Compliance-Grade Web Intelligence for AI Agents
Pricing
from $2.00 / 1,000 reasoning packs
Compliance-Grade Web Intelligence for AI Agents
The scraper AI agents trust. Extract grounded facts with citations, entities, claims & RAG chunks. Built for LangChain, LlamaIndex, AutoGPT. Quality scoring, auto-citations, 6 task modes.
Pricing
from $2.00 / 1,000 reasoning packs
Rating
0.0
(0)
Developer
Jason Pellerin
Maintained by CommunityActor stats
0
Bookmarked
3
Total users
1
Monthly active users
6 months ago
Last modified
Categories
Share
The scraper that AI agents trust. Extract grounded facts with source citations, not hallucinated summaries.
🚨 Colorado SB 25B-004: AI Compliance Deadline June 30, 2026
Colorado Senate Bill 25B-004 establishes first-in-nation AI transparency and accountability requirements. Effective June 30, 2026, organizations deploying AI systems must:
- Document data sources used by AI agents
- Maintain audit trails for AI-generated decisions
- Provide source citations when AI systems use web-scraped data
- Enable human review of AI outputs with traceable provenance
This actor is purpose-built for SB 25B-004 compliance:
| Requirement | How This Actor Helps |
|---|---|
| Source Documentation | Every extraction includes sourceBlockId + exactQuote |
| Audit Trails | Full provenance object with timestamps, hashes, status codes |
| Citation Generation | Auto-generated APA, MLA, Chicago, and inline citations |
| Human Review | quality scores and summary enable efficient oversight |
| Change Monitoring | contentHash and materialityScore track source changes |
Denver-based businesses: Get ahead of compliance before June 30th. This actor creates the audit evidence your AI systems need.
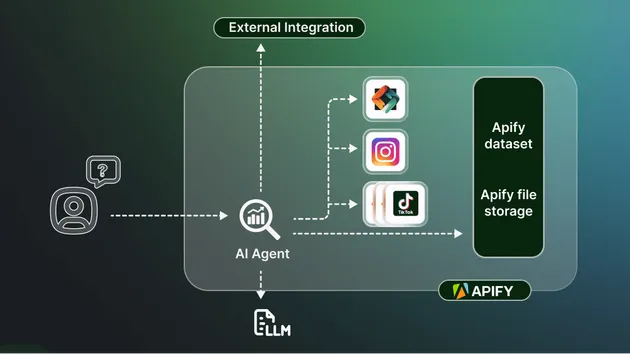
Why AI Agents Need This Scraper
Traditional scrapers return raw HTML or unstructured text. AI agents need grounded intelligence:
| Traditional Scraper | Compliance Web Intel |
|---|---|
| Raw HTML dump | Clean markdown + semantic blocks |
| No source tracking | Every fact has sourceBlockId + exact quote |
| Single output format | Reasoning Pack with 6 structured components |
| No change detection | Content hashing + materiality scoring |
| Hallucination-prone | Citation-ready extractions |
Built for: LangChain, LlamaIndex, AutoGPT, CrewAI, n8n AI nodes, custom RAG pipelines
What You Get: The Reasoning Pack
Every URL produces a Reasoning Pack - a structured bundle optimized for AI agent consumption:
Task Modes: Pre-configured for Common AI Workflows
1. competitor_teardown
Best for: Competitive intelligence agents, market research bots
Focuses on: pricing pages, features, about, testimonials, comparison pages
Output includes:
- Pricing tiers with features
- Marketing claims with citations
- Positioning statements
- Competitor differentiators
2. compliance_discovery
Best for: AI governance agents, policy monitoring bots, legal research
Focuses on: privacy policy, terms of service, legal notices, accessibility statements
Output includes:
- GDPR/CCPA compliance claims
- Data handling statements
- Legal disclaimers with exact quotes
- Policy change detection
3. local_seo_audit
Best for: Local SEO agents, citation building bots, GEO optimization
Focuses on: contact pages, about, locations, services, reviews
Output includes:
- NAP (Name, Address, Phone) extraction
- Schema.org markup detection
- Service area identification
- Business hours parsing
4. sales_research
Best for: Account research agents, sales enablement bots
Focuses on: about, team, leadership, news, press, careers, case studies
Output includes:
- Company signals (hiring, funding, expansion)
- Key personnel extraction
- Technology stack indicators
- Recent news with citations
5. docs_extraction
Best for: Documentation-to-API agents, knowledge base builders
Focuses on: docs, API references, guides, tutorials, help articles
Output includes:
- Structured procedure extraction
- Code example identification
- Parameter documentation
- Step-by-step instructions
6. pricing_intelligence
Best for: Price monitoring agents, market analysis bots
Focuses on: pricing pages, plans, packages, enterprise quotes
Output includes:
- Tier-by-tier pricing breakdown
- Feature comparisons
- Discount indicators
- Enterprise contact triggers
Integration Examples
LangChain RAG Pipeline
n8n Workflow Integration
Direct API Call
Why Grounded Extraction Matters for AI
The Hallucination Problem
When AI agents scrape websites and summarize content, they often:
- Misattribute statements
- Conflate information from multiple sources
- Generate plausible-sounding but incorrect facts
- Lose the ability to cite sources
The Grounded Solution
Every extraction in Compliance Web Intel includes:
Your AI agent can now:
- Cite sources: "According to [exactQuote] from [url]..."
- Verify claims: Cross-reference sourceBlockId with original content
- Audit decisions: Full provenance chain for compliance
Input Schema
| Parameter | Type | Default | Description |
|---|---|---|---|
startUrls | array | required | URLs to crawl (objects with url property) |
taskMode | string | general | Preset configuration for extraction focus |
maxPages | integer | 50 | Maximum pages to crawl per run |
maxDepth | integer | 3 | How deep to follow links |
includePatterns | array | [] | Only crawl URLs matching these regex patterns |
excludePatterns | array | [] | Skip URLs matching these regex patterns |
minRelevanceScore | number | 0.5 | URL relevance threshold (0-1) |
ragChunkSize | integer | 750 | Target tokens per RAG chunk |
diffBaseline | string | null | Previous run ID for change detection |
alertWebhook | string | null | Webhook for material change alerts |
proxyConfig | object | Apify Proxy | Proxy configuration |
Output Format
Full Reasoning Pack Example
Frequently Asked Questions
How is this different from Apify's Website Content Crawler?
Website Content Crawler returns raw content. Compliance Web Intel adds:
- Grounded extraction with source citations
- Semantic chunking optimized for RAG
- Entity/claim detection with confidence scores
- Schema.org detection and normalization
- Change monitoring with materiality scoring
Can I use this for monitoring competitor pricing?
Yes! Use taskMode: "pricing_intelligence" with diffBaseline set to a previous run ID. The actor will detect pricing changes and calculate a materialityScore. Set up an alertWebhook to get notified of significant changes.
How do RAG chunks work?
Chunks are created by:
- Grouping content by section (using headings as boundaries)
- Splitting on sentence boundaries
- Targeting 500-900 tokens per chunk
- Adding 50-token overlap between chunks
- Including full metadata (URL, section, block IDs)
What's the difference between facts and claims?
- Facts: Verifiable statements (statistics, definitions, processes)
- Claims: Subjective assertions (marketing claims, guarantees, testimonials)
Both include source citations for verification.
How do I handle JavaScript-rendered pages?
The actor uses Cheerio (static HTML) by default. For JS-heavy pages, the crawler will still extract what's available in the initial HTML. For fully dynamic SPAs, consider using Apify's Puppeteer/Playwright scrapers first, then processing the HTML through this actor.
Use Cases by Industry
SaaS / Technology
- Competitor feature tracking
- Pricing intelligence
- Documentation-to-API conversion
- Market positioning analysis
Legal / Compliance
- Privacy policy monitoring
- Terms of service change detection
- Regulatory compliance evidence
- AI governance audit trails
Marketing / SEO
- Content gap analysis
- Local SEO citation audits
- Competitive positioning research
- Schema markup validation
Sales / Business Development
- Account research automation
- Company signal detection
- Contact information extraction
- News and press monitoring
Research / Intelligence
- Due diligence automation
- Market research compilation
- Academic source collection
- Fact-checking support
Pricing
This actor uses Apify's standard compute unit pricing. Typical costs:
- 10 pages:
0.01 compute units ($0.005) - 100 pages:
0.1 compute units ($0.05) - 1000 pages:
1 compute unit ($0.50)
Actual costs depend on page complexity, proxy usage, and processing time.
Support & Feedback
- Issues: GitHub Issues
- Email: jason@jasonpellerin.com
- Apify Discord: @ai_solutionist
About the Author
AI Solutionist builds automation infrastructure for the AI-native enterprise. This actor embodies the HyperCognate philosophy:
Question assumptions. Obsess over detail. Plan like Da Vinci. Craft solutions that sing. Iterate relentlessly. Simplify ruthlessly.
Other actors by AI Solutionist:
Changelog
v1.0.0 (2026-01-28)
- Initial release
- 6 task modes for common AI workflows
- Grounded extraction with source citations
- RAG-ready chunking
- Schema.org detection
- Change monitoring infrastructure
License
MIT License - Use freely in commercial and open-source projects.
The scraper that AI agents trust. Because intelligence without provenance is just hallucination.