Gupy.io Scraper — Brazil Job Board
Pricing
from $1.19 / 1,000 results
Gupy.io Scraper — Brazil Job Board
Extract job listings from any Gupy.io company career page. No proxy, no API key. 64 fields per job including hiring pipeline stages, benefits, company social links and full structured address.
Pricing
from $1.19 / 1,000 results
Rating
0.0
(0)
Developer
Unfenced Group
Maintained by CommunityActor stats
1
Bookmarked
3
Total users
1
Monthly active users
23 days ago
Last modified
Categories
Share
Gupy Scraper — Brazil Job Board
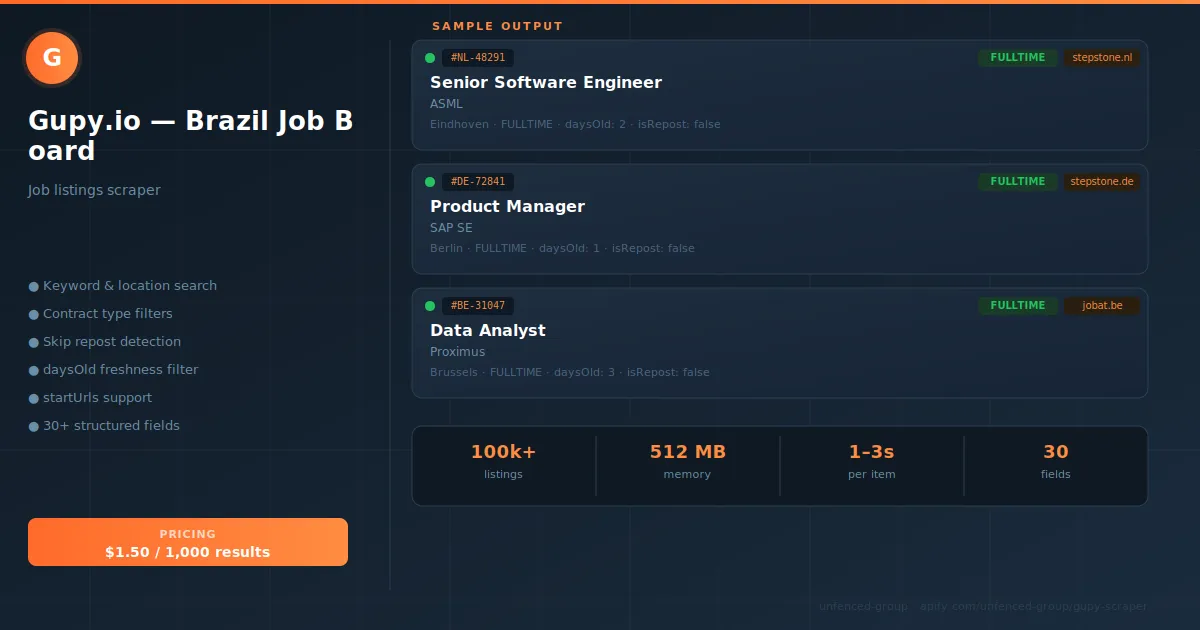
Extract job listings from any company career page on Gupy.io — Brazil's #1 HR and recruitment platform. No proxy, no browser, no API key required.
Why this scraper?
🚀 Complete data — 61 fields per job
Title, department, city, workplace type, full hiring pipeline stages, company social links, benefits, salary range, PCD/disability flag, video URLs and more.
⚡ Fast listing mode — no detail fetches
Toggle fetchDetails off to retrieve all jobs in a single request per company — ideal for monitoring job counts, filtering by location or department, and building pipelines that don't need full descriptions.
🌎 Multi-company in one run
Scrape Itaú, Ambev, Sicredi and any other Gupy-powered company simultaneously by listing their subdomains.
🔒 Zero bot detection
Public career pages, no authentication, no proxy required. Fully reliable for scheduled runs.
Input parameters
| Parameter | Type | Default | Description |
|---|---|---|---|
subdomains | string[] | — | Company subdomains to scrape, e.g. ["vempra", "ambev", "sicredi"]. Full URLs are also accepted. |
startUrls | RequestSource[] | — | Alternative: full Gupy career URLs, e.g. https://vempra.gupy.io. |
fetchDetails | boolean | true | When true, fetches each job's full detail page for description, prerequisites, responsibilities, benefits, salary, hiring pipeline, and all dates. When false, returns listing-level data only (faster and cheaper for large companies). |
maxJobsPerCompany | integer | 0 | Cap results per company. 0 = unlimited. |
requestDelay | integer | 200 | Mean delay in milliseconds between requests (Gaussian randomised). |
proxyConfiguration | Proxy | — | Optional. Not required for Gupy — leave empty. |
Output schema
Every field below is present on every record. Fields the source does not publish are returned as null rather than omitted.
| Field | Type | Description |
|---|---|---|
id | string | Unique ID from the source. |
title | string | Title as published. |
url | string | Direct link to the listing. |
applyUrl | string | Apply url. |
companyName | string | Hiring company name. |
companyId | string | Company id. |
subdomain | string | Subdomain. |
type | string | Type. |
department | string | Department. |
workplaceType | string | Workplace type. |
city | string | City. |
state | string | State. |
stateShortName | string | State short name. |
country | string | Country. |
quickApply | boolean | Quick apply. |
scrapedAt | string | Timestamp when this record was scraped. |
description | string | Full description in plain text. |
descriptionMarkdown | string | Description markdown. |
prerequisites | string | Prerequisites. |
responsibilities | string | Responsibilities. |
requirements | string | Requirements. |
skills | array | Skills. |
salary | string | Salary as displayed (null if not published). |
salaryRange | string | Salary range. |
publishedAt | string | Date published. |
expiresAt | string | Expires at. |
handicapped | boolean | Handicapped. |
isInternalMobility | boolean | Is internal mobility. |
jobType | string | Job type. |
videoUrl | string | Video url. |
Examples
Single company — full details
Large company — listing only (fast mode)
Multi-company run
Finding a company's subdomain
Visit the company's Gupy career page. The subdomain is the part before .gupy.io:
https://vempra.gupy.io→vemprahttps://ambev.gupy.io→ambevhttps://sicredi.gupy.io→sicredi
You can also paste the full URL directly in startUrls and the subdomain is extracted automatically.
Scheduled daily run:
Schedule this input in the Apify Scheduler (for example daily at 07:00) to keep an always-fresh dataset.
💰 Pricing
$1.49 per 1,000 results — you only pay for successfully retrieved listings. Failed retries are never charged.
| Results | Cost |
|---|---|
| 100 | ~$0.15 |
| 1,000 | ~$1.49 |
| 10,000 | ~$14.90 |
| 100,000 | ~$149.00 |
Flat-rate alternatives typically charge $29–$49/month regardless of usage. At 10,000 results/month, this scraper costs significantly less with no commitment.
Use the Max jobs per company cap to control your spend exactly.
Performance
| Company size | Jobs | Mode | Approx. time |
|---|---|---|---|
| Small (< 20 jobs) | 10 | fetchDetails: true | ~5 s |
| Medium (50 jobs) | 50 | fetchDetails: true | ~20 s |
| Large (300+ jobs) | 300 | fetchDetails: true | ~2 min |
| Large (300+ jobs) | 300 | fetchDetails: false | ~3 s |
Memory: 256 MB.
Known limitations
- Apply URL: Always points to the Gupy application form. Gupy does not expose external ATS redirect URLs.
- Salary: Not published by all employers — will be
nullwhen unavailable. Gupy does not require salary disclosure. - Company scope: Each run is scoped to the subdomains you provide. There is no built-in discovery of all companies on Gupy.
- Internal vacancies: Jobs with
publicationType: "internal"are visible when the career page is public. Internal-only pages (requiring login) cannot be scraped.
Technical details
- Source: gupy.io — Brazil's leading ATS and job board platform
- Memory: 256 MB
- Repost storage: KeyValueStore
gupy-scraper-job-dedup, 90-day TTL - Retry: Automatic retry on network errors, exponential backoff, 3 attempts per request
Additional services
Need a custom actor, additional filters, scheduled runs, or integration support?.nl](mailto:info@unfencedgroup.nl) — we build on request.
Related scrapers
Other scrapers in our Jobs — Americas collection:
Run it on a schedule
This actor is built for repeat use. Set it to run daily, weekly, or hourly, and the data keeps flowing without you touching it.
- Schedule runs — open the actor, go to Schedules, and pick a cadence. Each run only charges you for the results it returns.
- Connect it to your stack — push results straight to Google Sheets, Slack, a webhook, or your database using Apify Integrations. No glue code needed.
- Pull results via API — every run writes a clean dataset you can fetch with one API call, ready for whatever you build on top of it.
Set it once and it runs on its own.
Need a custom scraper?
Unfenced Group builds Apify actors for any website — for free.
If the site you need isn't in our portfolio yet, just ask. We scope, build, and publish it at no cost to you. You only pay for results — we absorb the compute and proxy costs ourselves. Same pay-per-result pricing, same quality, same standards as every actor in this portfolio.
Get in touch: www.unfencedgroup.nl