Naukri Jobs Search Scraper
Pricing
from $2.00 / 1,000 results
Naukri Jobs Search Scraper
Efficiently scrape job listings from Naukri.com, India's #1 job site with 75+ million registered users. Extract comprehensive data including job titles, salaries, company details, skills requirements, and application deadlines. Perfect for recruitment agencies, job aggregators, salary benchmarking.
Pricing
from $2.00 / 1,000 results
Rating
0.0
(0)
Developer
Stealth mode
Maintained by CommunityActor stats
1
Bookmarked
838
Total users
8
Monthly active users
3 months ago
Last modified
Categories
Share
Naukri.com Jobs Search Scraper: Extract India's Largest Job Portal Data
Understanding Naukri.com and Its Market Dominance
Naukri.com dominates India's online recruitment landscape as the country's largest job portal, operated by Info Edge. With over 75 million registered job seekers and 100,000+ active employers, it serves as the primary hiring platform for Indian IT, finance, healthcare, and manufacturing sectors.
The platform specializes in Indian market nuances: salary ranges in INR/LPA (Lakhs Per Annum), work-from-home filtering, company ratings via Ambition Box integration, and skill-based matching for India's tech-heavy job market. For recruitment agencies targeting Indian talent, market researchers analyzing IT hiring trends, or job aggregators building comprehensive databases, Naukri data provides unmatched insights into Asia's third-largest economy.
This scraper automates extraction from search result pages, transforming filtered job listings into structured datasets ready for analysis, integration, or competitive intelligence.
What This Scraper Extracts and Who Should Use It
The Naukri.com Jobs Search Scraper processes search result pages, capturing multiple job listings efficiently. Unlike detail page scrapers requiring individual URLs, this tool handles entire search pages with filters applied.
Key extracted data: Job titles, company names and IDs, logos, salaries (currency and detail), experience requirements (min/max years), skills and tags, job descriptions, application deadlines, creation dates, URLs, work modes (office/hybrid/remote), Ambition Box ratings, and saved job status.
Target users:
IT Recruitment Agencies track tech hiring trends across programming languages, frameworks, and experience levels. Job Aggregators build comprehensive Indian job databases. Market Researchers analyze salary trends, skill demand, and hiring velocity in India's tech sector. Companies benchmark compensation, monitor competitor hiring, and identify talent shortages. Career Platforms integrate Naukri data for enhanced job discovery.
Input Configuration: Search URLs and Parameters
Example Configuration:
Example Screenshot:
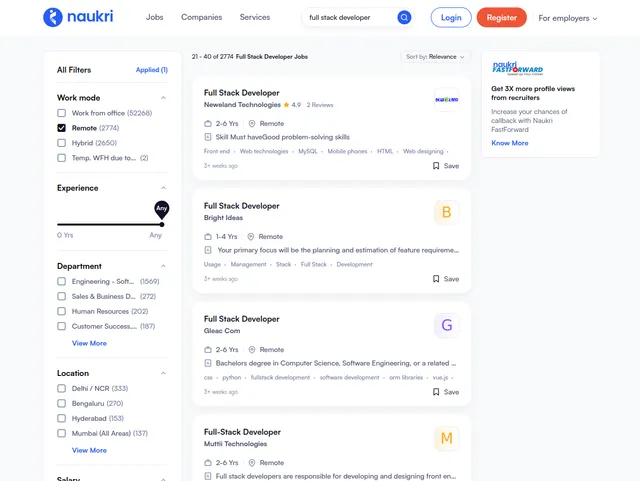
Parameter Breakdown:
proxy.useApifyProxy: Set false if Naukri doesn't require proxies in your use case, or true with residential proxies for enterprise-scale scraping. Test without proxies first—Naukri is generally accessible.
max_items_per_url: Extracts up to 20 jobs per search page (Naukri typically shows 20 per page). Increase to 50-100 for comprehensive extraction across multiple result pages.
ignore_url_failures: Set true when scraping multiple searches—one failed URL won't stop entire run. Essential for batch processing.
urls array: Contains Naukri search result URLs. The example shows full-stack developer jobs with work-from-home filter (wfhType=2). Build URLs by performing searches on Naukri, then copying resulting URLs with all filters intact.
URL Building Tips: Naukri uses query parameters for filters—?k=python (keyword), &experience=5 (years), &cityType=metropolitan (location tier), &wfhType=2 (work from home). Construct multiple URLs to cover different job types, locations, or experience bands.
Complete Output Structure and Field Definitions
Title: Job position name (e.g., "Senior Full Stack Developer"). Primary categorization field.
Logo Path / Logo Path V3: Company logo URLs. V3 is newer format. Use for displaying jobs visually.
Job ID: Unique Naukri identifier for the posting. Primary key for databases, deduplication.
Currency: Salary currency (typically "INR"). Essential for multi-market analysis.
Footer Placeholder Label / Color: UI elements for job card display. Indicates job freshness or special status.
Company Name: Hiring organization. Links to employer profiles, tracking hiring activity.
Is Saved / Saved: Boolean indicating if job was bookmarked (reflects scraper account state, not universally useful).
Tags and Skills: Array of required/preferred skills (e.g., ["React", "Node.js", "MongoDB"]). Critical for skill demand analysis and candidate matching.
Placeholders: Additional job metadata or UI indicators. Context-dependent display elements.
Company ID: Unique identifier for employer. Links multiple jobs from same company.
Job Description URL: Direct link to full job posting. Access complete details beyond search snippets.
Static URL: Alternative/canonical job URL format. Backup linking option.
Ambition Box Data: Company ratings and reviews from Ambition Box (Info Edge property). Employer reputation insights—ratings, review counts, culture scores.
Job Description: Brief excerpt visible in search results. Quick context for filtering/analysis.
Show Multiple Apply: Flag indicating if job has multiple application routes. Application complexity indicator.
Group ID / Is Top Group: Job grouping identifiers (similar positions from same employer). Deduplication and volume hiring signals.
Created Date: When job was posted. Freshness indicator, posting velocity analysis.
Mode: Employment mode—"office," "hybrid," "work from home." Critical for remote work trend analysis.
Board: Job category or vertical (IT, Finance, Sales). High-level classification.
Salary Detail: Structured salary object with min/max ranges. Typically in LPA (Lakhs Per Annum) for Indian market.
Experience Text: Human-readable experience requirement (e.g., "3-5 years").
Minimum Experience / Maximum Experience: Numeric experience bounds in years. Precise filtering and analysis.
Apply By Time: Application deadline timestamp. Urgency indicator, time-to-fill tracking.
Sample Output:
Step-by-Step Usage Guide
1. Define Target Jobs: Identify job types, skills, locations, or experience levels you need. Test searches on Naukri.com to refine filters.
2. Build Search URLs: Copy URLs from test searches. For large datasets, create multiple URLs: different technologies ("python-jobs," "java-jobs"), experience bands (0-2 years, 3-5 years), locations (Bangalore, Mumbai, Hyderabad).
3. Configure Input: Add URLs to JSON config. Set max_items_per_url to 20 for standard pages or higher for deep extraction. Enable ignore_url_failures for robustness.
4. Execute Scrape: Launch via Apify. Processing 5-10 search pages (100-200 jobs) typically completes in 2-4 minutes.
5. Export Data: Choose JSON for databases, CSV for analysis. Clean by removing duplicates using job_id or filtering by created_date for recent postings only.
6. Handle Pagination: For jobs spanning multiple pages, either include page URLs manually (...&page=2, ...&page=3) or set max_items_per_url higher to auto-paginate.
Strategic Applications for Indian Job Market Intelligence
Tech Skill Demand Tracking: Analyze tags_and_skills across thousands of jobs to identify trending technologies. Track React vs. Angular adoption, cloud platform preferences (AWS/Azure/GCP), or emerging frameworks.
Salary Benchmarking: Salary_detail data enables compensation analysis by skill, experience, location, and company size. Calculate average LPA for specific tech stacks or roles.
Remote Work Trends: Mode field tracks work-from-home vs. office vs. hybrid distribution. Analyze which industries/roles offer remote options most frequently.
Hiring Velocity Analysis: Created_date patterns reveal hiring surges (seasonal, funding-driven) and company expansion phases. Track posting frequency by employer.
Experience Level Demand: Minimum/maximum_experience fields show market demand distribution—entry-level saturation vs. senior talent shortages.
Company Hiring Monitoring: Track specific companies via company_id and company_name. Monitor competitors' job types, volumes, and growth signals.
Application Urgency Insights: Apply_by_time reveals hiring urgency. Short windows (7-14 days) indicate desperate hiring; long windows (60+ days) suggest selective processes.
Maximizing Data Value and Best Practices
Weekly Scraping Cadence: India's tech market moves fast. Weekly scrapes capture new postings and market shifts. Store historical data for trend analysis.
Segment by Technology: Create separate searches for Python, Java, JavaScript, Cloud, DevOps, Data Science. Cleaner datasets, easier analysis.
Enrich with Ambition Box: Use ambition_box_data to correlate company ratings with hiring difficulty (low-rated companies may struggle to fill roles).
Geographic Segmentation: India's metro cities (Bangalore, Pune, Hyderabad, Mumbai, NCR) have distinct markets. Scrape separately for regional insights.
Quality Checks: Flag anomalies—salaries outside normal ranges, missing experience requirements, or very old created_dates may indicate data issues.
Skill Co-occurrence Analysis: Mine tags_and_skills to find skill combinations (React + Node.js + AWS). Helps identify full-stack requirements and technology ecosystems.
Respect Rate Limits: Space out large scraping runs. Sustainable practices ensure continued access.
Conclusion
The Naukri.com Jobs Search Scraper unlocks India's largest job market dataset. From tech skill trends to salary benchmarks and remote work adoption, this tool transforms public job data into actionable intelligence for recruitment, market research, and competitive analysis in Asia's fastest-growing digital economy.