Goodreads Books Reviews Scraper
Pricing
from $2.00 / 1,000 results
Goodreads Books Reviews Scraper
Scrape book reviews from Goodreads.com, the world's largest book recommendation platform. Extract review text, ratings, user profiles, timestamps, and engagement metrics. Ideal for publishers, authors, market researchers, and sentiment analysis applications.
Pricing
from $2.00 / 1,000 results
Rating
0.0
(0)
Developer
Stealth mode
Maintained by CommunityActor stats
0
Bookmarked
10
Total users
1
Monthly active users
2 months ago
Last modified
Categories
Share
Goodreads.com Books Reviews Scraper: Extract Reader Feedback & Rating Data
Why Scrape Goodreads Reviews
Goodreads hosts over 150 million reviews from 125 million readers, making it the definitive source for book reception data. Reviews reveal reader sentiment, purchasing triggers, content warnings, demographic preferences, and competitive positioning—intelligence unavailable from sales data alone.
Publishers use review data to refine marketing messages, identify audience segments, and forecast performance. Authors track reader feedback to improve subsequent works. Researchers analyze sentiment trends across genres, demographics, and time periods. Book recommendation engines train algorithms on review patterns.
Manual review collection across hundreds of books is impractical. This scraper automates extraction, delivering structured review datasets for analysis.
What This Scraper Extracts
The Goodreads Books Reviews Scraper processes book review pages, extracting individual reader reviews and their metadata. Each review includes content, ratings, user information, and engagement metrics.
Target Users:
Publishers analyze reception patterns, identify marketing angles, and benchmark against competitors. Authors monitor reader feedback, understand audience expectations, and track review sentiment over time. Market Researchers conduct genre analysis, demographic studies, and sentiment forecasting. Data Scientists build recommendation systems, train NLP models, and perform text analytics. Book Marketing Agencies identify influential reviewers, track campaign impact, and optimize promotional strategies.
Input Configuration
The scraper processes Goodreads book review page URLs—the pages displaying reader reviews for specific books, accessed via the "Reviews" tab on any book page.
Example Input:
Example Screenshot:
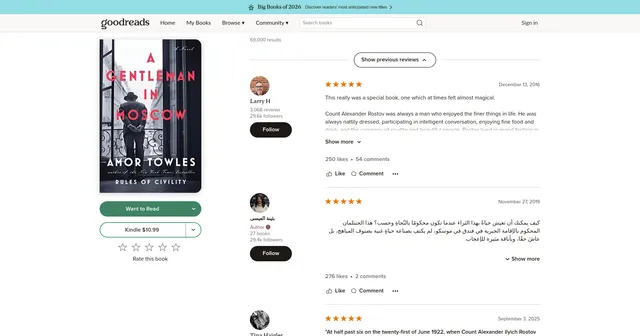
Parameter Details:
proxy: Set useApifyProxy: false for basic scraping. Enable residential proxies if encountering rate limits or blocks. Goodreads generally allows moderate scraping without proxies, but high-volume extraction benefits from proxy rotation.
max_items_per_url: Number of reviews to extract per URL. Default 20 matches typical page display. Increase to 50-100 for comprehensive extraction. Goodreads paginates reviews, so this limits collection per page.
ignore_url_failures: Set true when processing multiple books—individual failures won't halt the run. Essential for batch processing where some URLs may be outdated or restricted.
urls array: Book review page URLs. Format: https://www.goodreads.com/book/show/[BOOK_ID]/reviews. The reviewFilters parameter applies sorting/filtering (newest, highest rated, etc.). Obtain URLs by navigating to any book's review section and copying the URL.
Collecting URLs: Browse Goodreads, find target books, click "Reviews," copy URL. For batch processing, compile book IDs from search results or lists, then construct review URLs programmatically.
Output Structure: Field Definitions
ID: Unique review identifier assigned by Goodreads. Use: Database primary key, tracking specific reviews, avoiding duplicates, linking to user profiles.
Creator: User object containing reviewer information (user ID, name, profile URL). Use: Identifying influential reviewers, analyzing reviewer demographics, tracking power users across multiple reviews.
Recommend For: Target audience or demographic the reviewer suggests the book for (e.g., "fans of fantasy," "young adults"). Use: Audience segmentation, marketing targeting, understanding niche appeal.
Updated At: Timestamp of last review modification. Use: Tracking review edits, identifying recently updated opinions, filtering for fresh content.
Created At: Original review posting timestamp. Use: Timeline analysis, correlating reviews with marketing events or releases, identifying early adopters vs. late readers.
Spoiler Status: Boolean indicating if review contains spoilers. Use: Filtering spoiler-free reviews for promotional materials, analyzing whether spoiler reviews differ in sentiment or detail.
Last Revision At: Most recent edit timestamp. Use: Distinguishing original vs. revised opinions, tracking how reader sentiment evolves post-publication.
Text: Full review content. Use: Sentiment analysis, keyword extraction, identifying common themes/complaints/praise, training NLP models, generating marketing quotes.
Pre-Release Book Source: Indicates if reviewer received advance copy (ARC). Use: Identifying promotional reviews, separating organic vs. publisher-seeded feedback, tracking ARC program effectiveness.
Shelving: Which Goodreads shelves the reviewer added the book to (e.g., "read," "to-read," "favorites," custom shelves). Use: Understanding reader categorization, identifying genre crossover, tracking completion rates.
Like Count: Number of users who found the review helpful. Use: Identifying high-quality or influential reviews, weighting sentiment analysis by review utility, finding quotable reviews for marketing.
Viewer Has Liked: Boolean indicating if the scraping account liked the review. Use: Internal tracking, typically not applicable for most use cases.
Comment Count: Number of discussion comments on the review. Use: Engagement metric, identifying controversial or discussion-generating reviews, measuring review impact.
Sample Output:
Implementation Steps
1. Identify Target Books: Determine which books to analyze. Search Goodreads for titles, genres, or authors. Compile book IDs or review page URLs.
2. Configure Input: Build JSON with review URLs. Set max_items_per_url based on needs—20 for samples, 100+ for comprehensive datasets. Enable ignore_url_failures for batch processing.
3. Test Small Batch: Start with 3-5 books to verify data quality. Check that review text, ratings, and user info populate correctly.
4. Execute Run: Launch scraper. Typical processing: 10 books × 20 reviews = 5-7 minutes. Timing varies with page load speeds and pagination.
5. Export Data: Download JSON for databases, CSV for spreadsheets. Clean data by removing duplicate reviews or filtering by date ranges.
6. Handle Pagination: For books with thousands of reviews, either increase max_items_per_url to 200+ or create multiple URLs with different reviewFilters parameters to capture paginated results.
Error Handling: Failed URLs typically indicate removed books, access restrictions, or malformed URLs. Check activity logs for specifics. Verify URLs load in browser before troubleshooting.
Strategic Applications
Sentiment Analysis: Process review text with NLP to quantify positive/negative sentiment, track sentiment trends over time, identify sentiment drivers (plot, characters, writing style).
Competitive Intelligence: Compare review volumes, average ratings, and sentiment across competing titles. Identify competitor strengths/weaknesses mentioned in reviews.
Marketing Message Development: Extract frequent praise points ("addictive," "couldn't put down," "emotional") to inform ad copy and promotional materials. Identify reader concerns to address in marketing.
Audience Segmentation: Analyze "recommend for" fields and shelving patterns to understand who reads the book and how they categorize it. Informs targeting strategies.
Influencer Identification: Track reviewers with high like counts and comment engagement. Build relationships with influential readers for future launches.
Content Warning Identification: Mine reviews for mentions of sensitive content (violence, sexual content, triggers) to inform content warnings and parent guidance.
Temporal Analysis: Correlate review volume spikes with marketing events, awards, or media coverage. Measure campaign effectiveness by tracking review timing and sentiment shifts.
Review Quality Assessment: Use like counts and comment counts to identify most helpful reviews. Feature these in marketing materials or on book pages.
Advanced Techniques
Historical Tracking: Scrape same books monthly to build time-series datasets. Track how sentiment evolves post-release, identify sustained vs. initial enthusiasm.
Genre Benchmarking: Collect reviews across genre leaders. Establish baseline sentiment scores, average like counts, and review volumes for performance comparison.
Spoiler Pattern Analysis: Compare spoiler vs. non-spoiler reviews for sentiment differences. Determine if critics reveal more in spoiler reviews, impacting overall ratings.
ARC Impact Measurement: Segment pre-release reviews vs. organic reviews. Assess whether ARC readers rate higher/lower, impacting overall book perception.
Reviewer Consistency: Track individual reviewers across multiple books. Identify consistently harsh/generous critics to weight sentiment analysis appropriately.
Shelving Category Mining: Analyze custom shelves to discover how readers classify books. "Dark academia," "cozy mystery," or "slow burn romance" tags reveal micro-genre positioning.
Text Feature Engineering: Extract review length, exclamation point usage, emoji presence, reading speed mentions ("devoured in one night") as engagement proxies.
Network Analysis: Map reviewer-to-reviewer comment interactions. Identify book communities, controversial discussion topics, and review echo chambers.
Best Practices
Respect Rate Limits: Space out large scraping runs. Avoid overwhelming Goodreads servers with 1000+ concurrent requests. Batch process in 50-100 book increments.
Data Refresh Strategy: Review data becomes stale as new reviews post. Scrape monthly for active titles, quarterly for backlist. Archive historical data for trend analysis.
Privacy Considerations: Reviews are public, but avoid republishing reviewer names/profiles without context. Aggregate data for analysis rather than exposing individual user content.
Quality Filters: Remove extremely short reviews ("Great!" with no detail) or placeholder reviews ("DNF" with no explanation) before analysis for cleaner sentiment signals.
Sampling Strategy: For books with 10,000+ reviews, random sampling across different time periods provides representative data without exhaustive collection.
Cross-Platform Validation: Compare Goodreads sentiment with Amazon reviews, LibraryThing, or social media mentions for comprehensive reception understanding.
Metadata Enrichment: Combine review data with book metadata (publication date, page count, genre tags), sales rank data, and author information for multidimensional analysis.
Conclusion
The Goodreads Books Reviews Scraper converts reader feedback into actionable intelligence. From sentiment trends informing marketing strategy to competitive analysis revealing market positioning, review data drives better publishing decisions. Extract reader insights today to understand what resonates, what fails, and how to position your next release.
