Reddit Scraper & MCP Server – Posts, Comments, Users
Pricing
from $0.05 / 1,000 results
Reddit Scraper & MCP Server – Posts, Comments, Users
Reddit scraper + MCP server for AI agents. Search Reddit by keyword, get subreddit feeds, extract posts, comments & user profiles as JSON. No API key or login. Connect Claude, Cursor, or ChatGPT to the built-in MCP server. Runs on residential proxy.
Pricing
from $0.05 / 1,000 results
Rating
0.0
(0)
Developer
opportunity-biz
Maintained by CommunityActor stats
0
Bookmarked
4
Total users
0
Monthly active users
25 days ago
Last modified
Categories
Share
Reddit Search AI — Scraper + MCP Server for AI Agents
Search Reddit, read subreddit feeds, pull comments and user history — as clean JSON, or as a live MCP server your AI agent can call directly.
No Reddit API key. No login. No OAuth. No proxy to configure. Pick a mode, hit run, get fresh structured data. Or connect Claude / Cursor / ChatGPT to the built-in MCP server and let the model search Reddit itself.
Why this Actor when other Reddit scrapers keep breaking? Reddit has aggressively locked down public access — most scrapers now fail with 403 errors. This Actor uses its own always-fresh data pipeline, so you get reliable, up-to-the-minute Reddit data with zero setup — no API keys, no proxies, no blocks to fight.
🎯 What you get
- 🔍 Keyword search — find posts by topic (scope to a subreddit for the freshest results)
- 📰 Subreddit feeds — the latest posts from any community, newest first
- 💬 Posts + comments — extract discussions for sentiment & market research
- 👤 User profiles — a user's posts, comments, or full overview
- 🤖 MCP server — Reddit tools any AI agent can call over Streamable HTTP
- 📦 Structured JSON — ready to drop into an LLM, a spreadsheet, or a pipeline
🚀 Quick start (60 seconds)
- Open the Actor and click Try for free.
- Choose a mode (default: 🔍 Keyword Search).
- Enter a subreddit (e.g.
technology) or a keyword. - Click Start. Your results appear in the Output tab as JSON.
That's it — no proxy or API-key setup. Export to JSON/CSV/Excel, or grab results from the API.
📖 Modes & examples
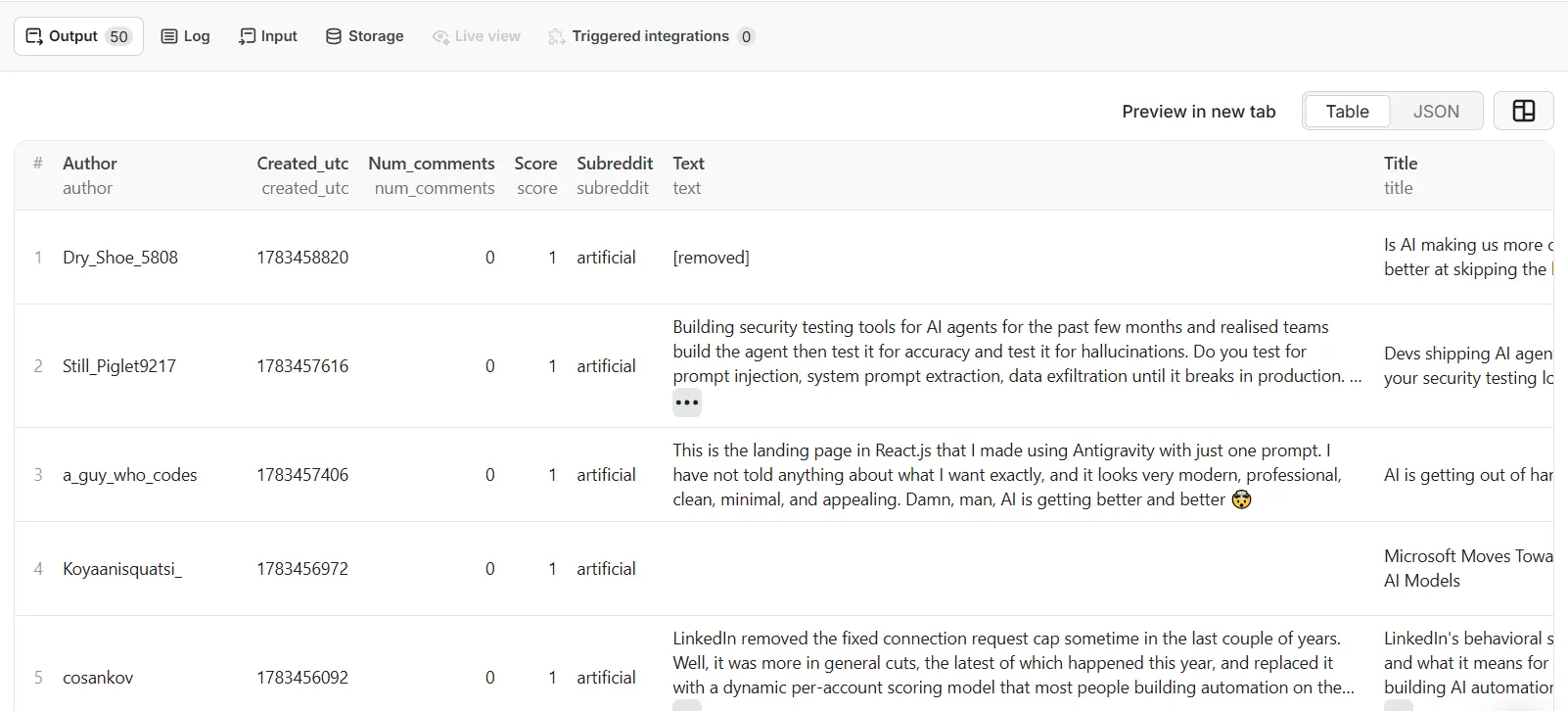
1. Subreddit feed — latest posts from a community
2. Keyword search — find posts by topic
Scope the search to a subreddit for the freshest, most relevant results:
3. User profile — a user's posts or comments
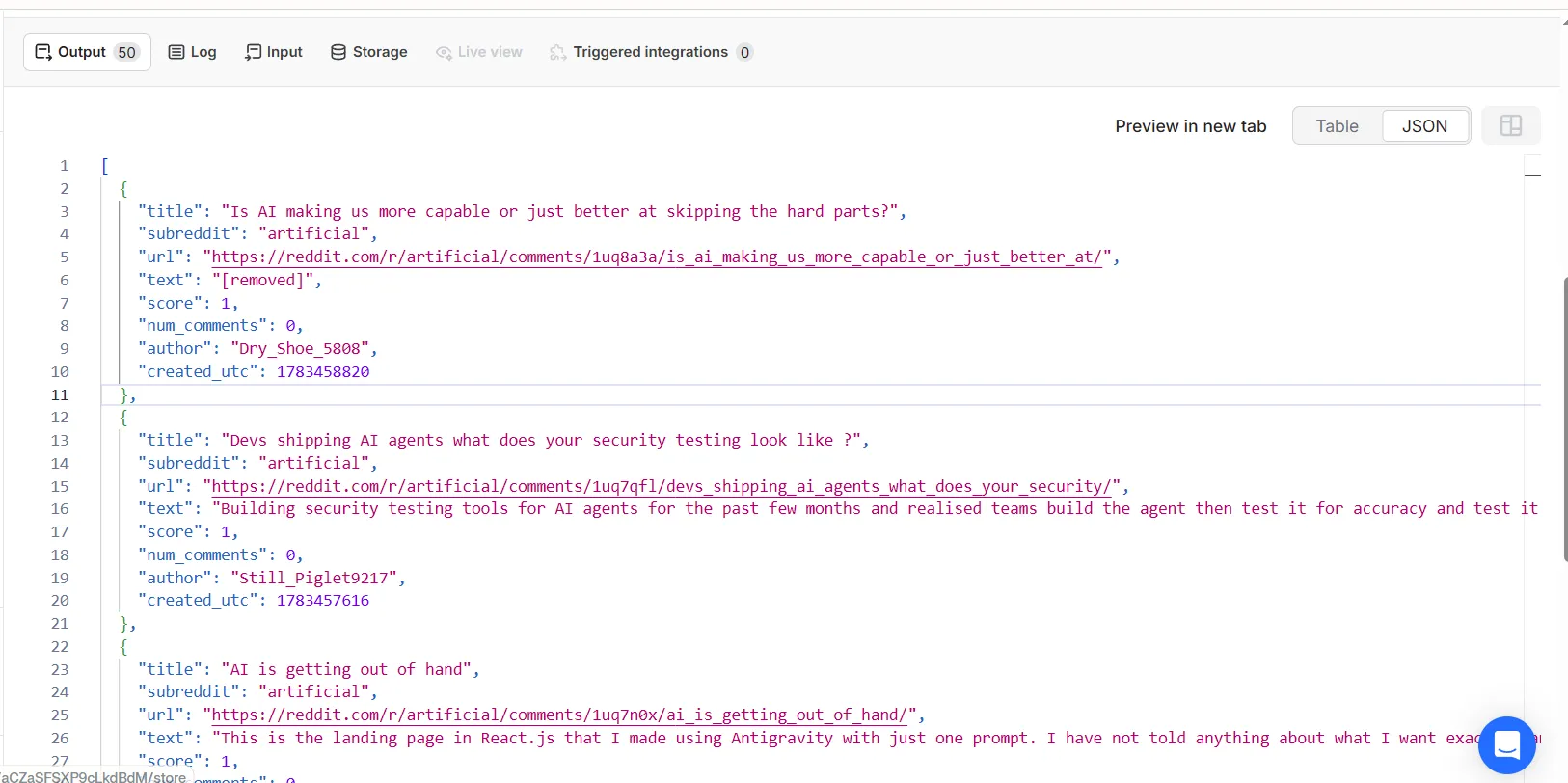
Sample output
Add "include_comments": true to attach comments to every post.
Every field comes back as clean JSON, ready for an LLM or a pipeline:
🤖 Use it as an MCP server (Claude, Cursor, ChatGPT…)
This Actor runs a native Model Context Protocol server in Standby mode, so an AI agent can search Reddit on its own — no glue code. Tools:
| Tool | What it does |
|---|---|
search_reddit | Search Reddit for posts by keyword (scope with a subreddit) |
get_subreddit_posts | Latest posts from a subreddit |
get_post_with_comments | A post + its comment thread |
get_user_posts | Posts submitted by a user |
get_user_comments | Comments written by a user |
Connect from Claude Desktop / Cursor / VS Code
The MCP endpoint is the Actor's Standby URL + /mcp:
Get YOUR_APIFY_TOKEN from Apify Console → Settings → Integrations. Then ask your agent things like "What are people on Reddit saying about the new M5 MacBook?" and it will call the tools automatically.
Tip for AI agents: open
https://opportunity-biz--reddit-scraper.apify.actor/?token=…to get a JSON description of the server and its tools.
🔌 API usage
cURL — start a run
Python
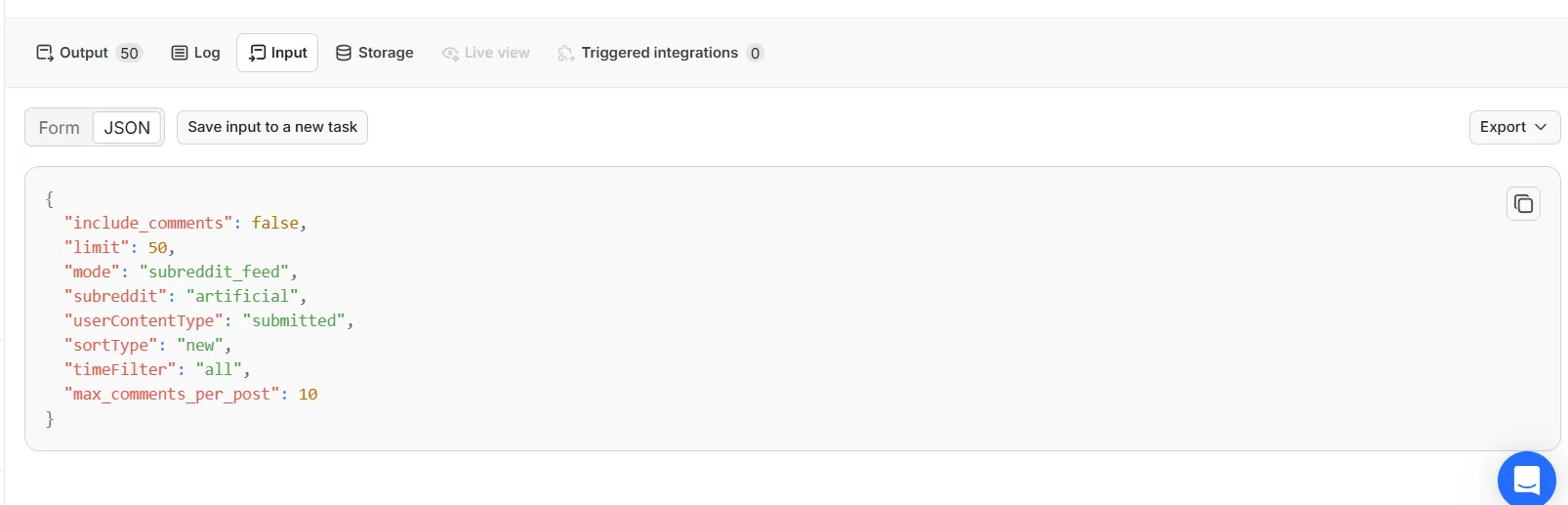
⚙️ Input parameters
| Field | Type | Default | Description |
|---|---|---|---|
mode | enum | keyword_search | keyword_search, subreddit_feed, user_profile, mcp_server |
keyword | string | "" | Keyword for keyword search |
keywords | array | [] | Multiple keywords in one run |
subreddit | string | "" | Subreddit for feed mode (and to scope keyword search) |
usernames | array | [] | Usernames for profile mode |
userContentType | enum | submitted | submitted, comments, overview |
limit | integer | 20 | Max results to return |
include_comments | boolean | false | Attach comments to each post |
max_comments_per_post | integer | 10 | Comments per post (max 100) |
Posts are returned newest first. No proxy or API-key configuration is required — the Actor handles data access for you.
💡 Use cases
- Market & product research — what people actually say about a brand, tool, or trend
- Lead gen / social listening — find threads asking for solutions you provide
- AI agents & RAG — feed fresh Reddit discussion into an LLM via the MCP server
- Sentiment & trend tracking — monitor a subreddit or keyword over time
- Content & SEO research — discover real questions and pain points
📝 Notes & limits
- Public subreddits only.
textand comment bodies are truncated to 500 chars — use the posturlfor the full content.- Posts are ordered newest-first.
- Please use sensible
limitvalues and avoid hammering the Actor with high concurrency.
❓ FAQ
How do I scrape Reddit without the API? Pick a mode (keyword search, subreddit feed, or user profile), enter your query, and run. You get structured JSON back — no Reddit API key, OAuth, developer app, or proxy setup required.
Do I need a Reddit account, API key, or proxy? No. No account, no login, no OAuth, no API key, and no proxy to configure. Just an Apify token to call the Actor.
Why do other Reddit scrapers return 403 / no results and this one works? Reddit blocks most anonymous access now. This Actor uses its own always-fresh data pipeline instead, so it keeps returning real, current Reddit data with no setup on your side.
Is there a Reddit MCP server for Claude / Cursor / ChatGPT?
Yes — this Actor is a Reddit MCP server. Add its Standby /mcp URL to your MCP client and your AI agent gets Reddit search, feeds, comments, and user tools. See "Use it as an MCP server" above.
Can I get comments and analyze sentiment?
Yes. Set include_comments: true to attach comments to each post, or use the get_post_with_comments MCP tool — ideal for sentiment analysis and market research.
Can I monitor a keyword or subreddit over time? Yes. Create a Task with your settings and Schedule it to run on an interval, appending fresh posts/comments to your dataset.
📦 Changelog
| Version | Changes |
|---|---|
| 0.2 | New always-fresh data pipeline — reliable, up-to-the-minute results with no proxy or API key; no more 403 failures. MCP Standby server with 5 Reddit tools. |
| 0.1 | Fixed startup crash; real MCP Standby server + readiness probe |
| 0.0.21 | MCP server, Streamable HTTP |
| 0.0.20 | User profiles, pagination |
| 0.0.19 | Subreddit feed, comment scraping, batch search |
| 0.0 | Initial release — keyword search |