Skool Scraper
Pricing
$13.99/month + usage
Skool Scraper
Scrape Skool communities at scale. Extract posts, comments, courses with modules, events, leaderboards, and community info from any public Skool group. Get structured data including classroom content, member rankings, and calendar events. Perfect for market research and competitor analysis.
Pricing
$13.99/month + usage
Rating
0.0
(0)
Developer
SilentFlow
Maintained by CommunityActor stats
2
Bookmarked
7
Total users
0
Monthly active users
3 months ago
Last modified
Categories
Share
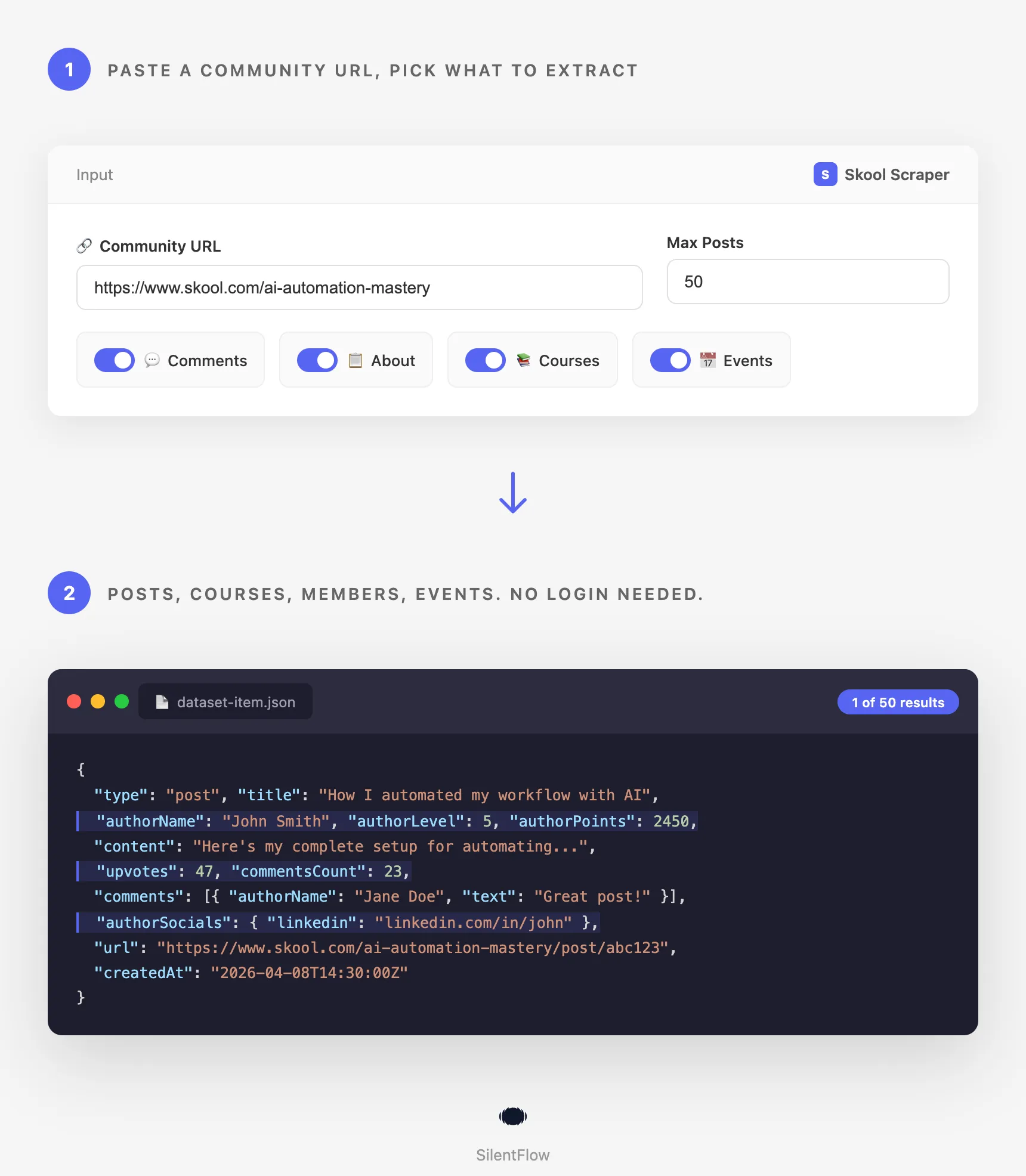
50 posts with comments in under 30 seconds. Extract posts, comments, member profiles, courses, and events from any public Skool community. No login or cookies required.
How it works
✨ Why teams choose this over other Skool scrapers
Copying posts from Skool tabs one by one? Other scrapers asking you to paste your login cookies? Tired of setting up authentication just to get public data?
- 🔓 No login, no cookies, no setup. Other Skool scrapers (memo23, louisdeconinck) require you to log in and paste session cookies. This one works out of the box with zero authentication.
- 📝 5 data types in one run. Posts, comments, about/leaderboard, classroom courses, and calendar events. One scraper replaces five.
- 👥 Full member profiles with social links. Every author gets bio, level, points, and links to Facebook, Instagram, LinkedIn, Twitter, YouTube, and their website.
- 💬 Nested comment threads, not just top-level. All reply levels are extracted with the same rich author data. Competitors often skip nested replies.
- ⚡ 50 posts with full comments in 30 seconds. Fast pagination and parallel comment extraction keep scraping times low even for large communities.
🎯 What you can do with Skool data
| Team | What they build |
|---|---|
| Community analysts | Map engagement patterns and identify top contributors across 50+ Skool communities |
| Lead generation | Build outreach lists from active members with verified social profiles (LinkedIn, Instagram, Twitter) |
| Course creators | Benchmark competitor course structures, module counts, and content gaps |
| Content strategists | Find the highest-upvoted posts and discussion topics to inform your own community content |
| Market researchers | Track community growth, member counts, and activity levels across niches |
| Event planners | Monitor competitor event schedules, formats, and recurring call patterns |
📥 Input parameters
Search
| Parameter | Type | Description |
|---|---|---|
startUrls | array | Skool community URL(s) to scrape. Supports community pages, individual post URLs, about, classroom, and calendar pages. |
What to Extract
| Parameter | Type | Default | Description |
|---|---|---|---|
maxItems | integer | 50 | Maximum number of posts to return per community. |
scrapeComments | boolean | true | Extract all comments and replies for each post. |
scrapeAbout | boolean | true | Extract community info, description, and top members with social links. |
scrapeClassroom | boolean | true | Extract classroom courses with modules and video links. |
scrapeCalendar | boolean | true | Extract calendar events with dates and descriptions. |
Advanced
| Parameter | Type | Default | Description |
|---|---|---|---|
maxPages | integer | 5 | Maximum pages to scrape per community (~30 posts per page). |
requestTimeout | integer | 30 | HTTP request timeout in seconds. |
proxy | object | Residential | Proxy configuration. Residential proxies are recommended. |
📊 Output data
The scraper outputs five data types: posts, comments (nested inside posts), community info, courses, and events.
Post example
Community info example
Course example
Event example
🗂️ Data fields
| Category | Fields |
|---|---|
| Post basics | id, url, title, content, postType, label, pinned, createdAt, updatedAt |
| Post engagement | upvotes, commentsCount |
| Post media | imageUrl, videoIds, videoLinks |
| Author profile | authorName, authorId, authorBio, authorPicture, authorLevel, authorPoints |
| Author socials | facebook, instagram, linkedin, twitter, website, youtube |
| Comments | id, content, authorName, authorBio, authorLevel, authorPoints, authorSocials, upvotes, createdAt, replies (nested) |
| Community info | name, slug, description, landingPageDescription, privacy, totalMembers, totalOnlineMembers, totalPosts, totalAdmins |
| Community owner | ownerName, ownerId, ownerBio, ownerSocials |
| Community extras | coverUrl, logoUrl, faviconUrl, links, leaderboard, createdAt |
| Leaderboard users | userId, name, picture, bio, points, level, socials |
| Courses | id, url, title, description, coverImage, numModules, public, groupSlug |
| Events | id, url, title, description, coverImage, startTime, endTime, timezone, location |
🚀 Examples
Get all posts from a community
Extract courses and modules
Scrape multiple communities
Get community info and leaderboard only
💻 Integrations
Pull Skool posts into a Python pipeline
Feed Skool data into a JavaScript app
📈 Performance
| Metric | Value |
|---|---|
| Speed | 50 posts with comments in ~30 seconds |
| Posts per page | ~30 |
| Comments | All comments and nested replies per post |
| Courses | All public courses in classroom |
| Events | All upcoming calendar events |
| Max posts | Up to 50,000 per run |
| Memory | 256 MB (scales automatically) |
💡 Tips for best results
- Start with 50 posts. Use
maxItems: 50andmaxPages: 5for your first run to preview the data structure before scaling up. - Skip comments for speed. Set
scrapeComments: falseto avoid visiting each post's detail page. This makes large scrapes significantly faster. - Extract only what you need. If you only want courses, disable
scrapeAbout,scrapeComments, andscrapeCalendar. Fewer requests means faster results. - Target specific posts. Pass individual post URLs in
startUrlsto get full content and all comments for those posts only. - Use community URLs for bulk extraction. A single community URL with
maxItems: 5000andmaxPages: 200will paginate through the full post history automatically.
❓ FAQ
Q: Do I need a Skool account or cookies? A: No. This scraper works without any login, cookies, or authentication. It extracts publicly available data from public Skool communities.
Q: Can I scrape private communities? A: No. The scraper only accesses public Skool communities. Private communities are not supported.
Q: How do I get all posts from a large community?
A: Increase maxItems and maxPages to cover the full community. Each page contains approximately 30 posts.
Q: What social links are extracted? A: Facebook, Instagram, LinkedIn, Twitter/X, YouTube, and personal websites. These are extracted for post authors, comment authors, the community owner, and leaderboard members.
Q: Can I get just the about page or classroom without posts?
A: Yes. Set maxItems: 1 and enable only the sections you need (scrapeAbout, scrapeClassroom, scrapeCalendar).
Q: Are nested comment replies included? A: Yes. All reply levels are fully extracted with the same author data (bio, social links, points, level).
📬 Support
Need something this scraper doesn't do yet? We ship features fast.
- Feature requests go straight to our backlog
- Enterprise needs? We do custom integrations
Response time: usually under 24 hours.