Instagram Comment Scraper
Pricing
from $1.50 / 1,000 comments
Instagram Comment Scraper
Scrape comments from Instagram posts and reels without login. Supports multiple URLs, pagination, rate limit handling, and proxy configuration.
Pricing
from $1.50 / 1,000 comments
Rating
0.0
(0)
Developer
Rigel Bytes
Maintained by CommunityActor stats
0
Bookmarked
7
Total users
0
Monthly active users
a month ago
Last modified
Categories
Share
Extract every comment from Instagram posts and reels — just drop a URL and get usernames, comment text, likes, timestamps, and profile data. Perfect for sentiment analysis, influencer research, community management, and brand monitoring at scale.
What can Instagram Comment Scraper do for you?
- Scrape all comments from any post or reel — No login required. Works with single posts or bulk URLs.
- Full commenter profile data — Username, profile picture, verification status, and profile link for every commenter.
- Likes, timestamps, and engagement signals — See how many likes each comment received and exactly when it was posted.
- Reply-aware structure — Parent-comment IDs let you reconstruct nested conversation threads.
- Built-in rate-limit handling — Automatic cooldown and retry mechanisms keep your scrape running smoothly even on high-volume posts.
- Proxy support — Use Apify residential proxies or bring your own for geo-targeted extraction.
What data can you extract?
| Field | Description |
|---|---|
| 🖼️ Profile Pic | Avatar URL of the commenter |
| 👤 Username | Instagram handle |
| 💬 Comment Text | The full comment content |
| ❤️ Likes | Number of likes on the comment |
| 🕐 Created At | Timestamp of when the comment was posted |
| 🔗 Profile Link | Direct link to the commenter's profile |
| 📎 Post URL | The original post or reel URL |
Why use this scraper?
- Market Research — Analyze what audiences are saying about brands, products, or campaigns under Instagram posts.
- Influencer Due Diligence — Assess engagement quality by reviewing real comments and commenter authenticity.
- Community Management — Monitor comments across your owned posts or competitor content for sentiment and feedback.
- Content Automation — Feed scraped comments into NLP pipelines for trend analysis, topic clustering, or moderation workflows.
How to use Instagram Comment Scraper
- Create a free Apify account at apify.com and get your API token.
- Open the Instagram Comment Scraper page on Apify Console.
- Paste one or more Instagram post/reel URLs into the
post_urlsfield. - Configure optional settings — concurrency, delays, max comments per post, and proxy preferences.
- Click Start and download your data as JSON, CSV, or XLSX when the run finishes.
Pricing
| Model | Price |
|---|---|
| Per 1,000 comments | $1.5 |
No hidden fees or limits on usage. Each actor run also incurs a small platform start fee. Save up to 20% by purchasing an Apify subscription plan.
Input
The actor accepts the following configuration:
- post_urls (
array[string], required) — List of Instagram post or reel URLs to scrape comments from. - posts_concurrency (
integer, optional, default:2) — Number of posts to scrape concurrently. - sleep_min (
number, optional, default:5) — Minimum random delay between pagination requests (seconds). - sleep_max (
number, optional, default:12) — Maximum random delay between pagination requests (seconds). - request_timeout (
number, optional, default:120) — Timeout per GraphQL request (seconds). - request_retries (
integer, optional, default:1) — Retries for transient request failures. - rate_limit_cooldown (
number, optional, default:100) — Wait time after hitting a rate limit (seconds). - rate_limit_max_waits (
integer, optional, default:3) — Max rate limit cooldowns before stopping for a post. - max_comments (
integer, optional, default:100) — Maximum comments to scrape per post. Set0for unlimited. - proxyConfiguration (
object, optional) — Proxy settings. Supports Apify proxy groups (recommended:RESIDENTIAL) or custom proxy URLs.
📝 Copy for Use:
Why Choose This Scraper?
- Affordable: Pay only $1.5 per 1,000 comments with no hidden fees or minimum commitments.
- Comprehensive: Extract every comment — including text, likes, timestamps, profile data, and reply structure.
- Easy to Use: Paste a URL, configure optional settings, and start scraping in under a minute.
- Reliable: Built with automatic rate-limit handling, retry logic, and configurable delays for uninterrupted scraping.
Output
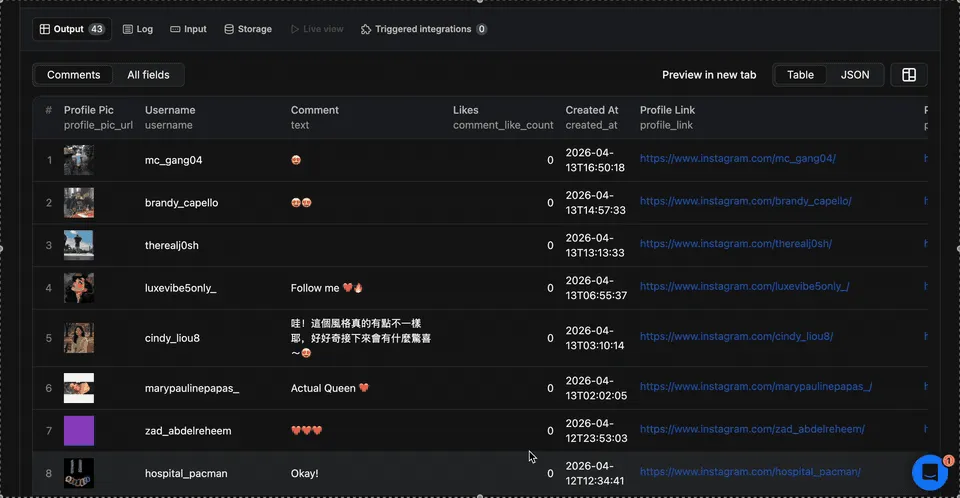
API Examples
Python
JavaScript
cURL
Detailed Data
🚀 Other Tools by Rigel Bytes
Extracts all photos from Airbnb listing pages and packages them into a compressed archive.
Extracts structured property listing data from Zillow for real estate analysis and monitoring.
Comprehensive Zillow property scraper with customizable proxy support for detailed real estate data.
Extracts product listings and seller data from Daraz.pk for ecommerce monitoring and analysis.
Bulk-extracts structured Airbnb listing data including metadata, descriptions, and property features.
Extracts structured business profiles and local place intelligence from Google Maps at scale.
Exports Airbnb listing availability calendars as structured per-date data.
Extracts detailed Instagram profile and media metadata including follower counts and engagement.
Crawls Land.com property listings and extracts structured real estate data.
Extracts unlimited reviews from Airbnb listings with reviewer profiles and ratings.
Extracts large-scale furnished rental data from Furnished Finder with full listing details.
Scrapes immobilienscout24.de for real estate listings and contact data at scale.
Extracts unlimited Airbnb listing URLs from search queries with structured metadata.
Analyzes Instagram profiles and computes engagement metrics for posts and videos.
Extracts every post from Instagram profiles with structured post-level metadata and media.
Extracts detailed business listings from the Better Business Bureau (BBB).
Extracts structured company profiles from LinkedIn for lead generation and intelligence.
Comprehensive LinkedIn company profiles and social content extraction.
Extracts all Instagram Reels from public profiles with structured reel metadata.
Collects user and critic reviews from Rotten Tomatoes with structured review records.
Scrapes Furnished Finder for listing and host profile data with geolocation details.
Collects Trustpilot reviews and reviewer profiles at scale.
Scrapes Furnished Finder rental listings and host profiles with structured data output.
Extracts Zillow agent profiles and data for location-based queries.
Extracts structured UAE property listings and market intelligence from Bayut.com.
Extracts UAE property listings for sale and rent across Dubai and Abu Dhabi.
Extracts all comments from TikTok videos with commenter metadata.
Analyzes TikTok profiles and computes engagement metrics from recent videos.
Scrapes business listings from Google Search and Maps across cities and states.
Extracts and AI-analyzes company services from business websites.
Bulk-extracts Airbnb listing addresses and comprehensive listing metadata.
Scrapes unlimited real estate listings from immowelt.de with structured property data.
Extracts unlimited real estate listings from propertyfinder.ae at scale.
Extracts grocery product data from Publix with delivery/pickup location support.
Extracts large-scale real estate listings from Redfin with structured property records.
Extracts structured product data from Instacart using search and location.
Crawls Home Depot collection pages with location-aware product extraction.
Extracts healthcare provider and practice data from Doctify.
Extracts structured ad data from Facebook Ads Library with creative assets.
Extracts structured event metadata from Ticketmaster by location and date.
Extracts detailed Instagram creator profiles and media-level information.
Harvests large volumes of German real estate listings from immowelt.de.
Extracts real estate listings and contact data from immobilienscout24.de.
Analyzes Instagram profiles and computes engagement metrics for creator analysis.
Extracts structured product data from Etsy across categories, searches, and product pages.
Scrapes Rightmove.co.uk property listings with structured real estate data.
Extracts rental listing data from Outdoorsy search results.
Understanding Proxies
When scraping data or browsing anonymously, proxies are essential. They act as intermediaries, masking your original IP address and allowing you to send requests from another location.
Why Use Proxies?
- Avoid IP Blocks — By routing requests through proxies, you prevent the target website from recognizing your IP as a scraper or spammer.
- Access Geo-restricted Content — Proxies let you access content or websites restricted by location.
- Enhance Anonymity — Hide your actual IP, ensuring privacy while scraping or browsing.
Types of Proxies
- Residential Proxies — Real IPs from ISPs that mimic regular users. Best for long-term, undetectable scraping.
- Data Center Proxies — Fast and cheap but easier to detect. Best for high-speed scraping with lower anonymity needs.
- Mobile Proxies — IPs from mobile carriers (3G/4G/5G). Very hard to detect — ideal for sophisticated scraping.
Rotating Proxies vs. Straight Proxies
- Rotating Proxies: Every request goes through a different proxy, making it harder for websites to detect scraping patterns.
- Straight Proxies: All requests use the same IP, which is easier to track but simpler to set up.
Recommended Proxy Providers
-
Shifter
- Reliable residential proxies worldwide
- Competitive pricing
- Order Shifter Now
- Get 10% off any product with coupon
rigelbytes-YoBB
-
OxyLabs
- 100M+ proxy pool
- Fast residential and data center proxies
- Real human-like residential IPs with quality assurance
- Get OxyLabs Proxies
-
DataImpulse
- Covers 200+ countries
- Residential proxies from just $1/GB
- Get DataImpulse Proxies
🙌 Why Buy Through Our Affiliate Link?
- Exclusive Deals: Some providers offer special discounts when you use our link.
- Support Our Work: Each purchase helps us maintain and improve the tools and services we provide.
- No Extra Cost: You pay the same price, but part of it goes to supporting our efforts.
About Rigel Bytes
Rigel Bytes specializes in web scraping, automation, and data analytics. We help businesses extract and leverage valuable data for informed decision-making.
Contact Us
Ready to unlock the power of data? Reach out to us at contact@rigelbytes.com or book an appointment with us to learn more about how we can help you achieve your data goals.