BooktoScrape.com
Pricing
from $0.01 / 1,000 results
BooktoScrape.com
This scraper extracts book information from books.toscrape.com, automatically crawling all pages and saving titles, prices, availability, and URLs to the Apify Dataset. Built with Apify SDK and PuppeteerCrawler for reliable cloud and local execution.
Pricing
from $0.01 / 1,000 results
Rating
0.0
(0)
Developer
Yugesh
Maintained by CommunityActor stats
0
Bookmarked
2
Total users
1
Monthly active users
8 months ago
Last modified
Categories
Share
Books.toscrape.com Scraper (Apify Actor)
This actor scrapes product data from https://books.toscrape.com, a public demo website designed for web-scraping practice. It extracts book title, price, availability, and product URL, and stores the results directly into the Apify Dataset.
This scraper is built using the Apify SDK, PuppeteerCrawler, Cheerio, and Axios, and is optimized to run in the Apify cloud environment.
Features
- Scrapes all paginated listing pages from books.toscrape.com
- Extracts:
- Title
- Price
- Availability text
- URL of the product page
- Streams results directly into Apify Dataset
- Automatically discovers and crawls next pages
- Works on both local environment and Apify cloud
- Uses Apify.main() for proper actor lifecycle handling
Project Structure
scraper.js - Main actor script package.json - Dependencies and start command actor.json - Actor metadata for Apify platform README.txt - Documentation (this file)
Local Setup
-
Install dependencies: npm install
-
Start the scraper: node scraper.js
-
Output will be written to the local Apify dataset folder: apify_storage/datasets/default/
Running on Apify Cloud
- Upload or push this project to your Apify actor.
- Build the actor.
- Run the actor.
- After completion, open the Dataset tab to download results as: JSON, JSONL, CSV, Excel, or XML.
How the Scraper Works
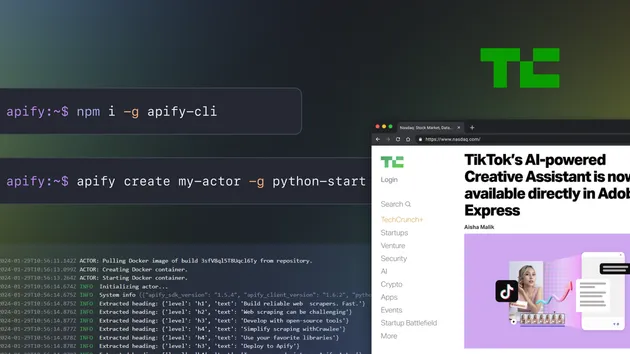
-
Starts at page: https://books.toscrape.com/catalogue/page-1.html
-
Parses each product block using Cheerio.
-
Pushes each record to the Apify Dataset using: Apify.pushData({ title, price, availability, url });
-
Detects and enqueues pagination links.
-
Continues until no more pages exist.
Output Example
{ "title": "A Light in the Attic", "price": "£51.77", "availability": "In stock", "url": "https://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html" }
Technologies Used
- Node.js
- Apify SDK
- PuppeteerCrawler
- Axios
- Cheerio
Configuration Notes
-
Adjust concurrency in scraper.js: maxConcurrency: 5
-
Increasing this value speeds up crawling but increases load.
-
A CheerioCrawler version can also be created if required.
Troubleshooting
-
Empty dataset: Parsing may have failed. Check logs.
-
"Module not found" on Apify: Add missing dependencies to package.json.
-
Actor finishes too quickly: Pagination may not be detected.