Facebook Ads Transcript Scraper — Video Hooks & CTAs
Pricing
from $15.00 / 1,000 video ad transcripts
Facebook Ads Transcript Scraper — Video Hooks & CTAs
Transcribe Facebook & Instagram video ads in bulk: full transcript, first-3s hook, CTA & metadata as one JSON row per ad. Chain after any Ad Library scraper (dataset ID or URLs). Any video length. Charged only when a transcript is delivered — expired links & music-only ads cost $0.
Pricing
from $15.00 / 1,000 video ad transcripts
Rating
0.0
(0)
Developer
Steadyfetch Team
Maintained by CommunityActor stats
0
Bookmarked
14
Total users
7
Monthly active users
5.8 hours
Issues response
13 days ago
Last modified
Categories
Share
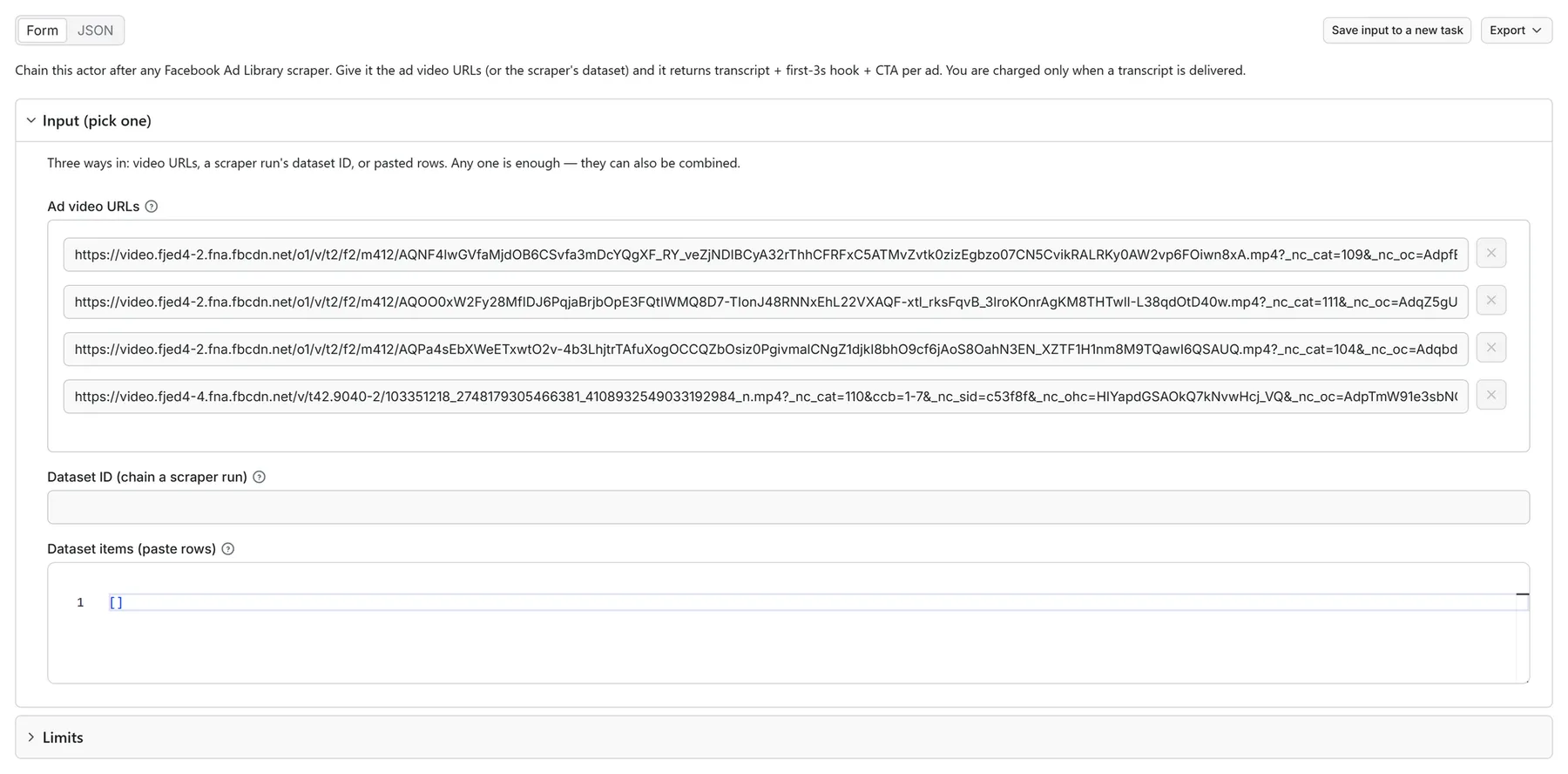
Turn Facebook and Instagram ad videos into structured transcripts — full text, the first-3-seconds hook, CTA, and ad metadata in one JSON row per ad. Chain this Facebook ad transcript extractor straight after any Ad Library scraper run, any video length, in bulk. You are charged only when a transcript is delivered — expired links, music-only creatives, and image ads cost $0.
| You give it | You get back |
|---|---|
Ad video URLs (video_hd_url from any scraper) | transcript — full speech-to-text, any length |
| …or your scraper run's dataset ID (one-click chaining) | hook3s — what's said in the first 3 seconds |
| …or pasted dataset rows (any scraper's shape) | ctaText, pageName, adArchiveId, language, durationSeconds, timestamped segments |
Why this Facebook ads transcript scraper?
- Charged only on delivery. A transcript either lands in your dataset or the row is free. Expired URL → free row that says so. Music-only ad → free row that says so. No "it ran and charged me but returned nothing."
- Any video length. VSL-length creatives (7+ minutes) transcribe fine — long videos add a small per-minute surcharge instead of failing or being silently cut at 2 minutes.
- Bulk, not one-at-a-time. Feed it your whole Ad Library scrape — hundreds of ads in one run, processed concurrently.
- Hook + CTA as data. The first-3s hook is the line media buyers actually study; you get it as its own field, plus full segment timestamps for anything deeper.
- Works with any scraper's output. The input deep-scans your dataset rows for the video URL and ad metadata — no field mapping, no glue code.
How to transcribe Facebook ads (no code)
- Run any Facebook Ad Library scraper (e.g. the ones you already use) with video ads in scope.
- Open this actor, paste your run's dataset ID (or use Apify's Connect Actor integration to chain it automatically).
- Click Start. Each video ad comes back as one JSON row: transcript + hook + CTA + metadata.
- Export as JSON/CSV, or read it via API.
Prefer URLs? Paste video_hd_url / video_sd_url values into videoUrls directly.
Why do Facebook ad video URLs expire?
Facebook's video CDN (video.*.fbcdn.net) signs every URL with an expiry — typically a few hours to a few days (the oe= parameter is a hex timestamp). Transcribe soon after scraping: a dataset from last week will have dead links. Expired rows come back as uncharged unavailable_expired so you can re-scrape and re-run just those. This actor intentionally does not accept Ad Library page links (facebook.com/ads/library/?id=…) — Meta blocks server-side page reads, and we'd rather say that plainly than sell you a half-working re-resolver.
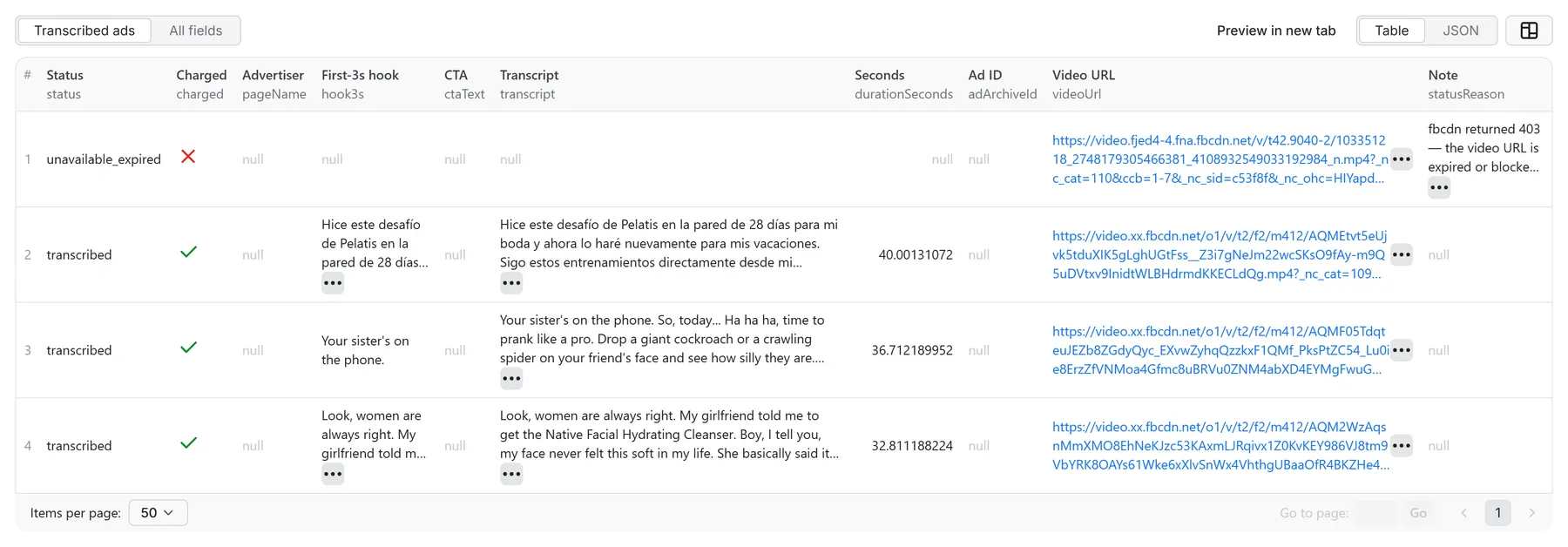
Output example
Every field is always present (explicit null over silent omission). Non-delivered rows carry status + statusReason instead — unavailable_expired, no_audio (music-only creative), image_skipped (image ads ship their metadata free), no_creative_found, or failed_* (also listed in the run's ERRORS record).
See a live sample dataset → — real ads from a real run: three transcripts (one in Spanish) and one expired-URL row delivered honest and uncharged.
How much does it cost to transcribe Facebook ads?
One result = one ad's full transcript payload (transcript + hook + CTA + metadata + segments). The first 3 minutes of each video are included; longer videos add a small per-started-minute surcharge. No start fee, no subscription, no third-party API key to buy.
| Job | Approx. cost |
|---|---|
| 50 competitor video ads | ≈ $1.00 |
| 500 ads (a serious creative teardown) | ≈ $10 |
| Apify free plan ($5 credit) | ≈ 250 ad transcripts |
Platform usage (compute + transfer) is included in the event price (since July 5, 2026) — no separate usage line on your Apify bill, so the per-transcript price you see is the whole price. Failed or empty fetches still charge nothing.
Use it via API, MCP, and integrations
- API: standard Apify run API —
POST .../acts/steadyfetch~facebook-ads-transcript-scraper/runswith{ "datasetId": "..." }. Python/Node clients work as with any actor. - MCP: works from Claude, Cursor, and any MCP client through Apify's MCP server — ask for "facebook ad transcripts" with a dataset ID or URLs.
- n8n: free ready-made template → — scrape ads → transcribe hooks & CTAs → pipe to Sheets, 3-minute setup, no community nodes needed (the workflow people sell as a paid template, free).
- Make / Zapier: call it as a regular Apify actor step right after your scraper node — same two HTTP calls as the n8n template.
- Chain it after any Ads Library scraper on this store — the big ones output
snapshot.videos[].video_hd_url, which is exactly what the deep-scan looks for.
FAQ
Is it legal to transcribe Facebook ads? The Ad Library is public by design (ad transparency), and US courts have held that logged-out scraping of public Meta data does not breach Meta's terms (Meta v. Bright Data, 2024). The ad-spy industry (Foreplay, Atria, AdSpy) operates on this data openly. As always, how you use the data is on you.
What happens on a failed download? Up to 3 attempts, then an uncharged failed_download row plus an entry in the run's ERRORS record. You pay $0 for anything that didn't deliver.
Music-only ads? Speech-recognition models hallucinate filler ("Thank you.") on music. We detect that and return an honest, uncharged no_audio row instead of selling you a fake transcript.
Image ads? v1 transcribes video ads. Image rows pass through free with their CTA/page metadata, clearly marked image_skipped.
Languages? Whisper-class multilingual ASR — Spanish, German, Arabic, and ~90 more transcribe out of the box; the detected language ships on every row.
Why not scrape the Ad Library here too? Single-purpose by design: your scraper (whichever you like) finds the ads; this actor turns them into transcript data, reliably. One job, done honestly.
Feedback & support
Found an issue? Open it on the Issues tab — we respond within one business day. Feature requests welcome: TikTok ad transcripts are next on the roadmap.