Business Data Enricher — Clean, Match & Verify Listings
Pricing
$4.00 / 1,000 resolved places
Business Data Enricher — Clean, Match & Verify Listings
Business data enrichment against Overture Maps POI data. Cleans and deduplicates by name + location, assigns stable GERS global IDs, grades data quality, flags leads (no website, unbranded). Resale-safe records. Territory mode pulls in bulk and tracks openings, closures and rebrands over time.
Pricing
$4.00 / 1,000 resolved places
Rating
0.0
(0)
Developer
Ryan Clinton
Maintained by CommunityActor stats
0
Bookmarked
2
Total users
1
Monthly active users
a month ago
Last modified
Categories
Share
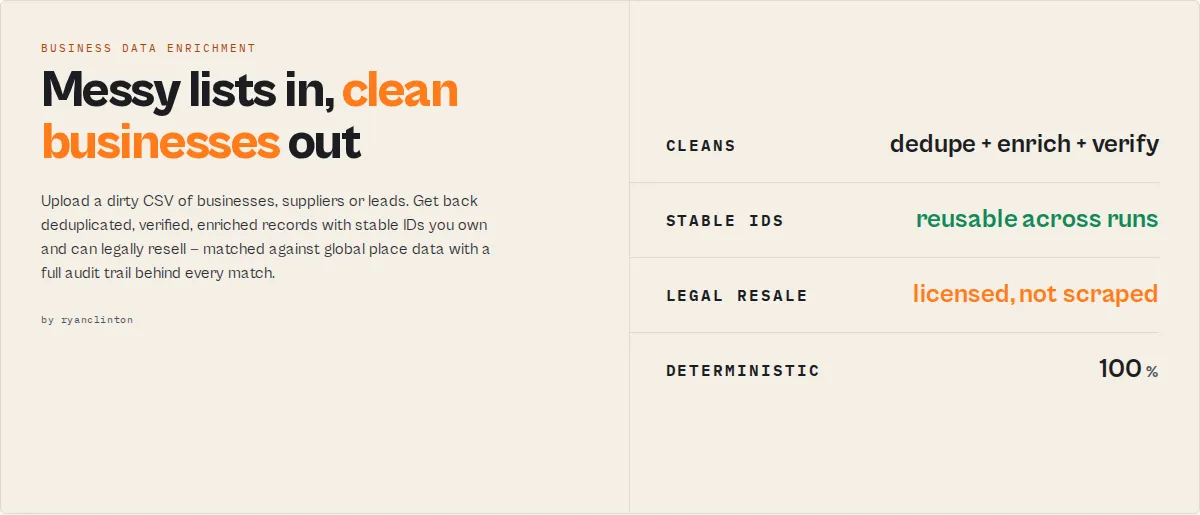
Clean, verify and enrich business lists at scale. Upload a messy CSV of businesses, suppliers, store locations or leads — this business data enrichment actor removes duplicates, verifies each record against global place data, fills in missing details (category, website, socials), and assigns a stable ID you can reuse in every future run. You get back clean records you own and can legally resell.
This is not a Google Maps scraper. You bring a dirty list (a CRM export, store locations, a supplier sheet, a local business data export you already paid for) and get back canonical, deduplicated, enriched businesses — verified against global place data, with a full audit trail behind every match.
What this is NOT. Not a Google Maps replacement — Overture Maps, the open place dataset behind this actor, is monthly-refreshed and carries no live reviews, ratings, opening hours, or popular times. For "today's hours and current star rating," Google Maps wins. This actor wins on bulk, legal resale, stable global IDs, and analytics — the four things a Maps scraper structurally cannot give you.
Who is this for?
- Lead-generation agencies — find businesses with no website, no socials, or unbranded independents: ready-to-pitch lists straight out of the run.
- Local SEO agencies — map a local market, benchmark competitor density, deduplicate a client's locations.
- Business directories & marketplaces — dedupe listings and assign stable IDs so the same place never appears twice, and safely merge future data sources onto the same ID.
- Data teams — clean and enrich a large business/place dataset against ground truth, with a stable join key for your warehouse.
- Retail & franchise teams — territory coverage, brand penetration, and competitor density for a catchment area.
- Market researchers — canonical place data you can legally build a product on.
What it does, in one example
Input — three messy rows:
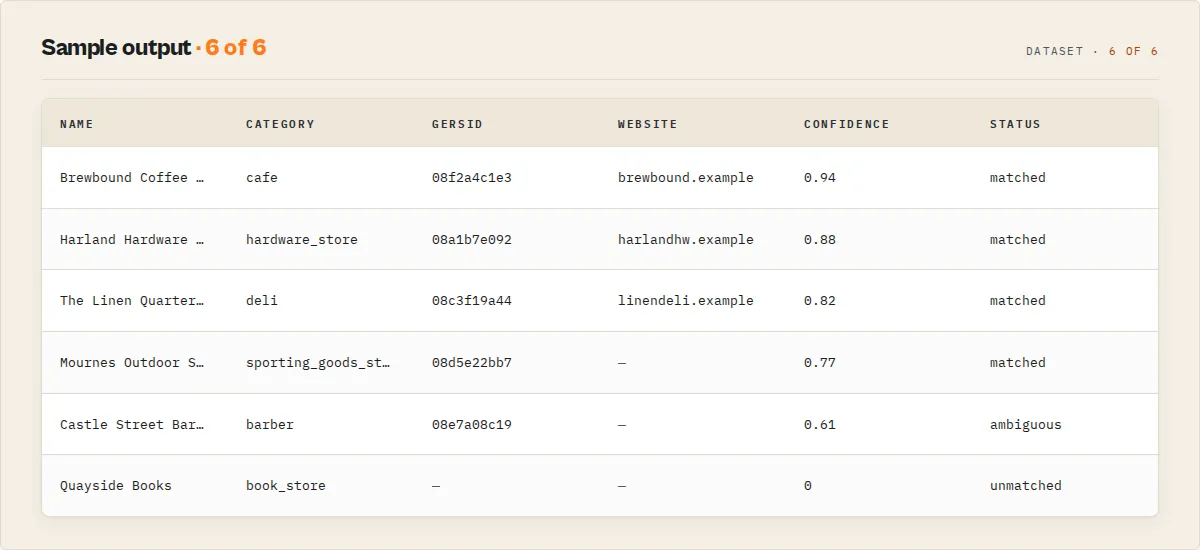
Output — each row resolved to a clean, enriched record:
…the two "Domino's" rows collapse onto one record, and "Maccies" resolves to McDonald's via the brand short-circuit.
Result: 3 rows → 2 verified businesses, 1 duplicate removed, 100% matched — each enriched with category, website, socials and a stable ID you can pass back next run.
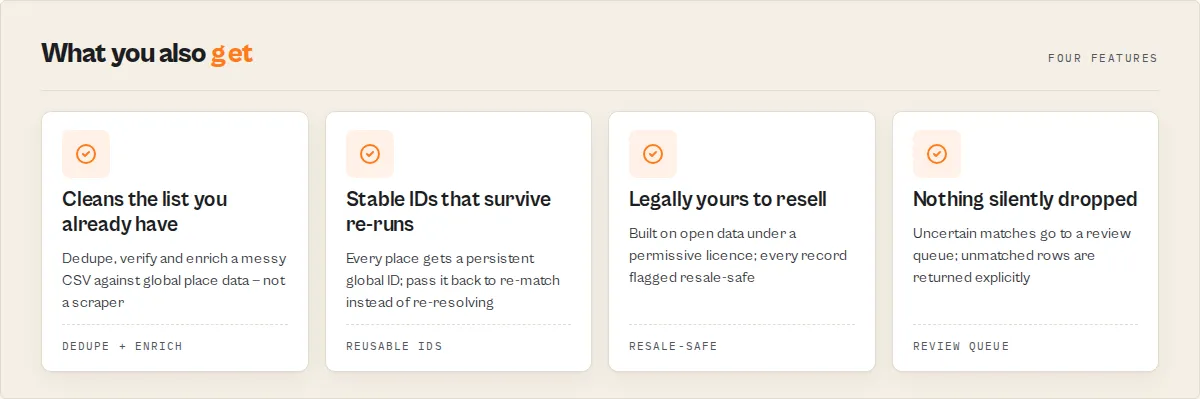
How accurate is it? Every match carries a confidence score and the exact reasons behind it. Uncertain matches go to a review queue instead of being guessed, and rows that don't match are returned explicitly — nothing is ever silently dropped.
Enrichment fields like
website,socialsandphoneare filled where the source carries them — coverage varies by place and region (densest in US/EU and urban areas). The actor never invents a value; a field the source doesn't have comes back empty. Match rates likewise depend on your input quality and region; the run summary reports yours.
Business Data Enricher vs a Google Maps scraper
Most place-data actors extract listings. This one resolves them — and does the things a scraper structurally can't on a list you already have:
| Task | Google Maps scraper | Business Data Enricher |
|---|---|---|
| Get a list of places | ✅ | ✅ |
| Deduplicate your list | ❌ | ✅ |
| Stable IDs that survive re-runs | ❌ | ✅ |
| Legally resell the output | ❌ | ✅ |
| Territory / competitor analytics | ❌ | ✅ |
| Review queue for uncertain matches | ❌ | ✅ |
| Re-match your existing records | ❌ | ✅ |
| Live reviews, ratings, opening hours | ✅ | ❌ |
The last row is the honest trade: for today's star rating and live hours, a Google Maps scraper wins. For cleaning, verifying and owning a list you already have, this does what a scraper can't.
Why choose this actor
- Bulk — query over 100M+ places without result caps, pagination limits or blocking.
- Legal resale — built on Overture Places under CDLA Permissive 2.0. Every record carries a
resaleSafeflag and an attribution string. (We query theplacestheme only — never the share-alike ODbL themes.) - Stable global IDs — every matched row is stamped with a GERS ID, a persistent global fingerprint, so your data becomes joinable to any other dataset using the same IDs, forever. Re-runs are idempotent: pass the stored
gersIdback and the actor does a direct lookup instead of re-resolving. - Analytics — density, brand concentration, franchise footprint (per-brand saturation), market structure, whitespace and nearest-competitor analysis built right into the actor — impossible for a per-place scraper.
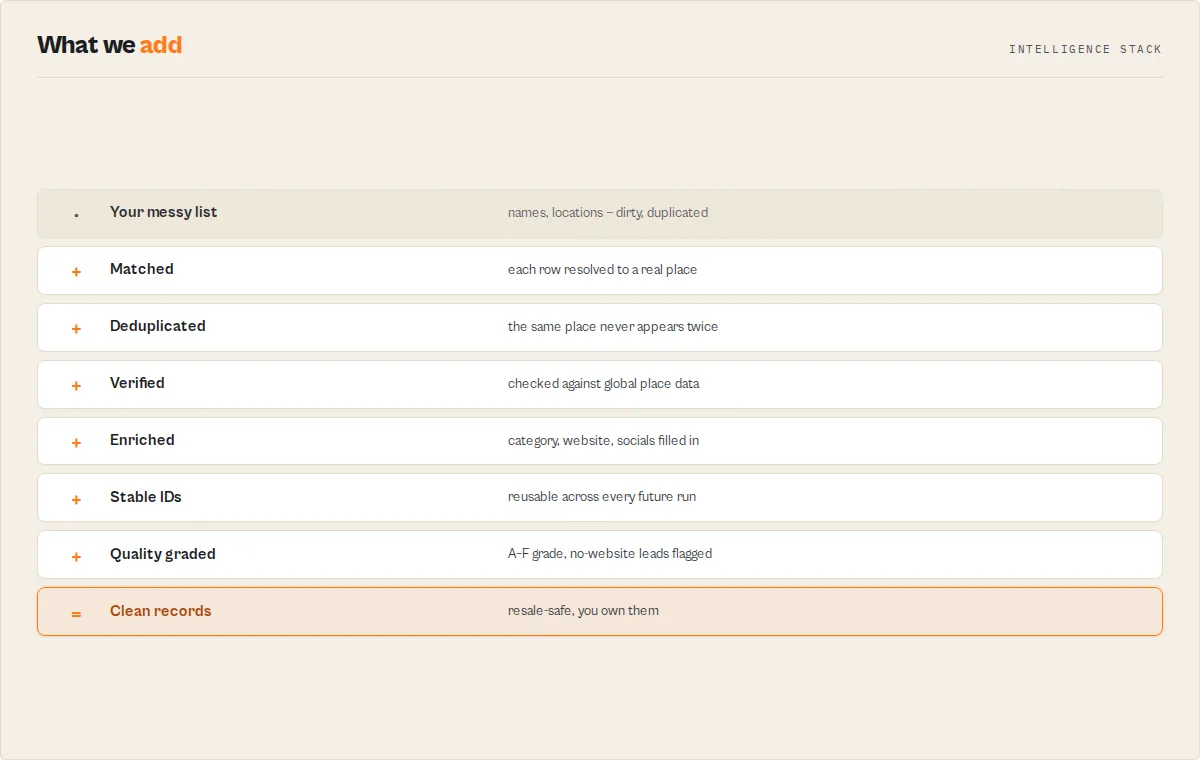
Clean and deduplicate your first business list in 60 seconds
Paste a list, press Start:
You get back canonical, deduped, enriched entities: the two Domino's rows collapse onto one GERS id (an entity-group record records the collapse), "Maccies" resolves to McDonald's via the brand short-circuit, and a run-summary record tells you the coverage, dedup, and review-queue headline. Every row is resale-safe.
Input modes (auto-detected)
| You provide | Mode | What you get |
|---|---|---|
places (BYO list) | resolution | one resolution record per input row + entity-group + review-item + run-summary |
territoryQuery (a bbox) | territory | every canonical entity in the area + a territory analytics summary |
any row carrying a gersId | idempotent re-match | direct lookup by stored ID — no re-matching |
Resolution input
Each item in places: { "name": "...", "lat": 54.58, "lng": -5.93 } or { "name": "...", "address": "..." }. Optional id (echoed as inputId), category (improves the category gate — e.g. an FSA business_type like "Restaurant/Cafe/Canteen" works as-is), and gersId (idempotent re-match).
The list scales from a handful of rows to tens of thousands spanning multiple cities or a whole country — resolved in a single run. Rows with no coordinates fall back to address-text matching at a lower, flagged confidence — but that's a full scan per row, so it's capped (supply lat/lng to resolve at scale; rows past the cap come back unmatched with an explanation, never silently dropped).
Territory input
territoryQuery: a bounding box "minLng,minLat,maxLng,maxLat", e.g. "-6.05,54.55,-5.80,54.65". Append a category filter after a pipe: "-6.05,54.55,-5.80,54.65 | coffee". Set outputProfile to territory, or just leave places empty.
Track what's changed in an area (event mode)
Run a territory with emitEvents: true and the actor diffs the current Overture release against an earlier one (over your bbox) and emits a commercial change feed — the thing a one-shot scrape can never give you:
- Typed events per place:
NEW_LOCATION,LOCATION_CLOSED,LOCATION_MOVED,REBRAND,CATEGORY_SHIFT, each with a severity score. - Brand expansion / contraction: which chains opened or closed net locations in the window (e.g. "Costa +4, Subway −2").
- Market warnings: categories with a high closure rate, stated with the denominator (
"8/12 closed"), never an investment verdict. - Successor candidates (opt-in
includeSuccessors): a place closed and a new one opened at the same coordinates — flagged as a candidate with a confidence, never asserted. - A decision-first
territory-digestrecord: openings, closures, expanding/contracting chains, warnings, lead count.
Leave compareRelease blank to auto-diff against the prior public release (a ~1-month window, available immediately). Set a watchlistName to snapshot each run into your own private history and track change across a longer window than the two public releases allow — the first run captures a baseline, changes are reported from the next run. The watchlist also builds a per-entity category timeline (categoryChangeHistory) and remembers your analyst review decisions (reviewDecisions input), echoing them back on the matching changes so a disposition survives re-runs.
Built on open data you can resell, this turns "scrape a place list" into "monitor a market" on the same engine.
Matching you can trust
Every place is matched on location, name and category together — never on name alone — and each match comes back with a confidence score and the reasons behind it, broken into its parts so you can see why it matched (or didn't).
- Close calls go to a review queue instead of being guessed — the actor never silently picks between two plausible candidates.
- Nothing is silently dropped — rows that don't match are returned explicitly as
unmatchedwith the best near-miss, so you always see what didn't resolve and why. - Fully deterministic — the same input always produces the same result. No black box, no model drift, no surprises.
You can tune precision vs recall with the matchProfile preset (strict / balanced / lenient) without touching anything else.
Output profiles (outputProfile)
enriched(default) — the full record:match,canonical,quality,lifecycle,leadSignals,digitalPresence,resaleSafe,agentContract.names— the lean display-name surface:{ inputId, gersId, name, normalizedCategory, confidence (with decomposed components), ambiguity, runnerUpGap, status }. The right profile if all you persist is "canonical name + a stable key + a score to threshold on."gers_only—{ inputId, gersId, confidence, status }. The minimal join key for a warehouse that already holds the names.audit— adds every candidate considered and why it was rejected. For tuning thresholds and proving matches.territory— bulk-pull canonical entities + the analytics summary.
Record types
Discriminate on recordType: resolution | entity-group | review-item | run-summary | canonical-entity | territory-summary. The dataset ships decision-first views — Matched, Review queue, Unmatched, Run summary — and a KV SUMMARY record mirroring the coverage/dedup/review headline.
Data quality grades, match confidence and lead signals
- Reason chain —
match.matchReason[]reads back, in plain language, why each match was made or rejected. - Per-attribute corroboration —
match.matchEvidenceisnulluntil your input row carries that field, so nothing is fabricated on data you never gave. - Data-quality axis —
quality(grade A–F, completeness, issues) is distinct frommatch.confidence. A confidently-matched place can still have a defect-laden record; the two questions get two answers. - Lifecycle band —
lifecycle.statusis a descriptive band over evidence (operating status, low confidence), never a fabricated "closed" verdict. - Lead signals —
leadSignals[](NO_WEBSITE, NO_INSTAGRAM, UNBRANDED, INDEPENDENT, …) off already-fetched data. "Dentists in this metro with no website" is a ready-to-sell list at no extra cost.
Key inputs
| Input | Default | Notes |
|---|---|---|
matchProfile | balanced | strict (precision-first) / balanced / lenient (recall-first). A preset threshold pack, not a rule engine. |
matchRadiusMeters | 150 | tighten (e.g. 50) for premise-accurate matches. |
nameSimStrong / nameSimWeak | 0.89 / 0.83 | power-user overrides; matchProfile sets these. |
overtureRelease | 2026-05-20.0 | the us-west-2 bucket retains only the latest ~2 releases. |
minConfidence | 0.5 | drop ground-truth candidates below this Overture confidence. |
includeLifecycle / emitLeadSignals | true | cheap, on by default. |
includeMarketContext / includeGlobalBrandStats / includeGraphEdges | false | opt-in extra reads. |
What this is not (stated up front)
- Not a Google Maps replacement — no live reviews, ratings, or hours.
- Coverage is uneven by region — best in US / EU / urban areas; thin-coverage regions match lower. The territory summary surfaces a
coverageConfidencesignal so you know where to trust the data. - Not a legal-entity → trading-name resolver — matching goes on the name as written. A divergent legal name vs trading name ("Bushmills Hotels Ltd" → "The Bushmills Inn") lands in the review queue rather than being forced. Known chains are still caught; divergent-name independents still need a human.
- Not a geocoder — no-coord rows get flagged address-text matching (capped — each is a full scan), not precise geocoding.
Pricing
Pay for hits, not for list size. $0.004 per resolved place — a confirmed match in resolution mode, or a returned canonical entity in territory mode. Unmatched rows, the review queue and all analytics are included free: a 50,000-row list that matches 18,000 places costs for the 18,000, not the 50,000. No proxies and no per-place data fees — Overture reads are anonymous and AWS-sponsored — so on top of the per-place charge you pay only Apify platform compute.
Attribution
Built on Overture Maps Places data, CDLA Permissive 2.0. Every output record carries the attribution string and a resaleSafe flag.
Deliver results to Slack or Notion (MCP connectors)
Optionally pipe each run's decisions — the resolution/territory digest plus the ranked review worklist — straight into your own Slack channel or Notion workspace. You never hand this actor a token: you connect Slack/Notion once in Apify Console → Settings → MCP connectors (Notion is one click), and Apify proxies the credentials. The actor only ever receives a connector id.
- Notion — set
notionConnector. Get a one-page resolution report (digest + top review items), or a page per review item withnotionArchiveProfile: per-review. - Slack — set
slackConnector(and optionallyslackChannel). The digest is posted, plus review items at or aboveslackMinReviewPriority(default 50) so the channel stays signal-only. (Slack connectors need you to register your own Slack OAuth app.)
Only the decisions are delivered — never the bulk resolution rows. Leave the connector fields empty and the run behaves exactly as before. The delivery outcome is reported back on the run-summary's deliveries block.