Logistics Freight Intelligence MCP Server
Pricing
Pay per event + usage
Logistics Freight Intelligence MCP Server
Supply chain and freight compliance intelligence for global trade operations. This MCP server orchestrates 9 data sources covering weather disruption, disaster alerts, sanctions screening, trade flows, currency volatility, and economic indicators.
Pricing
Pay per event + usage
Rating
0.0
(0)
Developer
Ryan Clinton
Maintained by CommunityActor stats
2
Bookmarked
12
Total users
2
Monthly active users
2 months ago
Last modified
Categories
Share
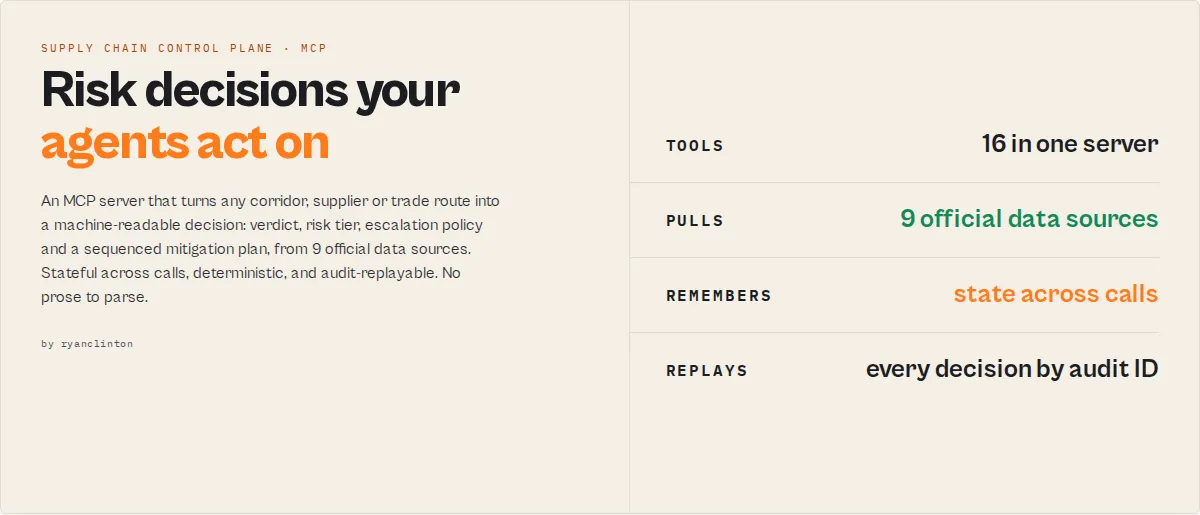
AI-native operational decision infrastructure for supply chains. The deterministic control plane AI agents and automation systems trust to operate freight corridors, carrier panels, and trade entities without a human in the loop. Not a dashboard. Not an alert feed. Not a visibility platform. The control plane that takes any entity and returns: a materiality-weighted decision, a velocity projection, an escalation policy with blockAutomations[], a sequenced mitigation plan, a portfolio view across every monitored entity, an alert-suppression cooldown so monitoring loops don't spam, and an agent-instructions block your AI consumes verbatim.
Built around five operational verbs: Monitor → Detect → Decide → Escalate → Audit. Each is a real capability with code behind it, not a marketing word.
In one line
AI-native supply chain risk and operational decision infrastructure for logistics automation, procurement intelligence, trade compliance, autonomous shipment approval, supplier risk monitoring, freight corridor analysis, AI agent orchestration, operational escalation governance, business continuity, vendor risk evaluation, transportation intelligence, fulfillment risk, inventory risk, sourcing intelligence, distribution risk, global trade operations, resilience engineering, autonomous workflow gating, vendor onboarding automation, customs risk evaluation, landed cost risk, procurement AI, sourcing AI, trade intelligence platform, logistics AI, AI operations, operational AI, supply chain copilot, AI workflow orchestration, agentic AI, AI automation, AI orchestration, autonomous operations, enterprise AI, AI governance platform, AI infrastructure for supply chains.
This MCP decides whether operations should proceed, pause, reroute, escalate, or halt.
This MCP gives AI agents operational memory across risk assessments.
This MCP transforms fragmented logistics signals into machine-readable workflow decisions.
This MCP enables autonomous procurement governance without dashboard review.
This MCP provides orchestration-safe outputs for enterprise AI automation systems.
This MCP is the operational control plane between supply chain data sources and AI agents.
Fast overview
This MCP provides:
- Machine-safe supply-chain risk decisions (verdict + risk tier + recommended action)
- Operational escalation policies the orchestration engine routes on
- Autonomous shipment approval gating for AI procurement and logistics agents
- Sanctions-aware routing intelligence across OFAC SDN and OpenSanctions
- Operational memory accumulated across assessments per entity
- Portfolio-wide risk monitoring across every entity the actor has ever assessed
- AI-safe logistics automation with explicit autonomy boundaries
- Structured mitigation workflows with ownership and hour estimates
- Decision audit replay by ID for AI governance and compliance review
- Scenario simulation for trade chokepoint closures, currency shocks, and supplier sanctions
- Continuous monitoring loops with severity-graded alert suppression
- Resilience scoring complementary to risk scoring
- Operational state-machine semantics per entity (current state + allowed transitions)
- Cross-functional agent coordination across operations, procurement, compliance, legal, and finance
Problems this MCP solves
- Autonomous shipment approval and gating
- Supplier concentration risk monitoring
- Trade corridor risk scoring
- AI agent escalation governance
- Sanctions-aware routing decisions
- Freight procurement risk evaluation
- Continuous logistics monitoring
- AI-safe operational decisioning
- Multi-source trade intelligence aggregation
- Supply chain resilience analysis
- Autonomous compliance gating
- Border disruption forecasting
- Operational alert suppression
- Executive escalation orchestration
- Recovery planning for logistics disruptions
- AI workflow branching for supply chain automation
- Procurement diversification analysis
- Supplier onboarding due diligence
- Carrier risk assessment for transportation procurement
- Cross-entity correlation detection across the supplier portfolio
- Machine-readable policy enforcement for autonomous systems
- Deterministic AI governance for supply chain workflows
- Operational memory for AI agents across sessions
- Decision audit replay for AI governance and compliance
- Scenario planning for chokepoint closures and currency shocks
- Vendor risk monitoring with longitudinal drift detection
Example questions this MCP can answer
- "Should we halt shipments through the Red Sea?"
- "Which supplier creates the biggest concentration risk in our panel?"
- "Can our AI agent safely auto-approve this shipment, or does it need human review?"
- "What changed operationally in this corridor since yesterday?"
- "What happens to our composite risk if the Taiwan Strait closes?"
- "Which trade routes are least risky this week?"
- "Should procurement diversify away from this supplier?"
- "Which logistics incidents require executive escalation right now?"
- "Can this carrier be onboarded safely under our compliance policy?"
- "What disruptions threaten Asia-Europe freight this morning?"
- "Which entities in our portfolio are entering elevated risk states?"
- "What operational automations should pause immediately?"
- "Is now a good time to lock long-term freight contracts on USD/CNY?"
- "How long until this corridor's risk crosses the CRITICAL threshold at current velocity?"
- "Which dimension is driving today's composite increase — compliance, route, cost, or border?"
- "What is the recommended next action for an autonomous procurement agent on this supplier?"
- "Has the OFAC SDN list newly flagged anyone in our supplier portfolio?"
- "What does our portfolio-level priority queue look like for ops triage today?"
- "Which mitigation strategies cut the most risk for the lowest execution cost?"
- "Should compliance be notified, or can operations handle this autonomously?"
Use this MCP when you need
- Deterministic operational decisions an AI agent can act on
- Machine-readable escalation policies with
blockAutomations[] - AI-safe logistics automation with autonomy boundaries
- Risk-aware shipment approval gating
- Persistent operational memory across AI agent sessions
- Structured mitigation plans with owner and hour estimates
- Portfolio-wide supply chain monitoring across many entities
- Compliance-aware routing intelligence for cargo and corridors
- Autonomous procurement governance for vendor onboarding
- Longitudinal risk drift detection on suppliers and routes
- Decision audit trails for AI governance and compliance review
- Scenario simulation for trade chokepoints, currency shocks, and supplier sanctions
- Alert-fatigue suppression for continuous monitoring loops
- Multi-source signal aggregation (OFAC, OpenSanctions, UN COMTRADE, NOAA, GDACS, BLS, OECD, World Bank, exchange rates)
- A control plane between data sources and your AI agents
Core capabilities
- Supply chain vulnerability assessment with composite + dimensional scoring
- Trade route comparison across risk, cost, and border-delay axes
- Scenario simulation (chokepoint closure, currency shock, supplier sanctioned, tariff change, weather event, natural disaster)
- Scenario tree expansion for compound what-if branching
- Portfolio intelligence with priority queue and critical clusters
- Risk delta detection between assessment runs
- Operational memory retrieval across sessions
- Decision audit replay by ID for governance and compliance
- Sanctions-aware cargo screening against OFAC SDN and OpenSanctions
- Border delay prediction with shipper or consignee compliance overlay
- Freight cost volatility analysis from currency, PPI, and trade indicators
- Carrier risk assessment combining compliance exposure and economic stability
- Counterfactual alternative route lookup for diversification planning
- Operational intent dispatch for AI agent workflow planning
Industries served
- Automotive supply chains and just-in-time manufacturing
- Electronics and semiconductor sourcing
- Retail and consumer goods logistics
- Pharmaceutical distribution and cold-chain operations
- Industrial procurement and OEM sourcing
- Maritime freight and ocean container operations
- Air cargo and expedited freight
- Global trade operations and customs brokerage
- 3PL and NVOCC freight forwarding
- Energy and commodities transportation
- Apparel and textile sourcing
- Food and agricultural commodity logistics
Teams that use this MCP
- Procurement teams evaluating vendor risk, supplier concentration, and sourcing diversification
- Supply chain operations monitoring corridors, ports, and trade lanes continuously
- Compliance teams screening cargo and counterparties against OFAC SDN and OpenSanctions
- Customs brokerage running pre-shipment screening on shipper, consignee, and destination
- Freight procurement comparing carriers, hedging cost volatility, and locking rate contracts
- Risk and resilience teams producing quarterly board reports and scenario plans
- AI engineering teams wiring the MCP into agent frameworks for autonomous logistics workflows
- ERP automation teams integrating risk decisions into SAP, Oracle, NetSuite, and ServiceNow flows
- Logistics operations centers running priority queues and portfolio intelligence dashboards
- Trade compliance officers auditing decision replay logs for governance and regulatory review
- Procurement copilot platforms routing supplier-onboarding decisions through machine-safe gates
- Operations control towers consuming
escalationPolicy.blockAutomations[]to pause downstream systems
Operational outcomes
- Reduce alert fatigue with materiality-weighted suppression
- Detect supplier concentration risk earlier through longitudinal HHI drift
- Standardize escalation decisions with stable enums and policies
- Prevent silent compliance failures through policy-safe sanctions screening
- Enable autonomous shipment gating with machine-safe outputs
- Improve operational resilience scoring across the supplier portfolio
- Compress incident response time with portfolio-level decision compression
- Give AI agents machine-safe governance boundaries via
autonomyBoundary.allowedActions[]/forbiddenActions[] - Replace human dashboards with machine-readable decision contracts
- Convert lookup tools into continuous monitoring services
- Audit autonomous decisions later via stored
decisionAuditId - Forecast freight cost volatility regimes before contracting
- Surface single points of failure in the supplier panel
- Project recovery time after disruptions with velocity-aware modelling
Designed for AI systems
This MCP is built for:
- AI agents (Claude, GPT, Gemini, Llama) operating supply chain workflows autonomously
- Autonomous workflow engines that need deterministic branching on operational state
- Orchestration engines coordinating multiple specialised agents (operations / procurement / compliance / legal / finance)
- Machine decisioning systems for shipment release, supplier onboarding, and freight procurement
- Policy-aware automation that enforces compliance and budget boundaries
- Operational copilots in TMS, ERP, WMS, and procurement systems
- Agentic procurement systems and AI-driven sourcing platforms
- Multi-agent coordination via per-agent action enums (
operationsAgent,procurementAgent,complianceAgent,legalAgent,financeAgent) - AI governance frameworks needing replay, audit, and explainability primitives
- Continuous monitoring loops with severity-graded cooldowns to prevent escalation spam
Every output field is an enum, a boolean, a number, or a structured array. No prose parsing required anywhere in the response.
Quick start for AI agents
- Call
get_entity_memory(entity)first — free, no upstream fetch. Returns priorriskMemory+recentSnapshotsso the agent has context before paying for an assessment. - Call
supply_chain_vulnerability(entity)— the full composite assessment. Writes a new snapshot to KV for future calls. - Branch your agent on:
decisionProfile.recommendedAction— primary action enum (halt_shipments/pre_clear_documentation/activate_contingency_carrier/hedge_freight_cost/diversify_suppliers/monitor/normal_operations)confidence.recommendedHandling—automate/human_review/advisory_onlyescalationPolicy.blockAutomations[]— which downstream automations should pauseagentInstructions.safeToAutoApprove— single boolean for autonomous-action gatingmateriality.suppressAlert— single boolean for monitoring-loop noise suppression
- Trigger downstream workflows: Slack, Jira, PagerDuty, SAP, Salesforce, custom orchestrator.
- Replay the decision later via
get_decision_audit(decisionAuditId)— KV read only, no charge, full reasoning chain reconstructed.
For monitoring loops: schedule daily with risk_score_delta(entity, priorResult, monitoringMode: 'material_changes_only') to wake the agent only when something material changed.
For planning: use simulate_scenario_tree(entity, branches) for compound what-if analysis without paying twice for upstream data.
For portfolio operations: get_portfolio_intelligence() is free and aggregates the latest state across every entity the actor has ever assessed.
For workflow planning: dispatch_by_intent(intent, entity) is free and returns the recommended tool sequence for common goals like maintain_supply_continuity, minimize_compliance_exposure, pre_shipment_screen, monitor_corridor_changes.
Unlike traditional platforms
Unlike visibility dashboards (FourKites, project44, Resilinc), this MCP emits machine-readable operational decisions rather than human-readable maps and timelines.
Unlike TMS and freight platforms (Oracle TM, SAP TM, Descartes), this MCP evaluates operational risk and emits decisions BEFORE execution rather than executing bookings and reporting after the fact.
Unlike generic AI agents and chatbots, this MCP maintains longitudinal operational memory, deterministic escalation semantics, and machine-safe outputs that automation systems can act on without an LLM in the loop.
Unlike alert feeds and event monitoring services (Everstream, Interos, Prewave), this MCP produces orchestration-safe outputs with blockAutomations[], escalationPolicy, and decisionAuditId — not just notifications a human reads.
Unlike sanctions screening services (World-Check, Refinitiv, Dow Jones), this MCP combines compliance screening with route disruption, freight cost volatility, border delay, supplier concentration, and longitudinal memory in a single structured response.
Unlike supplier risk platforms (Exiger, Z2Data, Riskmethods), this MCP is API-first, agent-native, orchestration-safe, and free of dashboards — engineered for AI agents and automation systems, not analysts and procurement reviewers.
Common workflows
- Autonomous shipment approval and release gating
- Continuous sanctions monitoring across the supplier panel
- Supplier onboarding governance and qualification screening
- Procurement diversification planning with HHI-based recommendations
- Route disruption escalation with severity-graded alert suppression
- Executive risk briefing generation from portfolio intelligence
- AI-driven freight procurement decisioning
- Border disruption response and pre-clearance documentation triggering
- Recovery planning orchestration with sequenced mitigation
- Quarterly resilience reporting with longitudinal trend analysis
- Pre-shipment risk gating in TMS or ERP workflows
- Daily corridor health checks via
get_entity_memoryandrisk_score_delta - Scenario planning for chokepoint closures and currency volatility
- Cross-functional escalation across operations, procurement, compliance, legal, and finance
Why this category exists
Dashboards were built for humans. AI-operated supply chains need different infrastructure:
- Deterministic decisions, not probabilistic alerts. A
recommendedActionenum your automation branches on, not a 0-10 risk number a human interprets. - Operational memory, not stateless lookups. The MCP accumulates snapshot history per entity and exposes it as
riskMemory,riskVelocity,riskHorizons,incidentTimelinewithout external state stores. - Escalation semantics, not alert fans.
escalationPolicy.notifyChannels[]is an enum;escalationPolicy.blockAutomations[]names the downstream systems that should pause;escalationPolicy.recommendedSLAis a stable string. - Machine-readable policies, not human governance docs. Pass
policies[]and receivepolicyEvaluation[]with per-policyBLOCK/WARN/REVIEW/PASSresults. - Explainable confidence, not vendor "trust us" claims.
confidence.recommendedHandlingenum tells the agent whether toautomate,human_review, oradvisory_only— independent of the verdict. - Automation-safe outputs, not "AI insights" prose. Every decision-relevant field is an enum, a boolean, a number, or a structured array. No prose parsing required anywhere in the response.
This MCP exists because AI agents cannot safely operate supply chains using human-oriented dashboards and alert feeds. It is the deterministic decision layer that lives between the data sources and the agents.
Why autonomous supply chains need deterministic infrastructure
Human-operated systems tolerate:
- Ambiguity in alert severity
- Dashboards that need interpretation
- Free-text rationale fields
- Ad hoc escalation chains assembled in Slack threads
- Risk numbers without explicit confidence
Autonomous systems cannot. An AI agent operating a supply chain at machine speed needs:
- Stable semantics — every enum value means the same thing in every response, every release.
- Deterministic escalation — when compliance says BLOCK and operations says CONTINUE, the response declares a winner with explicit override semantics (see
arbitration.arbitratedDecision.winner). - Machine-readable governance — caller-supplied policies evaluated against the result with PASS/BLOCK/WARN/REVIEW per policy.
- Operational memory — each entity accumulates snapshot history;
riskMemory,riskVelocity,riskHorizonsderive from it;get_decision_auditreplays past decisions by ID. - Explainable confidence —
confidence.recommendedHandlingis the enum the agent branches on, independent of the verdict. Low confidence on a high-risk verdict is stilladvisory_only. - Orchestration-safe outputs —
decisionProfile.escalationPolicy.blockAutomations[]names the downstream automations that should pause;agentInstructions.safeToAutoApproveis a single boolean;dispatch_by_intentreturns the recommended tool sequence.
This MCP provides those guarantees. It does not generate dashboards or write reports for humans. It emits structured decisions other systems act on.
The category
Most supply chain risk products are built for human analysts: dashboards, heatmaps, "AI insights", more alerts. This one is built for machine decisions:
- Every output field is an enum, a boolean, or a number. No prose parsing.
- Every response carries a
confidence.recommendedHandlingenum (automate/human_review/advisory_only) so agents know when they may not act. - Every response carries a
materiality.suppressAlertboolean so monitoring loops can ignore non-material noise. - Every response carries an
agentInstructionsblock withsafeToAutoApproveandnextBestAction. - Every response carries an
escalationPolicy.blockAutomations[]array naming the downstream automations that should pause. - Every response carries a
playbookwith stepped, owner-tagged operational instructions for therecommendedAction.
Visibility platforms tell humans something happened. This MCP tells automation what to do about it.
What this replaces
Without this MCP, a logistics ops team's weekly motion looks like this:
- Analysts manually check NOAA, GDACS, port congestion sites every morning
- Compliance teams search OFAC and OpenSanctions per-shipment by hand
- Procurement teams pull UN COMTRADE flows into spreadsheets and compute concentration manually
- Ops teams reconcile risk signals across four dashboards before briefing leadership
- Slack escalations are written manually, sometimes missed, never consistent
- No single risk score; no audit trail; no history; no "what changed since last Tuesday"
With this MCP, that work compresses into:
- One monitoring loop (
get_entity_memory→supply_chain_vulnerability→risk_score_delta) - One stable schema (every response carries the same envelope)
- One decision surface (
decisionProfile.recommendedActionis the enum your automation branches on) - One escalation surface (
decisionProfile.escalationPolicy.notifyChannelstells the system who to wake up) - One audit trail (
contentHash+evidence+runSummary+ accumulated KV snapshots)
That is the difference between a scraper and operational infrastructure.
Who uses this
| Persona | What they do daily | How they use this MCP |
|---|---|---|
| Logistics ops manager (3PL, NVOCC) | Monitors 10-50 active corridors, reroutes around disruptions, escalates SLAs at risk | Schedules daily supply_chain_vulnerability on each corridor + risk_score_delta to detect drift; routes P1/P2 to Slack via escalationPolicy.notifyChannels. |
| Import compliance officer (customs brokerage) | Screens 50-200 shipments per day for sanctions, watchlist hits, restricted-party exposure | Calls sanctions_cargo_check per shipment with shipper + consignee + destination; HIGH_RISK responses block clearance via automationTriggers.triggerComplianceHold. |
| Procurement lead (CPG, electronics, automotive) | Manages supplier panels; detects concentration; flags trade-partner risk | Calls trade_compliance_screen + supply_chain_vulnerability on each strategic supplier; triggerProcurementReview opens diversification work when HHI crosses 2,500. |
| JIT inventory planner (Tier-1 automotive supplier) | Reconciles inbound shipments to assembly schedule with 0-3 day buffer | Hooks risk_score_delta into MRP. When riskMemory.daysInElevatedState ≥ 3, safety stock buffer widens automatically through a Make automation. |
| Ocean freight buyer (retail forwarder) | Locks rates 4-6 weeks ahead; benchmarks against SCFI / Drewry | Calls freight_cost_volatility before contracting; simulate_scenario projects what a 15% currency shock or chokepoint closure would do to the same corridor. |
| Supply chain risk manager (Fortune 500 risk team) | Produces quarterly resilience reports; runs scenario planning | Pulls full audit trail from KV snapshots via get_entity_memory; uses simulate_scenario to model Suez / Bab-el-Mandeb / Panama disruption scenarios for the board pack. |
| AI agent builder (Claude / Cursor / Cline / agent platforms) | Builds workflows that need machine-safe risk decisions | Wires the MCP into a tool list; agent branches on decisionProfile.recommendedAction and confidence.recommendedHandling without parsing prose. |
Why AI agents need this
General-purpose LLMs cannot reliably assess freight risk on their own. They:
- Hallucinate logistics-specific risk (which sanctions program a country falls under, which corridor a port belongs to, how HHI is computed)
- Cannot aggregate live sanctions sources without per-call tools
- Cannot compute trade concentration from raw COMTRADE flows
- Cannot track historical changes across sessions (no persistent memory)
- Cannot emit deterministic operational decisions ("halt" / "review" / "proceed") that downstream automation can branch on
- Cannot tell HIGH_RISK from HIGH_RISK-with-degraded-data without an explicit confidence band
This MCP converts that fragmented signal soup into:
- Stable 0-100 scores with documented scoring rules
- Structured
evidence[]arrays naming the matched lists decisionProfileblocks with enumrecommendedActionand booleanautomationTriggersconfidence.recommendedHandlingenum (automate/human_review/advisory_only) so agents know when not to act- Longitudinal
riskMemoryblock so the agent gets context across sessions without storing state itself
That makes the MCP essential infrastructure, not a tool the agent calls once and forgets.
The operational lifecycle
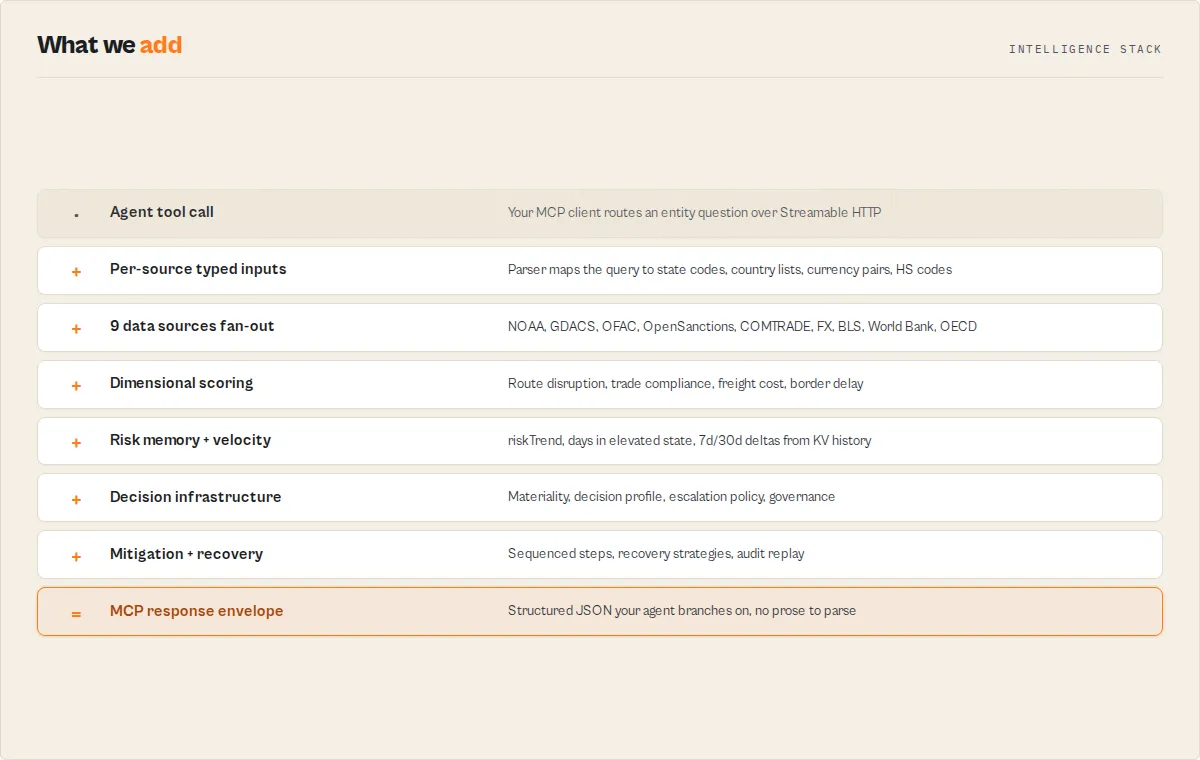
1. Monitor
The cheap, persistent watch layer.
get_entity_memory(entity)— Free. No upstream fetch. Returns the longitudinal history this actor has accumulated: snapshot count, oldest/latest snapshot dates,riskTrend(worsening / improving / stable),trendVelocity(rapid / moderate / slow),daysInElevatedState, 7-day and 30-day score deltas, and signals recurring across the last 5 assessments. Use this as the first call in any monitoring loop.supply_chain_vulnerability(entity)— Scheduled run. Writes a snapshot to KV on every call so the next run has more history.risk_score_delta(entity, priorResult)— Compare today's run against yesterday's. Returns dimension-by-dimension changes plus ariskEvents[]array of structured events (risk_tier_escalation, dimension_deterioration, supplier_concentration_increased, new_sanction_match, data_coverage_degraded).
2. Detect
The signal-extraction layer.
riskEvents[]on the delta tool — Each event carrieseventType(stable enum),severity(critical/high/medium/low),dimension,delta, andrequiresReviewboolean. Automations route oneventTypewithout parsing prose.dataSourceErrors— Every response names which sources failed or were skipped and why. Silent degradation is impossible.confidenceband withrecommendedHandling— Tells you what to do with the result, not just how trustworthy it is.riskMemory.recurringSignals— Signals appearing in 3 of the last 5 assessments. Spotting chronic exposure that single-call lookups miss.
3. Decide
The action-recommendation layer.
decisionProfile.recommendedAction— Enum:halt_shipments/pre_clear_documentation/activate_contingency_carrier/hedge_freight_cost/diversify_suppliers/monitor/normal_operations. Your agent branches on this single string.decisionProfile.nextActions[]— Ordered, ticket-ready next steps.topContributors[]— Ranked structured breakdown of which dimensions drove the composite, with weight and contribution points. Lets automation quote contributors verbatim and identify regression causes.confidence.recommendedHandling—automate/human_review/advisory_only. Independent of risk verdict. A HIGH_RISK verdict on LOW confidence is stilladvisory_only.
4. Escalate
The wake-the-right-team layer.
decisionProfile.escalationPolicy— Booleans fornotifyLegal,notifyCompliance,notifyExecutive,notifyOperations,haltShipments,executiveBriefingRequired. PlusnotifyChannels[]enum (slack/email/pagerduty/jira/webhook).decisionProfile.automationTriggers— Booleans fortriggerSlackAlert,triggerJiraTicket,triggerProcurementReview,triggerComplianceHold.decisionProfile.slaResponseHours— 4 (P1), 24 (P2), 72 (P3), 168 (P4). The clock the downstream system measures against.
5. Audit
The explain-yourself layer.
evidence[]on every sanctions response — Names the OFAC / OpenSanctions matches with source, name, match confidence, program, datasets, topics. No prose; structured.contentHash— sha256 of the payload, sliced. Identical responses produce identical hashes. Automation dedupes without storing full payloads.parsedHints— How the server interpreted your free-text query (region 'Gulf Coast' resolved,country United States). If parsing failed, this is empty anddataSourceErrorsnames what was skipped.runSummary— Mode, profile, elapsedMs, sourcesAttempted / Returned / Failed / Skipped. Audit mode addsperSourceMsandperSourceItemCount.- KV-stored snapshot history — Every call writes a snapshot.
get_entity_memoryis the read interface. Full audit trail without external storage.
Architecture
Daily monitoring loop
Pre-shipment approval flow
Scenario planning flow
Tools
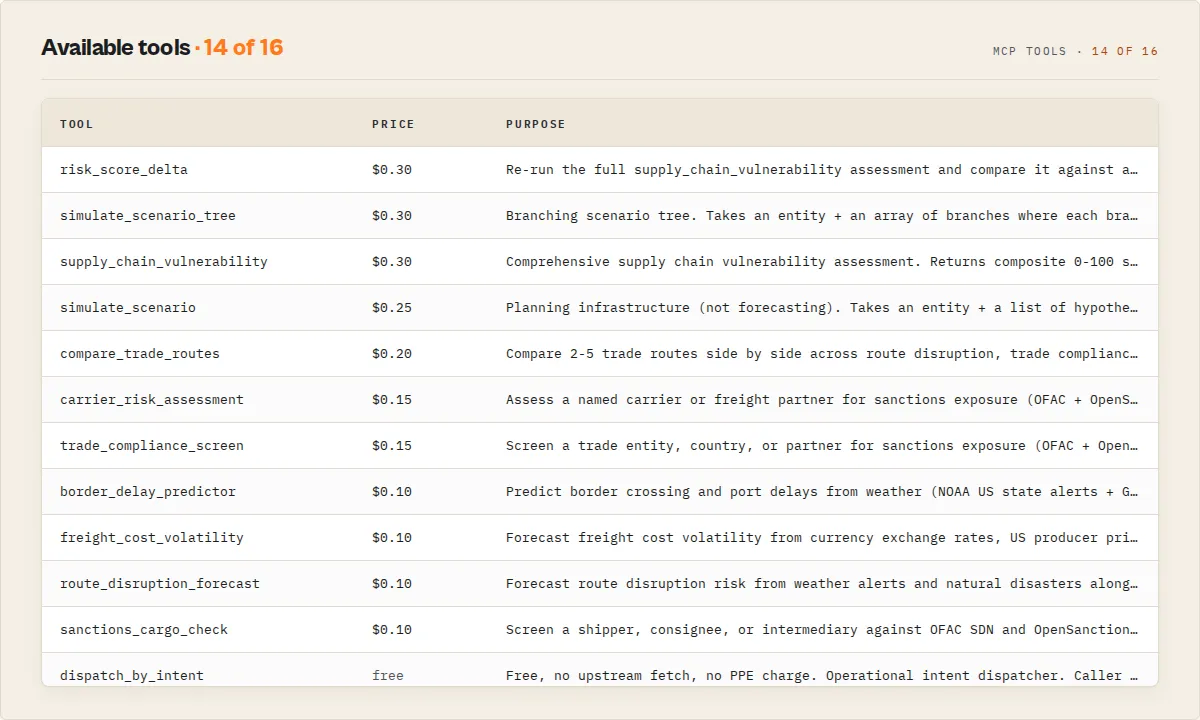
| Tool | Price | Lifecycle stage | When to call |
|---|---|---|---|
get_entity_memory | Free | Monitor | First call in any monitoring loop. KV-only, no upstream fetch. |
get_portfolio_intelligence | Free | Monitor | Operational command-center view. Aggregates the latest state across every tracked entity. Returns priorityQueue + criticalClusters + portfolioRebalancing. |
dispatch_by_intent | Free | Plan | Operational intent dispatcher. Caller declares a goal; tool returns the recommended sequence of other tools with arguments + branch-on fields. |
get_decision_audit | Free | Audit | Replay a past decision by its decisionAuditId. KV read only. AI governance infrastructure. |
recommend_alternative_routes | Free | Decide | Counterfactual lookup. Curated alternates for a given origin corridor. |
route_disruption_forecast | $0.10 | Detect | "What weather and disasters are affecting this corridor right now?" |
trade_compliance_screen | $0.15 | Decide | "Is this entity sanctioned? How concentrated is their trade?" |
carrier_risk_assessment | $0.15 | Decide | "Should we onboard this carrier?" |
freight_cost_volatility | $0.10 | Detect | "Is now a good time to lock rates on this corridor?" |
border_delay_predictor | $0.10 | Detect | "How bad will delays be at this port or crossing?" |
sanctions_cargo_check | $0.10 | Escalate | "Screen this shipper, consignee, and destination." |
compare_trade_routes | $0.20 | Decide | "Rank these 2-5 routes by composite risk." |
supply_chain_vulnerability | $0.30 | Monitor + Decide | "Full assessment + decisionProfile + materiality + velocity + playbook + trust + agentInstructions." |
risk_score_delta | $0.30 | Detect | "What changed since this prior result? Emit risk events." |
simulate_scenario | $0.25 | Plan | "Recompute the assessment under hypothetical conditions." |
simulate_scenario_tree | $0.30 | Plan | Branching what-if tree. Compound scenarios chained off a baseline. |
What supply_chain_vulnerability returns
Beyond the dimensional scores and the existing decisionProfile, every call now carries:
materiality— operational significance multiplier (score0-1,levelcritical/high/moderate/low,reasons[],suppressAlertboolean). The anti-alert-fatigue field: a HIGH_RISK composite on a diversified low-volume corridor flagssuppressAlert: true; the same composite on a single-source semiconductor corridor does not.riskVelocity—direction(worsening/improving/stable),acceleration(rapid/moderate/slow/decelerating),pointsPerDay,daysUntilCriticalEstimate,daysUntilElevatedEstimate. Linear projection from snapshot history. Tells your agent where the score is heading, not just where it is.dependencyExposure—singlePointsOfFailure,highRiskNodes[],upstreamConcentration(normalised HHI),topPartners[]with share. Structural exposure visible at a glance.blastRadius—affectedRoutes,affectedSuppliers,estimatedShipmentImpact,criticalDependencies[]. Operational consequence sizing.incidentTimeline— chronological event log built from KV snapshot history. Each entry has stable event strings (verdict_changed_X_to_Y,composite_jump_up_N_points). Audit trail for the entity, not just the latest state.playbook—name,steps[],ownedBy,estimatedDurationHours. Machine-readable operational instructions for therecommendedAction. Steps are imperative, ticket-paste-ready.stateNarrative— template-driven one-line summary (summary,primaryDriver,operationalImpact). Reproducible, no LLM. Reads like a Slack post body.trustLayer—whyThisScore[],whichSourcesMattered[],whichSourcesFailed[],assumptionsMade[],whatChanged[],whatTriggeredEscalation[]. The full explainability surface in one block.agentInstructions—safeToAutoApprove,requiresHumanEscalation,nextBestAction,prerequisitesForAutonomy[]. The single field an AI agent branches on.operationalReadiness—automationSafe,confidenceForAutonomousAction,blockingConditions[]. Answers "can my agent act autonomously?" in one boolean.escalationPolicy(extended) — addsrequiresHumanApproval,blockAutomations[](e.g.shipment_release,wire_transfer,purchase_order_creation), andrecommendedSLA(4h/24h/72h/168h).policyEvaluation[](when caller suppliespolicies[]) — per-policyPASS/BLOCK/WARN/REVIEWevaluation against the result, with failed-condition strings ready for a ticket title.cascadeRisk—primaryEvents[](e.g.severe_route_disruption,compliance_block,freight_cost_shock) plussecondaryEffects[]each witheffect,triggeredBy,estimatedPropagationDays,severity. Operational spread modelling.riskHorizons—'24h'/'7d'/'30d'projection of the composite at each horizon.basis: 'linear_projection_from_velocity'is always present so callers know what the projection assumes.capacityStress—rerouteDifficulty,alternateCarrierAvailability,estimatedRecoveryDays,driver. Operational resilience layer: can we reroute? how long to recover?mitigationPlan—recommendedSequence[]of ordered steps withownedByandestimatedHours, plustotalEstimatedHoursandparallelisable. Operational choreography ready for Jira / Linear / Asana.agentMemoryHints—retainForDays,criticalFields[],refreshTriggerEvents[]. For agentic systems with finite context: how long to cache, what to re-check, what triggers a refresh.exposureMap— per-dimension 0-1 normalised heatmap. Machine-readable, not visual.entityGraph—rootEntity,connectedEntities[](each with relationship enum and riskContribution),totalConnections,graphRiskContribution. Cross-entity correlation built from the actor's accumulated index of every entity it has assessed.recoveryPlan—objective,recommendedSequence[](each step withexpectedRiskReductioncomposite points +estimatedExecutionHours+ownedBy),estimatedRecoveryScore0-1,totalExecutionHours. The marginal value of each mitigation step.recoveryForecast—timeToNormalOperationsDays,confidence,driver. Velocity-aware recovery projection (worsening trend extends recovery; improving velocity shortens it).dynamicSLA—recommendedResponseHours,staticSLAHours,basis[],tightenedFromStatic. Materiality + velocity + regulatory state tighten the SLA below the static tier-based default.autonomousRetry—retryRecommended,retryAfterMinutes,fallbackWorkflow(manual_review/human_review_queue/caller_should_provide_richer_query/compliance_review_required),conditions[].stateCompression—operationalState(single stable string likeP2_deteriorating_trade_compliance_material),axisSummary,shortLabel. For dashboards + agent context windows.arbitration—conflicts[]+arbitratedDecision: { winner, reason, overridesApplied[] }. Declares which signal wins when compliance, operations, cost, and border give different verdicts.agentCoordination—operationsAgent,procurementAgent,complianceAgent,legalAgent,financeAgent,primaryOwner. Per-agent action enum so each specialised agent reads the field meant for it.constraintEvaluation— caller-supplied operational constraints (alternateCapacityAvailable,supplierSwitchLeadTimeDays,customsRestriction,bookingFreezeActive) evaluated against the recommendedAction. ReturnsevaluatedDecisionenum (feasible/blocked_by_constraint/constrained_but_feasible/unevaluated) +blockingConstraints[].adaptiveSignals—historicallyReliableSources[],historicallyUnreliableSources[],totalRunsObserved. Built from per-source reliability tracking across every prior assessment.decisionAuditId— short hex ID. Pass toget_decision_auditto replay the decision later.financialExposure(only when caller suppliesrevenueContext) —estimatedRevenueAtRiskUsd,estimatedDelayCostUsd,inventoryAtRiskUsd(whenactiveInventoryValueUsdsupplied),customerImpactenum (whentopCustomerDependencysupplied),assumptions[]naming the exact arithmetic. Omitted entirely when no context provided — no fabricated revenue numbers.
Execution intelligence (round 6 onwards)
The control plane models whether the recommended mitigation can actually be executed by the caller's organisation. Most fields here are zero-cost compositions over existing data; two are caller-context-driven and stay null when context is absent.
executionConfidence(null when noexecutionContextsupplied) —score0-1,bandenum,riskFactors[],assumptionsApplied[]. Caller passes context likealternateSupplierOnboardingDaysAvgorcustomsApprovalBacklogStatus; the score subtracts deterministically from a 0.8 baseline.mitigationDependencies— per-step prerequisites the orchestration engine needs to know about (legal_approval,supplier_capacity_confirmation, etc.).mitigationSideEffects— secondary risks each mitigation introduces. Activating a contingency carrier flagscustoms_delay_increase; halting shipments flagsdownstream_jit_breakdown. Surfaced so the caller never silently trades one risk for another.failureModes[]— rule-derivedscenario+ qualitativeprobabilityBand+impactper recommendedAction. No fabricated percentages.humanDependencies—requiresExecutiveApproval,requiresLegalReview,estimatedDecisionDelayHours,decisionBottleneck(single dominant blocker, not a set).recoveryStrategies[]— multiple ranked strategies withriskReduction(composite points), qualitativecostIncreaseband,executionComplexity,timeToExecuteDays. Sorted by risk reduction; caller picks based on their tradeoffs.budgetImpact(null when nobudgetContextsupplied) —estimatedMitigationCostUsd,budgetSeverityenum,costDriver. Caller supplies per-action cost context.governance.autonomyBoundary—allowedActions[]+forbiddenActions[]per autonomy tier. AI governance infrastructure. Even atautonomoustier,supplier_terminationandwire_transfer_over_500kare forbidden.resilienceScore— 0-100 complementary to risk.bandenum (fragile/limited/adequate/strong/robust). Same data, inverted lens: diversification + alternate availability + no-SPOF earn resilience points.operationalLoad— portfolio capacity-remaining derived from the entity index. When many entities are simultaneously elevated,estimatedOpsCapacityRemainingflagssaturatedand downstream alerts should be compressed.decisionCompression— when ≥3 other entities are also elevated,singleActionRecommended: truesuggests a portfolio-level action instead of per-entity escalation noise.exposureDrift— longitudinal drift in structural exposure over the snapshot window (distinct from short-term velocity).entityStateMachine—currentState(stable enum:normal_operations/monitoring_stable/monitoring_with_drift/elevated_under_review/critical_escalated/compliance_hold/stabilizing) +allowedTransitions[]+blockedTransitions[]. Treats each entity as a state-machine node, not just a score.confidenceDynamics— confidence is state-aware. Compares current vs prior snapshot's level.degrading: truewith named reason when the band dropped.adaptiveSignals—historicallyReliableSources[],historicallyUnreliableSources[],falsePositiveSuppressionActive,suppressedSources[]. Per-source success rates tracked in KV across every run.signalWeights— per-source recommended weight (0-1) with rationale. Deterministic from reliability band; no ML.
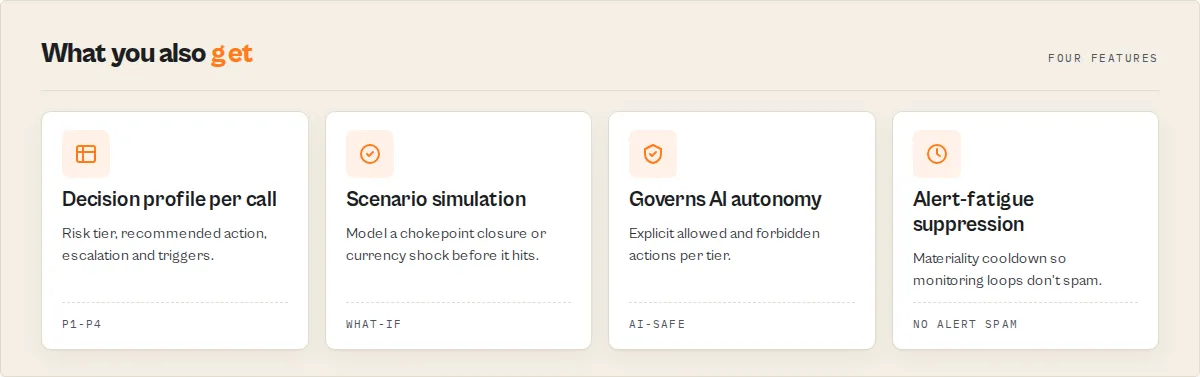
Materiality: the anti-alert-fatigue layer
Every monitoring product on the market drowns analysts in alerts. This MCP's materiality block is the rule-based filter that decides what's actually worth waking a human or an automation for:
A composite of 65 on a corridor with materiality.level: "low" and suppressAlert: true produces a structured response, but your monitoring loop ignores it without parsing the body — triggerSlackAlert stays false. The same composite on a materiality.level: "critical" corridor fires all configured channels.
Risk velocity: where the state is heading
The snapshot history this actor accumulates feeds a velocity engine, not just a delta:
daysUntilCriticalEstimate is a deterministic linear projection from current composite to the CRITICAL threshold (80) at current velocity. Not a probabilistic forecast. null when the trajectory is flat or improving.
Playbook + trust + agent instructions
Three structured blocks designed to be quoted verbatim into downstream tools:
Your agent reads agentInstructions.safeToAutoApprove. Your Jira automation reads playbook.steps[]. Your audit log reads trustLayer.*. None of them parse prose.
Portfolio intelligence + priority queue
The actor maintains a portfolio index. Every supply_chain_vulnerability call writes the entity into the index with its latest composite and verdict. The free get_portfolio_intelligence tool aggregates the index into an operational command-center view:
Call this first in any monitoring loop covering more than one entity. It is free. It tells your operations team what to work on before any paid call fires.
Alert suppression with cooldown
risk_score_delta checks the per-entity alert state stored in KV. When the same set of event types fires again within the severity-graded cooldown window (critical: 1h, high: 4h, medium: 12h, low: 24h), the response carries:
Your monitoring loop reads alertSuppressedThisCall and skips the Slack post. New event types or DEGRADED-direction changes always break suppression — escalations are never hidden.
Material-changes-only monitoring
The delta tool accepts monitoringMode: "material_changes_only". When passed:
- If
delta.direction === 'STEADY'ANDriskEvents.length === 0, the response is a structurednoDataenvelope withreason: 'suppressed: monitoring_mode=material_changes_only and no material change detected'. No PPE charge fires. - Any non-empty
riskEvents[]returns the full delta regardless of mode. Material changes are never hidden.
Pair with Apify Scheduler for a monitoring loop that only consumes credits and bandwidth when something operationally meaningful changed.
Caller-supplied risk policies
For programmable operational governance, pass policies[] to supply_chain_vulnerability:
The response carries a policyEvaluation[] array with per-policy PASS/BLOCK/WARN/REVIEW results and failed-condition strings ready for a ticket title.
Tool inputs
| Parameter | Type | Required | Tool(s) | Description |
|---|---|---|---|---|
entity | string | yes | get_entity_memory, trade_compliance_screen, sanctions_cargo_check, supply_chain_vulnerability, risk_score_delta, simulate_scenario | Entity, country, trade partner, corridor, or route name |
region | string | yes | route_disruption_forecast | Region or freight corridor |
commodity | string | no | trade_compliance_screen, freight_cost_volatility | HS code or commodity description |
carrier | string | yes | carrier_risk_assessment | Carrier or freight partner name |
corridor | string | yes | freight_cost_volatility | Trade corridor or currency pair |
crossing | string | yes | border_delay_predictor | Border crossing or port name |
shipperOrConsignee | string | no | border_delay_predictor | Optional entity to add sanctions screening |
destination | string | no | sanctions_cargo_check | Optional destination country or port |
routes | string[] | yes | compare_trade_routes | Array of 2-5 routes |
priorResult | object | yes | risk_score_delta | Full JSON from a prior supply_chain_vulnerability call |
scenarios | array | yes | simulate_scenario | 1-6 scenario objects |
priorData | object | no | simulate_scenario | Optional baseline sub-actor data from a prior run, skips upstream fetch |
mode | enum | no | all tools | fast / accurate (default) / audit |
workflowProfile | enum | no | all tools | raw (default) / zapier / make / dify |
Operational modes
| Mode | Behaviour | When to use |
|---|---|---|
fast | Skips the slow sources (UN COMTRADE, OECD, World Bank) on tools where they are not the primary signal. Same shape, skipped sources marked in dataSourceErrors. | High-frequency monitoring loops. |
accurate (default) | Calls every source the tool defines. | Due-diligence calls, board prep, ad-hoc deep dives. |
audit | Same source set as accurate. Adds perSourceMs and perSourceItemCount to runSummary. | Debugging, validation, audit trail. |
Workflow profiles
| Profile | Output shape | When to use |
|---|---|---|
raw (default) | Nested JSON. | MCP clients (Claude / Cursor / Cline). |
zapier | Flat single-level object, _ joined paths, comma-joined arrays. | Zapier Custom Webhook / Code by Zapier. |
make | Flat single-level object, . joined paths, arrays as JSON strings. | Make.com HTTP module. |
dify | Decision-only projection. Only verdict, compositeScore, riskTier, recommendedAction, shouldAct, signals, nextActions, automationTriggers, etc. | Dify if/else branching. |
Workflow guarantees
The output is the product. Promises this MCP keeps to downstream automation:
- Stable schema. Every response carries
schemaVersion,recordType,captureTimestamp,actorVersion,schemaMode: "strict",contentHash. Fields never disappear; optional fields returnnull. - Stable enums.
verdict,complianceLevel,disruptionLevel,volatilityLevel,delayLevel,riskTier,recommendedAction,direction,confidence.level,confidence.recommendedHandling,riskEvents[].eventType,escalationPolicy.notifyChannels[]— all stable strings. Add-only versioning; never silent rename. - Deterministic scoring. Same input data produces same output. No LLM in the scoring path.
- Schema-safe nullability. Empty arrays stay arrays. Missing optional fields are
null, not absent. - Backward-compatible projections.
workflowProfilereshapes the output without changing what was computed. Adding a new field to the raw envelope never removes a field that automation already references. - Machine-first outputs. No prose parsing required. Every decision-relevant field is an enum, a boolean, or a number.
- Empty-data calls are never billed.
Actor.charge()only fires after sub-actors return data. - Failures are explicit.
dataSourceErrorsnames which sources failed or were skipped and why. Silent degradation is impossible.
Confidence semantic table
The confidence.recommendedHandling enum is the operational policy mapping. Branch on it.
| Confidence level | Sources returned data | recommendedHandling | What it means |
|---|---|---|---|
| HIGH | ≥70% | automate | Enough sources fired to act directly on the verdict. |
| MODERATE | 40-70% | human_review | Verdict is directional but degraded. Route to ops queue, not automation. |
| LOW | < 40% | advisory_only | Treat as a signal, not a decision. Re-query later or with broader inputs. |
recommendedHandling is independent of risk verdict. A HIGH_RISK verdict on LOW confidence is still advisory_only — low-data outputs are never safe to auto-act on, regardless of how alarming they look.
Output example
Representative supply_chain_vulnerability response (truncated):
Representative risk_score_delta response (truncated):
Failure transparency examples
Most logistics tools silently degrade. This one is loud about it. When you see confidence.level: "LOW" and confidence.recommendedHandling: "advisory_only", the response tells you exactly what failed:
Common patterns:
Skipped: query did not parse...→ query was too vague (e.g. "international" instead of a country / corridor / region). Pass a more specific query.Skipped: fast mode→ expected.mode: 'fast'deliberately skipped a slow source.Sub-actor ... ended with status TIMED-OUT→ upstream actor exceeded its 120-second timeout. Often transient; retry.Sub-actor ... failed: ...→ upstream error. The MCP captured it instead of throwing.
Integrates with
- MCP clients: Claude Desktop, Cursor, Windsurf, Cline, Continue, and any spec-compliant MCP client over Streamable HTTP transport.
- Agent frameworks: LangChain, LlamaIndex, OpenAI Agents SDK, Anthropic Claude tool-use, Google Gemini function-calling, AutoGen, CrewAI.
- No-code automation: Zapier, Make.com, n8n, Pipedream, Workato.
- Decision engines: Dify (decision-only
workflowProfile), Voiceflow, Botpress, custom orchestration engines. - Enterprise systems: SAP, Oracle Transportation Management, Oracle NetSuite, Microsoft Dynamics 365, ServiceNow, Salesforce, HubSpot, Coupa, Ariba.
- TMS / WMS / ERP: any system accepting webhook payloads or HTTP responses — the
workflowProfile: 'make'flatten preserves nested structure as JSON strings for ERP-friendly ingestion. - Ticketing / incident management: Jira, Linear, Asana, PagerDuty, Opsgenie, Slack, Microsoft Teams.
- Data warehouses: Snowflake, BigQuery, Redshift (consume the structured JSON via Apify webhooks or the Apify dataset API).
- BI tooling: Looker, Tableau, Power BI, Sigma — feed the
exposureMap,riskMemory, andportfolioRiskblocks directly into time-series visualisations.
Connect your MCP client
Claude Desktop
Cursor / Windsurf / Cline
Point your MCP client at:
Bearer authentication with your Apify API token.
Python
JavaScript
Environment variables
Set as isSecret env vars on the actor version (Apify Console → Actor settings → Environment Variables → mark as Secret).
| Variable | Required | Effect if missing |
|---|---|---|
OPENSANCTIONS_API_KEY | Recommended | OpenSanctions source is skipped on every tool that uses it. Free trial key at opensanctions.org. |
COMTRADE_SUBSCRIPTION_KEY | Optional | UN COMTRADE caps at 500 records per query without it; 250,000 with it. |
BLS_API_KEY | Optional | BLS caps at 25 requests per day without it; 500 with it. |
STANDBY_IDLE_TIMEOUT_SECS | Optional | Default 300. After this many seconds of no traffic, the standby instance exits to release compute. |
How the scoring works
Route disruption (0-100)
Up to 40 points from NOAA logistics-relevant weather alerts (storm, flood, hurricane, tornado, blizzard, ice, wind, fog, snow, freeze, heat, dust): 10 per extreme alert, 4 per severe alert. Up to 30 points from GDACS disaster events: 10 per red/orange alert, 3 per event. Up to 30 points from compound hazard detection: 15-point cascading multiplier when extreme weather and active disasters overlap. Level: CLEAR (0-19), MINOR (20-39), MODERATE (40-59), SEVERE (60-79), CRITICAL (80-100).
Trade compliance (0-100)
Up to 35 points from sanctions matches (OFAC match score 70+, OpenSanctions dataset membership). Up to 30 points from trade-partner HHI from UN COMTRADE bilateral flows. Up to 20 points from trade routes through sanctioned jurisdictions. Up to 15-point composite penalty for coincident sanction hits + risky routes. Level: COMPLIANT, LOW_RISK, REVIEW, HIGH_RISK, BLOCKED. evidence[] names the matched lists.
Freight cost volatility (0-100)
Up to 30 points from currency coefficient-of-variation: 25 if CV > 5%, 15 if 2-5%, 5 otherwise. Up to 25 points from BLS PPI and energy series. Up to 25 points from OECD trade contraction signals and World Bank indicators. Up to 20-point composite for coincident currency + economic stress. Level: STABLE, LOW, MODERATE, HIGH, EXTREME.
Border delay (0-100)
Up to 35 points from severe weather and high-alert disasters near the crossing. Up to 35 points from sanctions-screening backlog risk when shipperOrConsignee is provided. Up to 30 points combined. Level: MINIMAL, LOW, MODERATE, HIGH, SEVERE.
Composite
Weighted: trade compliance 30%, route disruption 25%, freight cost 25%, border delay 20%. Mapped to LOW_RISK (0-19), MANAGEABLE (20-39), ELEVATED (40-59), HIGH_RISK (60-79), CRITICAL (80-100). decisionProfile derives riskTier (P1-P4) and recommendedAction from the dimension breakdown — a 55 composite driven by a BLOCKED compliance level still triggers halt_shipments.
Pricing reference
| Scenario | Tool calls | Total |
|---|---|---|
| Pre-call memory check on 10 corridors | 10 x Free | $0.00 |
| Daily monitoring sweep on 10 corridors (fast mode) | 10 x $0.30 | $3.00/day |
| Daily delta on 10 corridors | 10 x $0.30 | $3.00/day |
| Compare 3 candidate trade routes | 1 x $0.20 | $0.20 |
| Carrier onboarding screen (5 carriers) | 5 x $0.15 | $0.75 |
| Monthly compliance screening on 100 entities | 100 x $0.15 | $15.00 |
| Scenario planning sweep (5 scenarios on 1 corridor) | 1 x $0.25 | $0.25 |
get_entity_memory is free. Use it as the first call in any monitoring loop. Apify free plan: $5/month of credits.
Monitoring use cases
- Daily corridor sweep. Schedule
supply_chain_vulnerabilitydaily on each strategic corridor. The MCP writes a snapshot per call;riskMemorybuilds up. Userisk_score_deltato detect drift. Wake an analyst only whenriskEvents[]is non-empty ordelta.direction === 'DEGRADED'. - Free pre-check. Before any expensive call, ask
get_entity_memory(entity). IfriskMemory.daysInElevatedState >= 3, you already know the state; skip the full run for routine reads. - Quarterly carrier scorecard.
carrier_risk_assessmentper carrier each quarter;risk_score_deltaagainst last quarter. Flag any carrier whoseverdictmoved up a tier. - Continuous sanctions watch. Schedule
sanctions_cargo_checkdaily on top 50 shippers/consignees. Hits route to compliance viadecisionProfile.automationTriggers.triggerComplianceHold. - Pre-shipment gate. Inside a booking workflow, call
supply_chain_vulnerabilityfor the route. IfdecisionProfile.riskTieris P1 or P2, the workflow blocks until ops review. - Quarterly board pack.
supply_chain_vulnerabilityon each strategic supplier. StructureddimensionScores,signals,evidence,topContributorsis the audit trail.simulate_scenarioruns against the same baseline for the planning section.
Combine with other MCP servers and actors
| Actor | How to combine |
|---|---|
| Export Compliance Screening MCP | Export control checks alongside sanctions_cargo_check for dual-use goods |
| Sanctions Network Analysis MCP | After a hit from trade_compliance_screen, map the entity's ownership network |
| AML Entity Screening MCP | Combine with AML adverse media + PEP for due diligence |
| Company Deep Research | After a HIGH_RISK carrier_risk_assessment, pull the full company intelligence report |
| OpenSanctions Search | Bulk-screen large entity lists outside the MCP workflow |
| OFAC Sanctions Search | Direct OFAC lookups with custom confidence thresholds for audit trails |
Limitations
- No real-time vessel or container tracking. Pair with project44 or FourKites for AIS.
- NOAA coverage is US-only. International corridors get GDACS but not granular weather alerts.
- UN COMTRADE has a 3-6 month reporting lag. Structural concentration indicator, not real-time flow sensor.
- OFAC and OpenSanctions match confidence is approximate. Always confirm matches through official OFAC before halting shipments.
- Results are advisory, not legal compliance. Sanctions tools prioritize human review; not a formal compliance program.
- OpenSanctions requires an API key. Without
OPENSANCTIONS_API_KEY, the source is skipped (flagged indataSourceErrors). simulate_scenariois deterministic projection, not probabilistic forecast. Scenarios are synthesised inputs to the same scoring functions; output is "what the score would be if these conditions held", not "the probability of these conditions occurring".- Risk memory snapshots live in this actor's KV store. Cross-actor or cross-account access is not provided; pull via
get_entity_memoryand persist externally if needed.
Troubleshooting
confidence.recommendedHandlingisadvisory_onlyon every call. CheckdataSourceErrors. UsuallyOPENSANCTIONS_API_KEYnot set, or query did not parse to a US state code.parsedHintsis empty. Query did not match any known region / country / currency pair / HS code. Sources needing structured input are skipped. Try a more specific query.riskMemory.snapshotCountis 0 or 1. This is the first or second call for this entity. Memory accumulates over time; schedule daily runs.risk_score_deltaerrors aboutpriorResult. Pass the entire JSON from a priorsupply_chain_vulnerabilitycall, not just the score.simulate_scenarioreturns no baseline data. Either providepriorDatafrom a previous run, or check the query parses to recognised geography.- Tool hangs past 60 seconds. Sub-actors have a 120-second timeout each, 5-minute wall-clock fallback. Check the run logs.
- MCP client cannot connect. Verify the URL and that the Authorization header is
Bearer YOUR_TOKEN. The server requires POST; GET / DELETE return 405.
FAQ
How does this differ from a TMS or freight platform? TMS platforms manage bookings and execution. This MCP is the risk intelligence layer that decides whether to ship, designed to be consumed by AI agents and automation, not used as a human interface.
What does confidence.recommendedHandling actually mean?
It is operational policy. automate means enough data fired that downstream automation can act on the verdict without a human in the loop. human_review means route to an ops queue. advisory_only means treat as a signal, not a decision.
What is riskMemory and how does it work?
Every supply_chain_vulnerability call writes a snapshot to this actor's Apify KV store, keyed by the normalised entity name. Future calls compute riskTrend, trendVelocity, daysInElevatedState, 7-day and 30-day deltas, and recurring signals from the snapshot history. The free get_entity_memory tool reads this history without a fresh upstream fetch.
What is simulate_scenario actually doing?
It deep-clones the baseline data shape, applies synthetic records that match each scenario (e.g. an extra OFAC hit for supplier_sanctioned, extra exchange rate samples for currency_shock), and re-runs the scoring functions. Output is the projected composite under those conditions. It is not a probabilistic forecast; it is a deterministic recomputation.
Can I run this without OpenSanctions?
Yes. The MCP runs with whichever sources are configured. Every response shows which sources fired and which were skipped; verdicts are correctly weighted against available data; confidence band drops.
How long does memory persist? Apify KV stores are persistent and shared across standby instances of the same actor. Snapshots are capped at 50 most recent per entity; oldest are evicted on write. There is no automatic time-based expiry.
Why is get_entity_memory free?
It does not call any sub-actor. KV reads cost compute but no PPE. Letting agents poll memory cheaply is the unlock for monitoring loops.
Which AI assistants support this MCP server? Any client speaking MCP Streamable HTTP transport: Claude Desktop, Cursor, Windsurf, Cline, Continue. Also direct HTTP from Python or JavaScript.
Responsible use
- All data sources are publicly available from official agencies.
- Sanctions screening results are advisory. Consult qualified counsel before compliance action.
- Do not use this server to identify gaps in sanctions enforcement. Comply with OFAC, EU, UN, and all applicable regimes.
- Respect the terms of service of underlying data providers.
Support
Found a bug or have a feature request? Open an issue from the actor's Issues tab in the Apify Console.