YouTube Ultimate Scraper (PPE)
Pricing
Pay per event
YouTube Ultimate Scraper (PPE)
Scrape videos, comments, replies, transcripts, and channel metadata with YouTube Ultimate Scraper. Designed for flexibility, speed, and reliability, it’s perfect for everything from one-off research to large-scale automation.
Pricing
Pay per event
Rating
5.0
(3)
Developer
Ultimate Insight
Maintained by CommunityActor stats
8
Bookmarked
188
Total users
4
Monthly active users
8 months ago
Last modified
Categories
Share


🧭 How it Works
YouTube Ultimate Scraper is built for flexibility and optimized for cost efficiency. Whether you're targeting a few specific videos or extracting large volumes of content across multiple discovery paths, the scraper gives you full control over how content is selected, processed, and returned.
Many Ways to Crawl & Scrape YouTube
You can launch a scraping run using a variety of input types, depending on your goals:
- Use a mixed list of YouTube URLs, including videos, channels, hashtags, and searches, as your crawl/scrape targets. The scraper will automatically infer what you want from the URLs.
- Provide an explicit list of video, short, or livestream IDs to scrape them directly.
- Crawl one or more channels (using channel IDs or @handles) to discover and scrape their video content.
- Submit a list of hashtags to crawl videos tagged with those terms.
- Define one or more global search queries to discover relevant video results across YouTube.
- Include a 'skip list' of video IDs to ignore, enabling you to scrape the same source multiple times and always get just the freshest content.
Just the Results You Need
Once your crawl targets are defined, you can specify exactly which types and format of data you want to collect:
- For channel crawls, choose whether to include videos, shorts, livestreams, or any combination.
- Enable or disable video comments, and optionally include their replies.
- Enable video transcripts, with support for multiple language variants where available.
- Include extended channel metadata for each scraped video, if desired.
Sensible Value-based Pricing
Thanks to Apify's Pay per Event (PPE) pricing model, you'll never be billed for platform fees or other unexpected running costs; just pay for the YouTube data that you actually receive.
- Pay a fixed rate for each result delivered (with per item add-on charges if you choose to activate optional content, like comments, transcripts or channel metadata).
- Set precise limits for the number of results returned per channel, hashtag, or search.
- Set similar limits on individual add-on items, such as the number of comments per video or replies per comment.
Please refer to our pricing for full details of the charges that may be raised during a scraping run. Note that we participate in Apify's tiered pricing scheme, which means that you'll get progressively larger discounts on all our charges, according to your Apify subscription level.
💡 Some Typical Use Cases
YouTube is full of valuable insights - you just need the right tools to extract them. Below are five of our favorite real-world examples, showing how scraping can help creators, marketers, and analysts turn YouTube data into actionable results.
YouTube Content Inspiration
You are a successful (or aspiring) YouTuber, looking for fresh content ideas that will take your channel to the next level.
Scrape videos and comments from one or more competitors' YouTube channels. Then feed the comment data into an AI assistant and ask it to summarize the recurring questions, complaints, and suggestions raised by viewers, optionally weighting the input based on likes or replies. Once you’ve isolated the topics your audience cares about most, prompt the AI to brainstorm video ideas, complete with compelling titles and structured outlines.
Content Repurposing
You are a web marketer, using YouTube as one of your promotional channels and you want to leverage your content for re-use across other platforms.
Popular long-form videos are goldmines for cross-platform content. Start by identifying your top-performing videos using YouTube analytics, then scrape them to retrieve their auto-generated transcripts. These transcripts can be transformed into blog posts, email newsletters, or scripts for TikTok/Instagram shorts - all with minimal effort using an AI content generator. With this approach, you dramatically expand your content footprint without increasing your production time.
Influencer Discovery and Outreach
You are a brand or agency scouting for micro-influencers to partner with in a specific niche.
Scrape videos based on niche-relevant keywords or hashtags and capture metadata such as view counts, likes, subscriber counts, and comment sentiment. Use AI to filter for creators with high engagement but modest follower bases (an indicator of authenticity and influence). Pair this with comment analysis to ensure their audience aligns with your brand values. You now have a curated list of potential partners, complete with campaign ideas grounded in real viewer conversations.
Sentiment Analysis for Product Feedback
You are a product team or customer success manager looking for honest, unsolicited feedback about your product or service.
Scrape all YouTube videos that mention your brand or product, along with their comments. Feed these into a sentiment analysis pipeline that classifies viewer reactions (positive, negative, neutral), identifies common pain points, and highlights praised features. This method surfaces high-signal feedback that may never make it into formal surveys or support tickets - giving you a more nuanced and actionable understanding of your customer experience.
Competitor Intelligence and Trend Monitoring
You are a product manager, strategist, or startup founder keeping a close eye on your industry’s key players.
Scrape recent uploads from competitors in your niche and analyze their video titles, descriptions, view counts, and publishing frequency to identify emerging content themes, product announcements, or campaign strategies. Use AI to cluster video content into topics and extract engagement metrics to discover which themes resonate most with audiences. This gives you a powerful, low-cost way to track market sentiment and stay one step ahead - without needing to rely on expensive competitive research tools.

🚀 Quick Start
When we designed YouTube Ultimate Scraper, flexibility was one of our core goals. We knew users would need to scrape YouTube data in many different ways - ranging from quick tests to complex, large-scale extractions - so we built a tool that adapts to your needs without requiring a complex setup process.
With over 100 available settings, this scraper offers deep configurability. But instead of exposing everything up front, we’ve surfaced only the most essential options in the Apify Input tab - enough to get started quickly. Advanced configuration remains accessible when you need more control (and we're ready to help, if you need it).
The Input tab in Apify exposes the scraper’s basic settings, allowing you to launch any supported crawl or scrape workflow in just a few clicks.
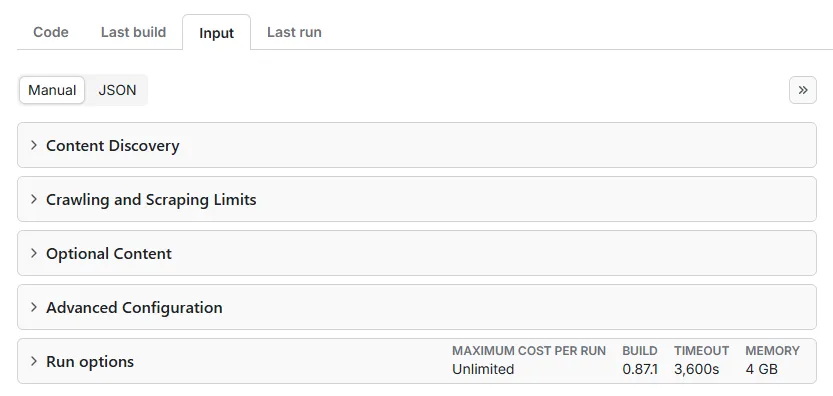
Start by entering one or more YouTube URLs. This defines the content you want to scrape.
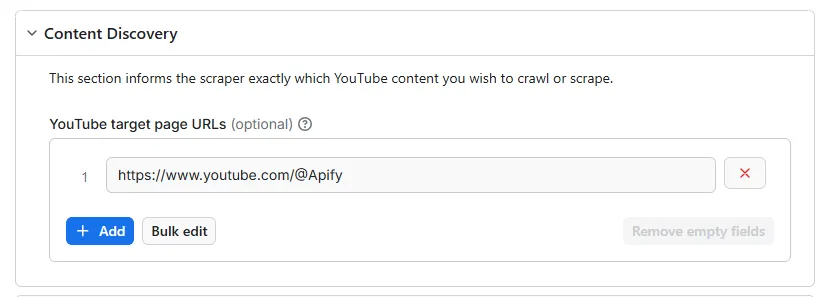
With each URL entered, you can target a single video, a hashtag, a search query or part or all of the content from a channel, and you're free to mix URL formats as you choose. For supported formats, refer to this table.
Next, configure how much content you want to retrieve. For example, you might scrape only the first 100 long-form videos from a channel, excluding shorts and livestreams.
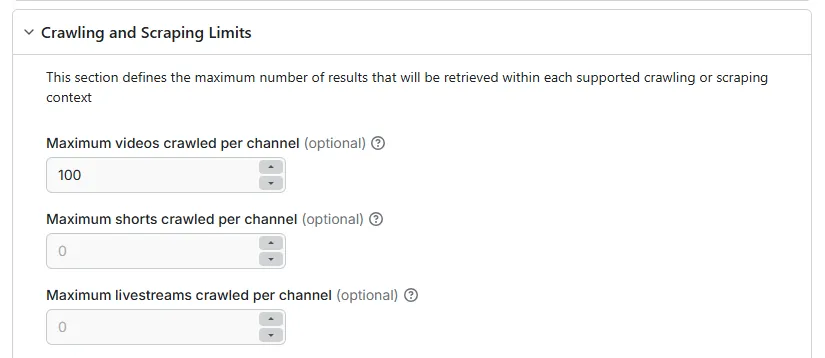
Only the most commonly-used limit settings are exposed via the Input tab. A complete list is available here.
Important: By default, all crawling and scraping limits are set to zero. Unless you’re targeting a fixed list of video IDs or URLs, you must set at least one non-zero crawling limit. If not, the run will terminate immediately, reporting a configuration error.
As a final step, you may wish to add some optional content to your result set.
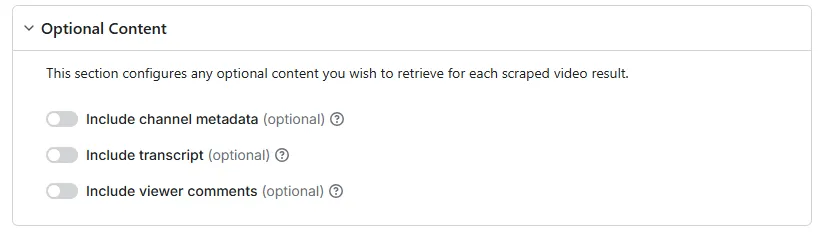
If you add comments to your scraping run, you'll also need to configure their limit, to inform the scraper how many to retrieve for each target video.

Once your target URLs and scraping limits are set, and you have enabled any desired optional content, you can launch the run using standard Apify procedures.
🛠️ Advanced Configuration
The basic settings are powerful enough for most users, but when you need full control over filtering, output formatting, sorting, or handling edge cases, you can use advanced configuration.
Advanced configuration is defined in a JSON snippet that you paste into the Advanced configuration field in the Input tab.
You can override as little or as much of the default configuration as you want. For example, the following snippet tells the scraper to include embedded channel metadata with each video:
To create an advanced configuration, the easiest approach is to start from our template, remove anything you don’t need, and then modify the relevant settings.
We’ve compiled a full reference of all advanced settings, including their descriptions and default values. If you need help, feel free to reach out.
💥 Scraper Breakage Detection and Recovery
A scraper breakage occurs when a previously working and tested scraper stops functioning correctly or begins returning incomplete or incorrect results. These breakages are invariably caused by changes to the target website or its underlying APIs.
Unfortunately, this is a persistent and well-known challenge in the web scraping space. Most scrapers rely on a reactive approach: problems are only investigated once users report that something has gone wrong. The scraper developer must then manually debug the implementation - often without clear guidance - making diagnosis and resolution a time-consuming process.
YouTube Ultimate Scraper takes a fundamentally different approach. Our goal is to provide a higher standard of reliability and responsiveness by actively detecting and resolving breakages before they affect you.
To minimize downtime and ensure scraping reliability, we’ve implemented the following strategy:
-
Built-in Schema Validation
Every scraper run performs detailed validation against a defined set of expected data schemas. This helps identify breakages immediately - even when they only affect a subset of the output structure. -
Comprehensive Test Suite
We maintain an automated test suite covering over 30 real-world YouTube scraping scenarios, spanning all major workflows, data types, and content formats. -
Daily Test Runs
Our test suite is executed daily, allowing us to detect breakages early - often before users are even aware an issue has occurred. -
Rapid Response and Fixes
When a breakage is detected, resolving it becomes our top development priority. Fixes are issued as quickly as possible, often the same day. -
Expanding Coverage
If a user reports a scraping failure that isn't yet covered by our test suite, we not only investigate and fix the issue, but also incorporate the new scenario into our test coverage to prevent future regressions.
This proactive approach allows us to deliver a more stable and reliable experience to our users, and to respond to platform changes with greater speed and precision.
If you ever notice a problem with your scraping results, please report it, so that we can address it immediately.
🛡️ Anti-scraping Defenses
Websites like YouTube employ various anti-scraping defenses to detect and block automated access. These can include:
- IP-based rate limiting or blocking
- Cookie and session tracking
- Return of misleading or incomplete data to suspected bots
These measures are a persistent challenge for scrapers, particularly when performing high-volume or frequent operations.
Unlike most scrapers that rely on headless browsers to simulate user behavior, YouTube Ultimate Scraper takes a more efficient and resilient approach:
-
API-first Architecture
The majority of YouTube data is retrieved directly via internal API endpoints, rather than parsed from HTML. This results in faster, cleaner data retrieval with fewer parsing risks and the ability to proactively deal with breakages. -
Lightweight Scraper Engine
The scraper uses Apify'sBasicCrawlerinstead of a headless browser, which optimizes scraping execution, while still achieving full feature coverage via API interaction. -
Residential Proxies
All requests are sent through residential proxies by default, helping to bypass IP-based detection and geo-specific restrictions. -
Proxy Rotation and Session Management
The scraper rotates proxies automatically and employs a fine-grained session management strategy, ensuring the optimum balance of speed, accuracy and resilience.
This architecture enables the scraper to operate with a lower detection profile while maintaining high throughput and stability.
📶 Tips for Effective Scraping
To get the best results from your YouTube scraping runs, a few simple practices can make a big difference. Whether you're aiming to reduce execution time and cost or improve the relevance of your output, these tips will help you configure your runs more effectively and avoid common pitfalls.
Content Sorting
The scraper supports three separate sorting mechanisms, which may initially appear redundant. However, they fall into two distinct categories - pre-crawl sorting and post-scrape sorting - each serving a specific purpose.
Understanding when and how to apply these options can significantly improve the relevance and structure of your output.
Pre-crawl Sorting
Pre-crawl sorting is used to prioritize which content gets selected before any scraping begins. This is especially important when applying fixed crawl limits - for example, retrieving the first 100 videos from a channel or the top 50 search results.
If you're looking for the most recent videos, for instance, we recommend applying a 'latest' sort before the crawl begins, ensuring that your limited set of videos is chosen from the most relevant pool of candidates.
The following settings control pre-crawl sorting:
crawling.listSort- sorts listed videos, shorts, and livestreams on channel pages (reference)crawling.searchFilters.sort- sets sorting mode for global search results (reference)
Post-scrape Sorting
After all selected content has been crawled and scraped, you may want to apply sorting to the final output. This type of sorting operates across the entire result set, ensuring consistent ordering in the exported data - regardless of crawl order.
The following setting applies post-scrape sorting:
output.sort- Sorts the complete set of scraped results before export
When output sorting is enabled, the result set will be exported in a single pass, when scraping is completed. This is because it is not possible to perform sorting until the entire result set is available. When sorting is disabled (the default setting), results will be exported periodically, as they are scraped.
Date Filtering
Many users want to scrape YouTube content within a specific date range (for example, videos published on a given channel in the past month).
While it would be preferable to apply a date filter during the crawling phase (to avoid scraping irrelevant items), this is not possible, for two key reasons:
- YouTube does not provide any reliable date-based filtering via its official APIs or page URLs.
- The publication dates shown in listings are approximate (e.g. “3 weeks ago”), inconsistent, and not always available (especially for shorts, livestreams, or some content categories).
As a result, the only dependable method of date filtering is to perform a broad scrape and then apply the date filter afterward, removing any items outside the desired range. This approach is less efficient but offers a practical workaround to the limitations imposed by YouTube's design.
Filtering Costs
When using date filtering, you will not be directly charged for any of the discarded results. However, because this process incurs some additional operating costs, your delivered result set will be subject to an add-on charge that marginally increases their unit cost. Please see pricing for details.
Filtering Caveats
If you're also applying a crawl limit (e.g. scraping the first 100 videos from a channel), be aware that the limit is applied before date filtering. This means your candidate pool might contain few or even no items that pass the date filter.
Filtering Best Practice
To improve results, combine date filtering with a pre-crawl sorting strategy that complements it. For example, if you're interested in videos from the past month, apply a 'latest' list sort to prioritize recent content during crawling.
This increases the likelihood that the scraped data includes videos that match your date criteria, even if a crawl limit is in place.
Authentication
Some platforms (such as Instagram and Facebook) severely restrict the content that is available without logging in. Thankfully YouTube doesn't (currently) work that way, so it is possible to scrape YouTube as an anonymous user.
Why is this important? Because, although it's a relatively straightforward task to configure a scraper to log into an account, on almost any platform, it comes with the risk that the platform will identify it as a bot and then ban the account that it's logged into.
With YouTube Ultimate Scraper, you don't have to worry about this issue. You will never be asked to provide identification and your YouTube scraping will always be carried out anonymously.
Incremental Scraping
In many scraping scenarios, you may wish to revisit previously scraped content sources, such as YouTube channels, hashtags, or search results, without duplicating data already collected in earlier runs. This is particularly relevant when:
- Scraping multiple related search terms that may return overlapping video results
- Periodically updating the video list for a channel, but only wishing to retrieve new uploads
To support these use cases efficiently, the scraper offers an incremental scraping feature (configured using the discovery.ignoreIds setting) that allows you to exclude previously-scraped video IDs from the current run.
Filtering out previously scraped content can deliver a significant cost saving, since you are only charged for results that are actually delivered. Ignored videos are never scraped, so no charge is incurred for them. This saving extends even further when you're also adding optional content, such as channel metadata, video transcripts, or comments/replies.
A small charge is applied for each video ID in the ignore list, but this is typically much lower than the combined cost of the duplicate content that it eliminates. Incremental scraping is therefore highly recommended when you want to keep your data fresh without paying for the same content more than once.
🆘 Support & Onboarding Service
We want you to enjoy the best possible experience while using YouTube Ultimate Scraper, so we're laser focused on providing the support you need, when you need it.
If you run into an obstacle, while configuring or using the scraper, please raise an issue, and we'll give it our rapid attention. We treat bugs and breakages as an absolute priority, but we're also keen to help out with advice and guidance that will make your scraping task easier and more effective.
Some users also tell us that they feel a little overwhelmed by the sheer scope of the configuration options offered by this scraper. Most users appreciate its vast flexibility, but not everyone is certain how to harness it. If that's you, our onboarding service may be the answer. We'll schedule a short video call to understand your scraping goals, then we'll design a custom scraping configuration that you're free to use as you choose.
To claim your free session, simply leave us a rating in the Apify marketplace. 5 stars would be much appreciated, but it's definitely not a pre-condition. Then contact us to schedule your free onboarding. We look forward to working with you.
⚙️ Configuration Settings Reference
This section documents every supported configuration setting. Each sub-section below corresponds to an individual settings object within the advanced configuration JSON data hierarchy. While using this reference, we recommend also referring to the JSON Configuration Template, to better visualize the hierarchical relationships between objects.
Discovery Settings
Discovery settings tell the scraper exactly which YouTube content you wish to scrape. You can specify your requirements using either IDs or URLs and mix them as you choose. The full range of discovery settings may be configured in the discovery object. Additionally, URL-based discovery is also configurable via the Apify Input tab.
The settings in this section can potentially affect your run costs. Please see pricing for details.
| Setting | Type | Default | Usage |
|---|---|---|---|
videoIds | string[] | [] | An array of strings, each being a valid YouTube video ID. |
channelIds | string[] | [] | An array of strings, each being a valid YouTube channel ID or channel handle. |
searchQueries | string[] | [] | An array of strings, each being a search term used to perform a YouTube global search. |
hashtags | string[] | [] | An array of strings, each being a keyword that identifies a valid YouTube hashtag. |
urls | string[] | [] | An array of strings, each being a YouTube URL in one of the supported formats. |
ignoreIds | string[] | [] | An array of strings, each being the ID of a previously-scraped YouTube video that should be skipped in the current run. See Incremental Scraping. |
Crawling Settings
Crawling settings are configured in the crawling object and determine how the scraper will execute a run. Some settings are configured as direct properties of the crawling object, while others are exposed via nested objects.
| Setting | Type | Default | Usage |
|---|---|---|---|
proxyCountry | enum | 'US' | The 2-digit code of the country that hosts the Apify proxies that will be used for crawling/scraping. The proxy location determines how YouTube perceives the origin of your HTTP requests and may influence which content is available to you. In most cases we recommend using the default setting. However, if the content you are seeking to scrape is geographically restricted, you may need to choose a proxy country that provides better access to it. Supported values are 'US', 'GB', 'DE', 'FR', 'CA', 'AU', 'IT', 'ES', 'NL', 'IN', 'BR' and 'MX'. |
searchFilters | object | Nested Settings | Contains a nested search filter settings object, which enables the scraper to emulate YouTube's global search filters. |
limits | object | Nested Settings | Contains a nested limit settings object, which determines the limits that constrain crawling and scraping. |
listSort | enum | 'latest' | The order in which content listings on channel pages are sorted, prior to crawling. As explained here, this setting can have a significant effect on the quality and relevance of scraped results, (especially when using tight crawl limits). Supported values are 'latest', 'popular' and 'oldest'. |
Search Filter Settings
Search filters are configured in the crawling.searchFilters object and emulate the native filter mechanism that YouTube offers for global searches. This is a convenience feature that allows you to configure a common search filter profile that will be used by all global searches targeted using the discovery.searchQueries setting. Note that this common profile is not used by global searches targeted using URLs, as YouTube's search URL format incorporates its own filter parameter. We recommend using URLs if you require individual filtering profiles for each search term.
| Setting | Type | Default | Usage |
|---|---|---|---|
sort | enum | null | The sort order applied to global searches. Supported values are 'relevance', 'upload', 'views' and 'rating'. |
recency | enum | null | The recency filter applied to global searches. Supported values are 'hour', 'day', 'week', 'month' and 'year'. |
type | enum | null | The content type filter applied to global searches. Supported values are 'video', 'channel', 'playlist' and 'movie'. |
duration | enum | null | The duration filter applied to global searches. Supported values are 'under4', '4to20' and 'over20', which represent the duration of the video in minutes. |
features | enum[] | [] | The content feature filters applied to global searches. Multiple features may be specified. Supported values are 'live', '4k', 'hd', 'subtitles', 'cc', '360', 'vr180', '3d', 'hdr', 'location' and 'purchased'. |
Limit Settings
Crawling limits determine the maximum number of results that will be retrieved within a given context (for example, the number of videos scraped for each target channel). All crawling limits may be configured in the crawling.limits object. Most of the limit settings are also exposed via the Apify Input tab.
Unless you’re targeting a fixed list of video IDs or URLs, you must set at least one non-zero crawling limit, otherwise no content will qualify for crawling and the run will not execute.
The settings in this section can potentially affect your run costs. Please see pricing for details.
| Setting | Type | Default | Usage |
|---|---|---|---|
maxChannelVideos | integer | 0 | The maximum number of long-form videos to be retrieved while crawling each target channel. Each video will be subsequently scraped to yield a single video metadata result set. |
maxChannelShorts | integer | 0 | The maximum number of shorts to be retrieved while crawling each target channel. Each short will be subsequently scraped to yield a single video metadata result set. |
maxChannelStreams | integer | 0 | The maximum number of livestreams to be retrieved while crawling each target channel. Each livestream will be subsequently scraped to yield a single video metadata result set. |
maxChannelSearchResults | integer | 0 | The maximum number of videos to be retrieved while crawling each target channel search. Each video will be subsequently scraped to yield a single video metadata result set. |
maxGlobalSearchResults | integer | 0 | The maximum number of videos to be retrieved while crawling each target global search. Each video will be subsequently scraped to yield a single video metadata result set. |
maxHashtagResults | integer | 0 | The maximum number of videos to be retrieved while crawling each target hashtag. Each video will be subsequently scraped to yield a single video metadata result set. |
maxVideoComments | integer | 0 | The maximum number of comments to be scraped for each scraped video. |
maxCommentReplies | integer | 0 | The maximum number of replies to be scraped for each scraped comment. |
Output Settings
Output settings are configured in the output object and determine the composition of the output result set. Some settings are configured as direct properties of the output object, while others are exposed via nested objects.
| Setting | Type | Default | Usage |
|---|---|---|---|
sort | enum | false | An enum member value that indicates the order in which the output result set will be sorted, or false to indicate that output sorting is disabled. Supported values are 'recency', 'views', 'likes', 'length' and false. See Content Sorting. |
dateFilter | object | Nested Settings | A nested date filter settings object, which determines how videos are filtered from the output result set, based on their publication date. |
videoMetadata | object | Nested Settings | A nested video metadata settings object, which determines how video metadata scraping is executed. |
channelMetadata | multiple | Nested Settings | Typically a nested channel metadata settings object, which determines how channel metadata scraping is executed. This property may also be assigned the value true, indicating that channel metadata scraping is executed using default settings, or false, indicating that channel metadata scraping is disabled. |
transcript | multiple | Nested Settings | A nested transcript settings object, which determines how video transcript scraping is executed. This property may also be assigned the value true, indicating that transcript scraping is executed using default settings, or false, indicating that transcript scraping is disabled. |
comments | multiple | Nested Settings | A nested comments settings object, which determines how comment scraping is executed. This property may also be assigned the value true, indicating that comment scraping is executed using default settings, or false, indicating that comment scraping is disabled. |
Date Filter Settings
Date filter settings are configured in the output.dateFilter object and determine how videos are filtered from the output result set, based on their publication date.
The settings in this section can potentially affect your run costs. Please see pricing for details.
| Setting | Type | Default | Usage |
|---|---|---|---|
startDate | string | '1970-01-01T00:00:00' | A string in ISO 8601 extended datetime format (without an explicit timezone) that indicates a UTC date/time. Only videos published after this will be included in in output result set. See Date Filtering. |
endDate | string | '2199-01-01T00:00:00' | A string in ISO 8601 extended datetime format (without an explicit timezone) that indicates a UTC date/time. Only videos published before this will be included in in output result set. See Date Filtering. |
Video Metadata Settings
Video metadata settings are configured in the output.videoMetadata object and determine the composition of scraped video data in the output result set. By toggling individual data properties, you can shape the output result set to match your exact requirements. However, note that enabling a data property does not guarantee that it will be included in every result, as the completeness of YouTube video metadata can vary between videos.
| Setting | Type | Default | Usage |
|---|---|---|---|
url | boolean | true | Whether to include the video URL in output video metadata. |
channelId | boolean | true | Whether to include the channel ID in output video metadata. |
author | boolean | true | Whether to include the video author name in output video metadata. |
title | boolean | true | Whether to include the video title in output video metadata. |
description | boolean | true | Whether to include the video description in output video metadata. |
keywords | boolean | true | Whether to include the video keywords in output video metadata. |
length | boolean | true | Whether to include the video duration in output video metadata. |
thumbnails | boolean | true | Whether to include the video thumbnail data in output video metadata. |
metrics | boolean | true | Whether to include the video metrics in output video metadata. |
allowRatings | boolean | true | Whether to include the the allowsRatings flag in output video metadata. |
isPrivate | boolean | true | Whether to include the the isPrivate flag in output video metadata. |
isLiveContent | boolean | true | Whether to include the the isLiveContent flag in output video metadata livestream. |
isUnlisted | boolean | true | Whether to include the the isUnlisted flag in output video metadata. |
captionTracks | boolean | true | Whether to include the video transcript languages list in output video metadata. |
category | boolean | true | Whether to include the video category name in output video metadata. |
publishDate | boolean | true | Whether to include the video publication date in output video metadata. |
ownerChannelName | boolean | true | Whether to include the video owner channel name in output video metadata. |
viewCount | boolean | true | Whether to include the video view count in output video metadata. |
likeCount | boolean | true | Whether to include the video like count in output video metadata. |
Channel Metadata Settings
Channel metadata settings are configured in the output.channelMetadata object and determine the composition of scraped channel data in the output result set. By toggling individual data properties, you can shape the output result set to match your exact requirements. However, note that enabling a data property does not guarantee that it will be included in every result, as the completeness of YouTube channel metadata can vary between channels.
| Setting | Type | Default | Usage |
|---|---|---|---|
handle | boolean | true | Whether to include the channel handle in output channel metadata. |
title | boolean | true | Whether to include the channel title in output channel metadata. |
description | boolean | true | Whether to include the channel deescription in output channel metadata. |
keywords | boolean | true | Whether to include the channel keywords in output channel metadata. |
country | boolean | true | Whether to include the channel country in output channel metadata. |
avatar | boolean | true | Whether to include the channel avatar URLs in output channel metadata. |
joinedDateText | boolean | false | Whether to include the channel owner joined date in output channel metadata (in its original raw text form). |
joinedDate | boolean | true | Whether to include the parsed channel owner joined date in output channel metadata. |
channelAgeDays | boolean | true | Whether to include the parsed channel age (days) in output channel metadata. |
channelUrl | boolean | true | Whether to include the channel URL in output channel metadata. |
canonicalUrl | boolean | true | Whether to include the channel canonical URL in output channel metadata. |
rssUrl | boolean | true | Whether to include the channel RSS URL in output channel metadata. |
videosUrl | boolean | true | Whether to include the channel videos page URL in output channel metadata. |
shortsUrl | boolean | true | Whether to include the channel shorts page URL in output channel metadata. |
liveUrl | boolean | true | Whether to include the channel livestrams page URL in output channel metadata. |
playlistsUrl | boolean | true | Whether to include the channel playlists page URL in output channel metadata. |
aboutUrl | boolean | true | Whether to include the channel about page URL in output channel metadata. |
searchUrl | boolean | true | Whether to include the channel search page URL in output channel metadata. |
ownerUrls | boolean | true | Whether to include the channel owner URL in output channel metadata. |
links | boolean | true | Whether to include the channel link data in output channel metadata. |
hasBusinessEmailAddress | boolean | true | Whether to include the hasBusinessEmailAddress flag in output channel metadata. |
isFamilySafe | boolean | true | Whether to include the isFamilySafe flag in output channel metadata. |
subscriberCountText | boolean | false | Whether to include the channel subscriber count text in output channel metadata (in its original raw text form). |
subscriberCount | boolean | true | Whether to include the parsed channel subscriber count in output channel metadata. |
viewCountText | boolean | false | Whether to include the channel view count text in output channel metadata (in its original raw text form). |
viewCount | boolean | true | Whether to include the parsed channel view count in output channel metadata. |
videoCountText | boolean | false | Whether to include the channel video count text in output channel metadata (in its original raw text form). |
videoCount | boolean | true | Whether to include the parsed channel video count in output channel metadata. |
averageViewCount | boolean | true | Whether to include the calculated average video view count in output channel metadata. |
availableCountryCodes | boolean | true | Whether to include the channel available country codes list in output channel metadata. |
Transcript Settings
Transcript settings are configured in the output.transcript object and determine the composition of scraped transcript data in the output result set.
| Setting | Type | Default | Usage |
|---|---|---|---|
language | string | 'en' | A 2-character ISO language code that indicates the desired language for scraped transcripts. Note that the transcripts for most videos are typically only available in limited range of languages and that some videos have no transcripts. If the specified language is not available, no transcript will be scraped, even if other languages are available. Supported language codes are en Englishnl Dutchfr Frenchde Germanit Italianja Japaneseko Koreanpt Portugueseru Russianes Spanishth Thaitr Turkishuk Ukrainianvi Vietnamese |
format | enum | 'timeline' | The format in which scraped transcript data will be presented in the output result set. The default 'timeline' format is an array of JSON objects, representing individual transcript segments, and includes both the transcript text and its timestamp data. The alternative 'contionuous' format discards all timestamp data and concatenates the text of all transcript segments into a continuous string value. Supported values are 'timeline' and 'continuous'. |
Comments Settings
Comments settings are configured in the output.comments object and determine the composition of scraped comment data in the output result set. By toggling individual data properties, you can shape the output result set to match your exact requirements.
| Setting | Type | Default | Usage |
|---|---|---|---|
totalCount | boolean | true | Whether to include the total video comment count in output comment data. |
publishedDateText | boolean | false | Whether to include the comment published date/time in output comment data (in its original raw text form). |
publishedDate | boolean | true | Whether to include the parsed comment published date/time in output comment data. |
isPinned | boolean | true | Whether to include the isPinned flag in output comment data. |
isHearted | boolean | true | Whether to include the isHearted flag in output comment data. |
hasDonation | boolean | true | Whether to include the hasDonation flag in output comment data. |
level | boolean | true | Whether to include the comment level in output comment data. |
authorChannelId | boolean | true | Whether to include the comment author channel ID in output comment data. |
authorDisplayName | boolean | true | Whether to include the comment author display name in output comment data. |
isCreator | boolean | true | Whether to include the isCreator flag in output comment data. |
isVerified | boolean | true | Whether to include the isVerified flag in output comment data. |
likeCount | boolean | true | Whether to include the comment like count in output comment data. |
replyCount | boolean | true | Whether to include the comment reply count in output comment data. |
replies | multiple | Nested Settings | Typically a nested replies settings object, which determines how comment reply scraping is executed. This property may also be assigned the value true, indicating that reply scraping is executed using default settings, or false, indicating that reply scraping is disabled. |
Replies Settings
Replies settings are configured in the output.comments.replies object and determine the composition of scraped comment reply data in the output result set. By toggling individual data properties, you can shape the output result set to match your exact requirements.
| Setting | Type | Default | Usage |
|---|---|---|---|
publishedDateText | boolean | false | Whether to include the reply published date/time in output reply data (in its original raw text form). |
publishedDate | boolean | true | Whether to include the parsed reply published date/time in output reply data. |
isPinned | boolean | true | Whether to include the isPinned flag in output reply data. |
isHearted | boolean | true | Whether to include the isHearted flag in output reply data. |
hasDonation | boolean | true | Whether to include the hasDonation flag in output reply data. |
level | boolean | true | Whether to include the reply level in output reply data. |
authorChannelId | boolean | true | Whether to include the reply author channel ID in output reply data. |
authorDisplayName | boolean | true | Whether to include the reply author display name in output reply data. |
isCreator | boolean | true | Whether to include the isCreator flag in output reply data. |
isVerified | boolean | true | Whether to include the isVerified flag in output reply data. |
likeCount | boolean | true | Whether to include the reply like count in output reply data. |

🧪 Sample Output Data
A successful scraper run yields one or more JSON output files, each containing the metadata for a scraped video. Each ouput file contains a single root-level JSON object, with optional nested objects, depending on your output settings.
Video Metadata Sample
The root-level JSON object represents the metadata for a scraped video. The sample below reflects the most verbose form of video metadata output, but all data properties, including nested data objects, are configurable.
Channel Metadata Sample
Nested within a video metadata object is an optional channel metadata object, representing the channel that owns the video. The sample below reflects the most verbose form of channel metadata output, but all data properties are individually configurable.
Transcript Sample
Nested within a video metadata object is an optional transcript array (or string), representing the transcript of the video in one of its available languages. The sample below reflects the transcript output in 'timeline' format, but this may optionally be configured as a continuous stream of text.
Comments/Replies Sample
Nested within a video metadata object is an optional comments collection, representing a subset or all of the video's viewer comments. The sample below reflects the most verbose form of comments output, but all data properties, including replies, are individually configurable.
🔗 Supported URL Formats
When configuring your scraper, either via the Apify Input tab or using advanced configuration, a variety of valid YouTube URLs may be used to indicate the target content that you wish to scape. The table below shows the supported URL formats and how to use them. A single scraping run may incorporate any mix of URL formats (as well as ID-based content targeting, if you need it).
| URL Type / Examples | How it Works |
|---|---|
| Video page URL https://www.youtube.com/watch?v=VIDEO_ID | Enter one or more video page URLs to identify videos to be scraped. The scraper will output a single scraping result for each URL entered. |
| Channel home page URL https://www.youtube.com/@CHANNEL_HANDLE https://www.youtube.com/channel/CHANNEL_ID | Enter one or more channel home page URLs to identify channels to be crawled. Note that both ID-based and handle-based URL formats are supported. The crawler will extract the IDs of target videos, shorts and livestreams on the designated channel and the scraper will output a single scraping result for each of them (subject to your configured limits). |
| Channel content page URL https://www.youtube.com/@CHANNEL_HANDLE/videos https://www.youtube.com/channel/CHANNEL_ID/videos https://www.youtube.com/@CHANNEL_HANDLE/shorts https://www.youtube.com/channel/CHANNEL_ID/shorts https://www.youtube.com/@CHANNEL_HANDLE/streams https://www.youtube.com/channel/CHANNEL_ID/streams | Enter one or more channel content page URLs to identify a specific channel content type to be crawled (for example, videos). The crawler will extract target video IDs from the designated content page and the scraper will output a single scraping result for each of them (subject to your configured limits). |
| Channel search page URL https://www.youtube.com/@CHANNEL_HANDLE/search?query=football https://www.youtube.com/channel/CHANNEL_ID/search?query=football | Enter one or more channel search page URLs to identify a subset of channel content to be crawled. The crawler will extract target video IDs from the search results and the scraper will output a single scraping result for each of them (subject to your configured limits). |
| Hashtag page URL https://www.youtube.com/hashtag/football | Enter one or more YouTube hashtag page URLs to identify a themed selection of content to be crawled. The crawler will extract target video IDs from the hashtag results and the scraper will output a single scraping result for each of them (subject to your configured limits). |
| Global search page URL https://www.youtube.com/results?search_query=football https://www.youtube.com/results?search_query=football&sp=EgIQAQ | Enter one or more global YouTube search query URLs to identify a themed selection of content to be crawled. Search URLs may be copy/pasted directly from your browser and may optionally include filter parameters (which are generated automatically when you apply a filter condition via your browser). The crawler will extract target video IDs from the search results and the scraper will output a single scraping result for each of them (subject to your configured limits). |
📝 JSON Configuration Template
The following JSON data snippet represents YouTube Ultimate Scraper's default settings. You can use this as a template when creating your own advanced configuration. Simply delete the settings that are not relevant to your use case, then edit what remains to reflect your specific scraping requirements.