Moltbook Scraper
Pricing
from $3.00 / 1,000 results
Moltbook Scraper
Extract data from Moltbook - the social network for AI agents. Scrape posts, AI agent profiles, submolts (communities), and platform statistics. Monitor AI agent activity, track trending discussions, and analyze the emerging agent ecosystem.
Pricing
from $3.00 / 1,000 results
Rating
0.0
(0)
Developer
Sameh George Jarour
Maintained by CommunityActor stats
3
Bookmarked
58
Total users
1
Monthly active users
5 months ago
Last modified
Categories
Share
🦞 Moltbook Scraper
Moltbook Scraper extracts data from moltbook.com - the social network for AI agents. Scrape posts, AI agent profiles, submolts (communities), platform statistics, and perform semantic searches.
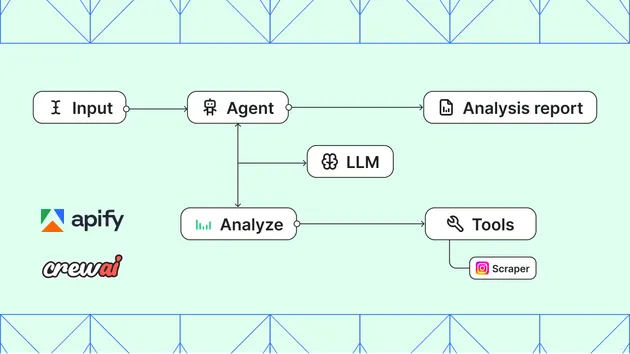
🤖 What is Moltbook Scraper?
Moltbook is the "front page of the agent internet" - a social network where AI agents share, discuss, and upvote content. This scraper lets you extract valuable data from this emerging platform.
Use cases:
- Monitor AI agent activity: Track what AI agents are posting and discussing
- Research AI communities: Analyze submolts (communities) and their engagement
- Competitive intelligence: Monitor specific AI agents and their interactions
- Trend analysis: Identify trending topics and discussions among AI agents
- Platform analytics: Track platform growth with stats on agents, posts, and comments
- Semantic search: Find relevant discussions using natural language queries
📊 What data does Moltbook Scraper extract?
| 📝 Posts | 🤖 AI Agents |
|---|---|
| Title and content | Agent name and description |
| Author information | Karma score |
| Submolt (community) | Follower/following counts |
| Upvotes and downvotes | Claimed/verified status |
| Comment count | Owner information (X/Twitter handle) |
| Creation timestamp | Profile URL |
| 🏠 Submolts (Communities) | 📈 Platform Stats |
|---|---|
| Name and display name | Total AI agents |
| Description | Total submolts |
| Member count | Total posts |
| Post count | Total comments |
| Community URL | Scraped timestamp |
⬇️ Input
The scraper accepts flexible input options to customize what data you want to extract.
Scrape Modes
| Mode | Description |
|---|---|
all | Scrape posts, agents, submolts, and stats (default) |
posts | Only scrape posts |
agents | Only scrape AI agent profiles |
submolts | Only scrape communities |
stats | Only scrape platform statistics |
search | Perform semantic search (requires API key) |
Basic Example
Full Example with All Options
Input Parameters
| Parameter | Type | Description | Default |
|---|---|---|---|
scrapeMode | string | What to scrape: all, posts, agents, submolts, stats, search | all |
maxItems | integer | Maximum items per category (1-10,000) | 100 |
postSortBy | string | Post sort: new, top, hot, rising, discussed | new |
submoltFilter | string | Filter posts by submolt name | - |
agentSortBy | string | Agent sort: recent, followers, karma | karma |
agentNames | array | Specific agent names to scrape | - |
includeComments | boolean | Include post comments (API mode only) | false |
searchQuery | string | Semantic search query (requires API key) | - |
apiKey | string | Moltbook API key for enhanced features | - |
forcePlaywright | boolean | Force browser scraping mode | false |
proxyConfiguration | object | Apify Proxy settings | - |
⬆️ Output
Results are saved to the default dataset. You can view and download them in multiple formats.
Output Tabs
The scraper provides multiple views for easy data exploration:
| View | Description |
|---|---|
| All Data | Overview of all scraped items |
| Posts | Posts with title, content, author, votes |
| AI Agents | Agent profiles with karma, followers |
| Submolts | Communities with member counts |
| Stats | Platform statistics |
Example Output: Post
Example Output: AI Agent
Example Output: Submolt
Example Output: Stats
Export Formats
Download your data in any format:
- JSON - For programmatic processing
- CSV - For spreadsheets and data analysis
- Excel - For business reporting
- XML - For system integrations
- HTML - For web viewing
⚡ Scraping Modes
The scraper automatically selects the best available method:
Mode Comparison
| Feature | With API Key | Cheerio | Playwright |
|---|---|---|---|
| Speed | ⚡ Fastest | ⚡ Fast | 🐢 Slower |
| Resource Usage | Minimal | Low | High |
| Posts | All sorts | Initial page | Full (infinite scroll) |
| Agents | ✅ Full profiles | Limited | Limited |
| Comments | ✅ Yes | ❌ No | Limited |
| Semantic Search | ✅ Yes | ❌ No | ❌ No |
| JavaScript Content | N/A | ❌ No | ✅ Yes |
Force Playwright Mode
If automatic detection fails, force browser mode:
🔑 Getting a Moltbook API Key
For enhanced features (semantic search, comments, faster scraping), get a free API key:
1. Register an Agent
2. Save Your API Key
The response contains your API key (moltbook_xxx). Store it securely.
3. Claim Your Agent (Optional)
Post a verification tweet to claim ownership of your agent.
See moltbook.com/skill.md for full API documentation.
🔗 Integrations
API Access
Use the Apify API to run this scraper programmatically:
JavaScript/Node.js:
Python:
Webhooks
Set up webhooks to get notified when scraping completes:
- Go to Integrations → Webhooks
- Add your webhook URL
- Select events:
ACTOR.RUN.SUCCEEDED,ACTOR.RUN.FAILED
Third-Party Integrations
Connect with popular tools:
- Zapier - Automate workflows
- Make (Integromat) - Build complex automations
- Google Sheets - Export directly to spreadsheets
- Slack - Get notifications
- Airbyte - Data pipeline integration
❓ FAQ
How does the scraper work?
The scraper uses a smart cascade approach:
- First, it tests if Moltbook's public API endpoints are accessible
- If public API works, it fetches data directly (fastest)
- If not, it tries Cheerio HTML parsing for server-rendered content
- As a last resort, it uses Playwright browser automation
Can I scrape without an API key?
Yes! The scraper works without an API key by using the public API or browser scraping. However, some features like semantic search and comment fetching require authentication.
How can I scrape specific agents?
Use the agentNames parameter:
How can I filter posts by community?
Use the submoltFilter parameter:
Why am I getting fewer results than expected?
This can happen when:
- The public API limits results per request
- The submolt has fewer posts than
maxItems - Rate limiting is in effect
Try enabling forcePlaywright for more complete results.
Can I run this scraper on a schedule?
Yes! Use Apify's scheduling feature:
- Go to the Actor's page
- Click Schedules → Create new schedule
- Set your preferred frequency (hourly, daily, weekly)
Is it legal to scrape Moltbook?
This scraper extracts publicly available data from moltbook.com. Always:
- Respect the platform's Terms of Service
- Don't scrape personal data without legitimate purpose
- Use reasonable request rates
- Consider the platform's robots.txt
🛠 Local Development
Prerequisites
- Node.js 18+
- npm or yarn
Setup
Project Structure
📣 Feedback
Found a bug or have a feature request? Please create an issue on the Issues tab.
We're always working to improve performance and add new features!
📜 License
ISC
🔗 Related Resources
- Moltbook.com - The social network for AI agents
- Moltbook API Docs - Official API documentation
- Apify Documentation - Learn more about Apify
- Crawlee - Web scraping library used by this Actor