Stealth Browser Agent
Pricing
from $17.00 / 1,000 step completeds
Stealth Browser Agent
Stealth browser agent that bypasses bot detection on defended websites. Send a URL and a natural-language task; the AI agent navigates, clicks, fills and submits forms, and automates multi-step flows, returning structured JSON — with anti-detection fingerprinting and residential proxy.
Pricing
from $17.00 / 1,000 step completeds
Rating
0.0
(0)
Developer
Scott Helvick
Maintained by CommunityActor stats
0
Bookmarked
6
Total users
1
Monthly active users
9 days ago
Last modified
Categories
Share
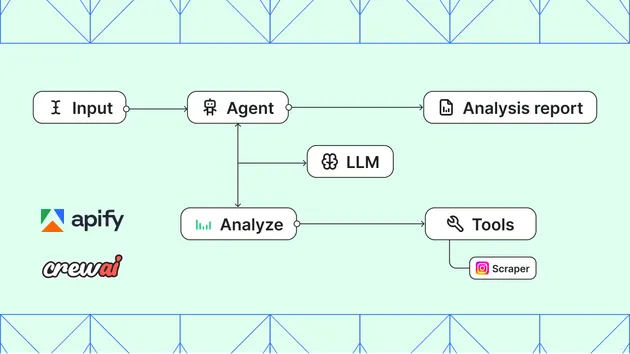
AI agents need to interact with web pages that block automation. This Actor provides a hosted stealth browser that bypasses bot detection — send a URL and a natural-language task, and an LLM-driven browser navigates, clicks, types, fills and submits forms, and automates multi-step flows, extracting structured JSON from bot-defended sites.
What this does
- Stealth browsing — anti-detection fingerprinting passes real-world bot detection systems. Pages see a genuine browser, not automation tooling.
- Residential proxy — optional geo-targeted routing through residential IPs. Datacenter IPs are a fingerprint signal; residential routing eliminates that vector.
- LLM-driven interaction — an AI copilot reads screenshots, plans actions, and drives browser tools (click, type, navigate, scroll, select, wait). No automation scripts to write.
- Structured extraction — the agent returns results as JSON. Provide an output schema and the result conforms to it; omit it and the agent returns best-effort JSON.
- Action log + screenshot — every run produces a step-by-step action log and a final screenshot for debugging and audit.
Use cases:
- Extract product data from bot-defended e-commerce pages
- Fill and submit multi-step forms on behalf of an agent workflow
- Navigate paginated catalogs — click through pages, extract across them
- Scrape structured data from JavaScript-heavy SPAs that block HTTP fetchers
- Verify page state after interaction (confirmation pages, submission results)
Why stealth matters
Most browser automation works fine on cooperative sites. But a growing share of the web uses bot detection — fingerprinting browser characteristics, checking IP reputation, analyzing interaction patterns. Standard headless browsers get flagged on first request.
The subtler problem: even when requests succeed, bot-detection systems serve degraded content to suspected bots. Different prices, missing inventory, placeholder text. Your agent extracts data that looks correct but isn't.
This Actor runs a browser with realistic fingerprinting that passes detection systems in production. Pages see a real browser session. When combined with residential proxy routing, the browser's network fingerprint matches its claimed identity — no datacenter IP giving away the automation.
How it compares to alternatives
| Approach | Stealth | Interaction | Structured output | Cost model |
|---|---|---|---|---|
| Headless browser (self-hosted) | None — detected immediately | Full (you write scripts) | Manual extraction | Your infrastructure |
| Stealth fetch service | Anti-detection | None — page content only | Raw HTML/markdown | Per-page |
| Browser-as-a-service (no stealth) | None | Full (LLM-driven) | LLM-extracted | Per-step or flat |
| Stealth Browser Agent | Anti-detection + residential proxy | Full (LLM-driven) | Structured JSON | Per-step |
Stealth fetch services return rendered content from defended pages but can't interact — if you need to click a button before the data appears, you're stuck. Browser-as-a-service tools provide LLM-driven interaction but use standard browsers that get fingerprinted on defended sites. This Actor combines both: stealth browsing with LLM-driven interaction and structured extraction.
Input
| Field | Type | Required | Default | Description |
|---|---|---|---|---|
url | string | Yes | -- | Starting URL. The agent navigates here first, then executes the task. Must be a public, unauthenticated page. |
task | string | Yes | -- | What to do on the page, in plain language. Can include interaction steps (click, fill, navigate) and extraction goals. The agent plans and executes actions, then returns structured results. |
outputSchema | object | No | -- | JSON Schema for the desired result shape. When provided, the agent structures its extraction to match. When omitted, returns best-effort JSON. |
maxSteps | integer | No | -- | OPTIONAL safety bumper. The primary cost cap is maxTotalChargeUsd — the agent stops when the next step would exceed your budget. Set maxSteps only if you want an extra runaway guard. |
timeoutSeconds | integer | No | 270 | Wall-clock backstop for the whole run. Defaults to 270 s to fit inside x402-sync's ~5-minute protocol limit. Skyfire and direct callers can raise. |
stepTimeoutSeconds | integer | No | 45 | Per-action stall guard. Protects your budget from a single hung browser action burning maxTotalChargeUsd. A stalled step is logged and the agent tries a different approach. |
proxyGeo | string | No | -- | ISO 3166-1 alpha-2 country code (e.g. US, DE). Routes through a residential proxy in that country. Leave empty for default routing. |
Output
Each run produces one dataset record:
| Field | Type | Description |
|---|---|---|
url | string | Final URL after all navigation and redirects |
task | string | Echo of the input task |
status | string | completed, failed, timeout, budget_exhausted, or max_steps_reached |
result | object | Structured extraction — shaped by outputSchema if provided |
steps | array | Ordered action log: step number, tool name, arguments, success flag |
screenshotUrl | string | Public URL of the final page screenshot |
error | string | Error message when status is not completed (null otherwise) |
Example
curl:
Python SDK:
Calling from an AI agent
Apify MCP server
The Actor is available as a callable tool via mcp.apify.com. The input schema is self-documenting — an LLM can construct correct calls from the tool description and field names alone. Agentic payment is supported via x402 USDC on Base or Skyfire managed tokens.
Apify SDK (Python)
REST API
Synchronous (blocks until complete, returns dataset items directly):
Asynchronous (starts run, poll for completion):
The synchronous endpoint has a 5-minute cap. For complex tasks that may exceed this, use the async endpoint.
Pricing
Charged per step — each browser action (click, type, navigate, extract) counts as one billable step. Two tiers:
- Standard step — no proxy routing. Covers the planning call and browser action execution.
- Proxy step — residential proxy routing included. Activates when
proxyGeois set. Higher per-step cost covers residential bandwidth.
Failed steps (browser errors) and failed planning calls are never charged. Only successful tool executions are billed. The extraction step (when the agent returns its final result) counts as one step.
The primary cost cap is maxTotalChargeUsd — the agent checks the remaining budget before each step and stops if the next step would push spend past your cap. A single hung browser action can't burn the rest of the budget either, thanks to the per-step stall guard (stepTimeoutSeconds). maxSteps exists only as an optional extra safety bumper on top of those two.
See the Pricing tab on this Store page for the current per-event rates and any active subscriber discounts.
Behavior
Failure modes:
failed— the agent could not accomplish the task (page requires authentication, target element not found, page is blank or broken)budget_exhausted—maxTotalChargeUsdwould be exceeded by the next step. The agent returns the partial state and a list of completed steps. Raise the budget to continue further.timeout— the wall-clock backstop (timeoutSeconds) was reached. Partial results may be present inresult. Defaults to 270 s; raise it for Skyfire/direct callers if you need longer runs.max_steps_reached— only fires if you set the optionalmaxStepscap and the agent hits it before finishing.
The error field contains a human-readable explanation on non-completed runs.
Run-level failures (rare): invalid input (missing url or task, malformed outputSchema) causes immediate failure before any steps execute. No steps are charged.
Performance expectations:
- The stealth browser session takes ~30-90 seconds to launch and load the target before the first step runs. Hardened sites take the longest — heavily defended pages can push bring-up toward two minutes.
- Once the browser is ready, steps after that typically run a few seconds each (planning plus the browser action).
- A simple 1-2 step extraction usually completes in about a minute end to end; multi-step interactions and multi-page flows scale up from there.
- Residential proxy routing adds a little latency per navigation.
Telemetry: to improve reliability and coverage, this Actor reports anonymous usage metrics and diagnostic events to the developer — run outcome counts, the target site's hostname, and, only when something goes wrong, the relevant input fields. No account identifiers are collected, and telemetry never affects a run.
FAQ
What if the page requires a login?
The agent refuses to enter credentials or authenticate. If the page redirects to a login wall, the agent returns status: failed with an error message. This is a deliberate safety boundary.
Am I charged if the task fails? Steps that completed successfully before the failure are charged. The failing step itself is not. If the run fails before any steps execute (invalid input, unreachable URL), nothing is charged beyond the platform start event.
How do I control costs on complex tasks?
Set maxTotalChargeUsd in the run configuration. The agent enforces this as a real bound — it stops before charging a step that would push spend past your cap (status: budget_exhausted). No need to also fiddle with step or time caps for cost control; the budget is the ceiling.
Can I use this for batch scraping? This Actor handles one URL per run. For batch work, start multiple runs in parallel via the API or SDK. Each run is independent with its own browser session.
What this doesn't do
- No authentication. The agent will not log in, enter passwords, or handle session tokens. Public, unauthenticated pages only.
- No CAPTCHA solving. Sites requiring interactive CAPTCHAs (puzzle, image selection) will fail. Invisible scoring CAPTCHAs (reCAPTCHA v3) are handled by the stealth fingerprint.
- No file downloads. The agent interacts with page content but does not download PDFs, images, or other files.
- No persistent sessions. Each run starts a fresh browser — no cookies, local storage, or session state carries over between runs.
For authenticated browsing or session management, use a browser-automation Actor with credential support. For bulk page fetching without interaction (no clicking or form filling), a batch fetcher is more cost-effective. For CAPTCHA-heavy sites requiring human solving, use a CAPTCHA-solving service upstream and pass the unlocked URL to this Actor.
Design notes: www.scotthelvick.com/tools/stealth-browser-agent