape posts—capture the full context. Get identity metadata, policy docs, rules, wikis, and complete comment trees enriched with vote telemetry. Stop guessing and start understanding exactly what is happening inside your target communities.
🌟 Why choose this Actor?
Built for deep community analysis, this Actor goes beyond simple scraping to provide a holistic view of a subreddit's "DNA".
| Feature | Reddit Community Analyzer | Standard Scrapers | Official API |
|---|---|---|---|
| Comment Trees | ✅ Full Hierarchical Trees | ❌ Flat / Partial | ⚠️ Rate Limited |
| Metadata | ✅ Rules, Wikis, Stickies | ❌ Basic Info Only | ✅ Full Access |
| Cost Efficiency | ✅ Pay-per-Result | ⚠️ Monthly Subs | ❌ High Enterprise Fees |
| Ease of Use | ✅ No-Code / API | ⚠️ Coding Required | ❌ Complex OAuth |
💡 Unique Advantages
- Complete Context: Don't just get posts; get the rules they break and the wikis they reference.
- Engagement Signals: Granular upvote/downvote splits and cross-post data.
- Resilient Architecture: Uses Enterprise-Grade Infrastructure and intelligent concurrency to ensure reliable data collection at scale.
🏆 Key Features
📊 Comprehensive Subreddit Intelligence
- 🎯 One-Stop Intelligence Hub: Stop piecing together data. Get everything in one run: metadata, rules, wikis, stickies, posts, and full comment trees.
- 📊 Zero-Gap Post Collection: Harvest every submission, not just the popular ones. Captures titles, bodies, media, and status flags (NSFW, archived) without omission.
- 🌳 Hierarchical Comment Trees: Preserves the full conversation structure (parent-child relationships). Essential for sentiment analysis that relies on reply context.
- 📋 Governance & Policy Data: The only scraper that extracts Rules, Wikis, and Stickies—giving you the "laws of the land" for every community.
- 📈 Granular Engagement Metrics: Goes beyond simple scores. Get precise Upvote/Downvote splits, crosspost counts, and award data to measure true virality.
🎯 Use Cases
💼 Business Intelligence & Market Research
- Audience Discovery: Uncover target demographics and interests by analyzing subscriber overlap and engagement patterns.
- Voice of Customer: Detect pain points and feature requests directly from user discussions in niche communities.
- Competitor Monitoring: Track rival-owned communities for launch updates, policy shifts, and user sentiment.
- Trend Spotting: Identify emerging themes in early-adopter subreddits before they hit the mainstream.
📈 Social Media Intelligence & Analytics
- Viral Content Detection: Spot rising trends in high-volume subreddits like r/AskReddit or r/technology early.
- Community Growth Tracking: Measure subscriber velocity and active user ratios to understand community health.
- Engagement Benchmarking: Analyze vote splits and crosspost data to define what "success" looks like in your niche.
- Influence Mapping: Discover related subreddits and key opinion leaders through crosspost analysis.
💰 Brand Monitoring & Reputation Management
- Reputation Defense: Catch negative sentiment early by monitoring brand keywords and community reactions.
- Sentiment Analysis: Feed raw comment trees into NLP models for granular opinion mining and brand perception tracking.
- Crisis Alerting: Instant visibility into stickied mod posts or sudden spikes in activity that could signal a crisis.
- Campaign Impact: Measure pre/post-campaign engagement shifts within specific communities to prove ROI.
🎓 Academic Research & Data Science
- Sociological Data: High-fidelity datasets for studying online behavior, tribalism, and social dynamics.
- LLM Training Corpora: Clean, structured conversational data for fine-tuning language models and sentiment engines.
- Interaction Networks: Build reply graphs to study information flow, echo chambers, and polarization.
- Policy Evolution: Track how community rules and norms change over time by analyzing historical metadata.
💰 Pricing
| Resource | Cost | Description |
|---|---|---|
| Actor Usage | $0.00001 | Runtime charge. Depends on execution duration and resource consumption. |
| Profile | $0.419 | One-time fee per run to extract community metadata (rules, wikis, etc.). |
| Post | $0.0048 | Per-post charge. Includes full metadata: title, body, media, and vote metrics. |
| Comment | $0.0012 | Per-comment charge. Includes full metadata: author, text, depth, and votes. |
🧜 How it Works

💻 Input Parameters
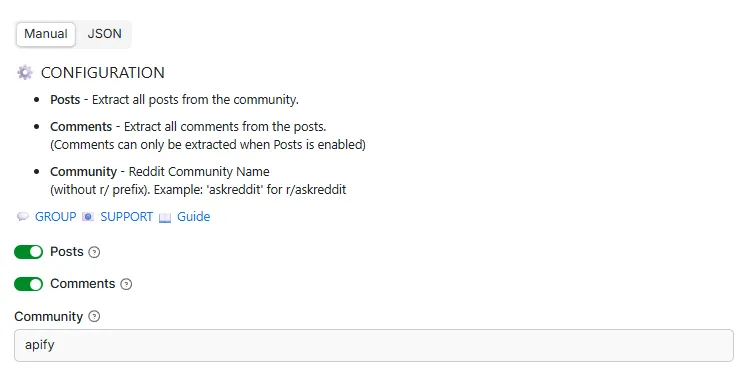
| Parameter | Type | Required | Description | Example |
|---|---|---|---|---|
community | string | ✅ | Target subreddit name (no r/ prefix) | apify |
posts | bool | ✅ | Set true to harvest submissions | true |
comments | bool | ✅ | Set true to harvest full comment trees | false |
📤 Output Structure

📊 Output Fields Description
| Field | Type | Description |
|---|---|---|
processor | string | URL of the Apify actor that processed this data |
processed_at | string | ISO 8601 formatted timestamp (UTC) when the data was processed |
id | string | Unique identifier of the Reddit community |
name | string | Display name of the Reddit community |
title | string | Header title of the community |
about | string | Public description of the community |
description | string | Full description of the community |
created | string | ISO 8601 formatted timestamp (UTC) when the community was created |
category | string | Advertiser category of the community |
type | string | Type of the subreddit (public, private, restricted, etc.) |
language | string | Language code of the community |
subscribers | integer | Number of subscribers in the community |
weighted_score | integer | Weighted score of the community |
accounts_active | integer | Number of currently active accounts (online users) |
icon | string | URL of the community icon |
banner | string | URL of the community banner image |
over_18 | boolean | Whether the community is marked as NSFW |
hide_ads | boolean | Whether ads are hidden in the community |
show_media | boolean | Whether media is shown in the community |
quarantine | boolean | Whether the community is quarantined |
allow_images | boolean | Whether images are allowed in the community |
allow_videos | boolean | Whether videos are allowed in the community |
allow_videogifs | boolean | Whether video GIFs are allowed in the community |
allow_galleries | boolean | Whether galleries are allowed in the community |
allow_polls | boolean | Whether polls are allowed in the community |
allow_talks | boolean | Whether talks are allowed in the community |
allow_discovery | boolean | Whether discovery is allowed in the community |
allow_predictions | boolean | Whether predictions are allowed in the community |
original_tag | boolean | Whether original content tag is enabled |
accept_followers | boolean | Whether the community accepts followers |
restrict_posting | boolean | Whether posting is restricted in the community |
restrict_commenting | boolean | Whether commenting is restricted in the community |
community_reviewed | boolean | Whether the community is reviewed |
stickies | array | Array of sticky posts in the community |
rules | array | Array of community rules |
wikis | array | Array of wiki pages in the community |
posts | array | Array of posts from the community |
Stickies Fields
| Field | Type | Description |
|---|---|---|
id | string | Unique identifier of the sticky post |
title | string | Title of the sticky post |
url | string | Direct link to the sticky post |
Rules Fields
| Field | Type | Description |
|---|---|---|
priority | integer | Priority order of the rule |
created | string | ISO 8601 formatted timestamp (UTC) when the rule was created |
name | string | Short name of the rule |
kind | string | Type of the rule |
description | string | Full description of the rule |
reason | string | Violation reason for the rule |
Wiki Fields
| Field | Type | Description |
|---|---|---|
name | string | Name of the wiki page |
edited | string | ISO 8601 formatted timestamp (UTC) when the wiki page was last edited |
edited_by | string | Username of the user who last edited the wiki page |
content | string | Markdown content of the wiki page |
Post Fields
| Field | Type | Description |
|---|---|---|
id | string | Unique identifier of the post |
author | string | Username of the post author |
created | string | ISO 8601 formatted timestamp (UTC) when the post was created |
edited | string | ISO 8601 formatted timestamp (UTC) when the post was last edited |
url | string | Direct link to the Reddit post |
subreddit | string | Name of the subreddit |
flair_text | string | Flair text of the post |
title | string | Title of the Reddit post |
body | string | Text content of the post |
score | integer | Net score of the post |
upvotes | integer | Number of upvotes |
downvotes | integer | Number of downvotes |
crossposts | integer | Number of crossposts |
archived | boolean | Whether the post is archived |
locked | boolean | Whether the post is locked |
stickied | boolean | Whether the post is stickied |
pinned | boolean | Whether the post is pinned |
hidden | boolean | Whether the post is hidden |
over_18 | boolean | Whether the post is marked as NSFW |
spoiler | boolean | Whether the post contains spoilers |
original | boolean | Whether the post is original content |
advertising | boolean | Whether the post was created from ads UI |
indexable | boolean | Whether the post is robot indexable |
crosspostable | boolean | Whether the post can be crossposted |
thumbnail | string | URL of the post thumbnail |
media_url | string | URL of the media content |
no_follow | boolean | Whether the post has no follow attribute |
weighted_score | integer | Weighted score of the post |
duplicates | array | Array of duplicate post links |
comments | array | Array of comments on the post |
Comment Fields
| Field | Type | Description |
|---|---|---|
id | string | Unique identifier of the comment |
is_root | boolean | Whether this is a root comment |
created | string | ISO 8601 formatted timestamp (UTC) when the comment was created |
edited | string | ISO 8601 formatted timestamp (UTC) when the comment was last edited |
author | string | Username of the comment author |
body | string | Text content of the comment |
upvotes | integer | Number of upvotes |
downvotes | integer | Number of downvotes |
score | integer | Net score of the comment |
archived | boolean | Whether the comment is archived |
locked | boolean | Whether the comment is locked |
stickied | boolean | Whether the comment is stickied |
submitter | boolean | Whether the comment is from the post submitter |
parent_id | string | ID of the parent comment |
reply_level | integer | Depth level of the comment in the thread |
url | string | Direct link to the comment |
🔌 Integrations
Seamlessly connect this actor to your existing pipelines via the Apify API.
🆔 Actor ID:
Python Client
Node.js Client
🦜 LangChain
You can also use this actor as a document loader in LangChain to power your RAG pipelines with Reddit data.
🏗️ Metadata for Developers (JSON-LD)
🚀 Performance Tips
Optimize your runs for speed, cost, and reliability with these best practices:
💰 Cost Optimization
- Start Small: Test with
posts=trueandcomments=falseon a small subreddit before scaling up. - Monitor Compute Units: Large runs (hundreds of posts with comments) can consume significant resources. Check the "Usage" tab in your Apify Console for real-time cost tracking.
- Set Limits: If you only need recent data, consider limiting your scope rather than scraping entire subreddits.
⚡ Speed Optimization
- Posts Only Mode: If you don't need comments, disable comment harvesting to reduce runtime by 70-90%.
- Parallel Runs: For multiple subreddits, create separate runs instead of batching to leverage parallel processing.
- Peak Hours: Avoid Reddit's peak traffic hours (9 AM - 5 PM EST) to reduce rate limiting delays.
🛡️ Reliability Best Practices
- Validate Input: Always verify the subreddit name is correct and publicly accessible before running large jobs.
- Monitor Progress: Use the Apify Console's live log view to track real-time scraping progress and catch errors early.
- Retry Logic: If a run fails mid-execution, the actor will save partial results. Contact support for recovery assistance.
📊 Data Quality Tips
- Full Context: Enable
comments=truefor sentiment analysis to capture reply trees and context. - Fresh Data: Reddit updates frequently. Schedule regular runs (daily/weekly) for time-series analysis.
- NSFW Filtering: Check the
over_18field in output to filter adult content if needed.
❓ FAQ
Is it legal to scrape Reddit data?
Yes, scraping publicly available data is generally considered legal, provided you respect personal data regulations (like GDPR/CCPA) and do not harm the website's infrastructure. This actor uses intelligent rate limiting to ensure compliance with Reddit's technical guidelines and only accesses public communities.
How to get Reddit comments to Excel?
After the run completes, go to the Output tab in the Apify Console. Click the Export button and select Excel format. You will receive a neatly formatted spreadsheet with all posts and nested comments flattened for easy analysis.
Best Reddit scraper for sentiment analysis?
This actor is optimized for sentiment analysis because it captures the full conversation context. Unlike simple scrapers that only get top-level comments, we retrieve the entire reply tree, allowing you to analyze how sentiment evolves throughout a discussion thread.
How do I format the subreddit name?
Enter the subreddit name without the r/ prefix. For example, use askreddit for r/askreddit, or programming for r/programming. The actor will automatically handle the subreddit lookup. If you receive an error, verify the subreddit exists and is publicly accessible.
Can I scrape full comment trees along with posts?
Yes. Set posts=true to enable submission harvesting and comments=true if you also want every thread expanded. Note that comments can only be extracted when posts collection is enabled. The actor charges events separately and halts safely if a billing attempt fails.
How long does it take to scrape a subreddit?
Runtime primarily depends on how many posts you request and whether full comment harvesting is enabled. Smaller pulls (tens of posts without comments) usually finish in under a minute, while large runs that fetch hundreds of posts plus complete comment trees can take several minutes because we have to pace requests to avoid throttling.
How do I estimate and control my scraping costs?
Costs are calculated per resource: Profile ($0.419 fixed), Post ($0.0048/item), and Comment ($0.0012/item).
Formula: ($0.419) + (Posts * $0.0048) + (Comments * $0.0012) + Runtime
⚖️ Legal & Compliance
This actor scrapes publicly available data only. It does not log in, access private communities, or touch personal user data. You are responsible for adhering to Reddit's Terms of Service and applicable privacy laws (GDPR/CCPA).
🏷️ Reddit Community Analyzer
🔥 Search Terms: reddit community analyzer, subreddit analytics tool, reddit osint tool, reddit sentiment analysis, subreddit data export, reddit brand monitoring, reddit comment scraper, reddit post scraper, subreddit monitoring api, reddit community insights, reddit moderation audit, subreddit rule export, reddit engagement tracker, reddit community research, subreddit analysis platform, analyze subreddit traffic, reddit community metrics, download subreddit comment tree, scrape reddit comments to excel, reddit trend analysis tool, subreddit user overlap, reddit marketing intelligence, reddit crisis monitoring, subreddit health check
💼 Use Case: community-intelligence reddit-monitoring brand-monitoring osint market-research content-moderation trust-and-safety digital-investigations engagement-analytics policy-audit competitive-analysis reputation-tracking creator-vetting threat-monitoring sentiment-analysis trend-forecasting audience-segmentation crisis-management product-launch-tracking
- Reddit User Analyzer - Get detailed profiles of Reddit users. The Reddit User Analyzer extracts comment history, activity patterns, and interests for comprehensive user behavior analysis.
- Reddit Community Analyzer - Analyze Reddit communities deeply with the Reddit Community Analyzer. Gain insights into subreddit engagement, user sentiment, and trending topics for data-driven decisions.
- Reddit Trends Analyzer - Track and visualize emerging trends on Reddit. The Reddit Trends Analyzer helps marketers and researchers spot viral topics and discussions in real-time.
- Job Search Engines - Aggregate job listings from multiple search engines in one place. Our Job Search Engines tool streamlines recruitment data extraction for better hiring insights.
- Glassdoor Jobs - Scrape job listings, reviews, and salaries from Glassdoor with our Glassdoor Jobs API. Extract valuable employment data for market research and competitive analysis.
- Indeed Jobs - Automate your job search data collection with the Indeed Jobs Scraper. Extract detailed job postings, company reviews, and salary information from Indeed efficiently.
- LinkedIn Jobs - Extract LinkedIn job postings at scale. The LinkedIn Jobs Scraper provides detailed data on job openings, requirements, and company details for recruitment professionals.
- Telegram Message - Scrape and archive Telegram messages from public channels and groups. The Telegram Message tool enables efficient monitoring and data preservation for researchers.
- Telegram Profile - Extract public profile information from Telegram users and channels. Our Telegram Profile Scraper helps in gathering contact details and bio data for lead generation.
- Telegram Scraper - A comprehensive Telegram Scraper for channels, groups, and users. Automate the extraction of messages, media, and metadata from Telegram efficiently.
- 4K Video Downloader - Download high-quality 4K videos from various platforms effortlessly. Our 4K Video Downloader ensures fast, secure, and crystal-clear downloads for offline viewing.
- TikTok Video Downloader - Download TikTok videos without watermarks. Our TikTok Video Downloader allows for bulk saving of trending content for offline access and reposting.
- TikTok Live Recorder - Record TikTok Live streams automatically. The TikTok Live Recorder captures real-time broadcasts in high quality for archiving, content creation, and analysis.
- Video To Text - Convert video content into accurate text transcripts. Our Video To Text tool supports multiple formats and languages, perfect for content accessibility and SEO.
- Youtube Video Downloader - Download YouTube videos in various resolutions and formats. The Youtube Video Downloader offers a fast and reliable way to save your favorite content offline.
- Social Media Marketing - Optimize your social media strategy with our Social Media Marketing tools. Automate data collection and analysis to boost engagement and ROI across platforms.
🤝 Support & Community
- 📧 Support: Contact us | 💬 Community: Telegram Group