Actor Benchmark
Pricing
Pay per usage
Actor Benchmark
Compares various builds of the same actor to measure how they perform on the same input
Pricing
Pay per usage
Rating
0.0
(0)
Developer
Apify
Maintained by ApifyActor stats
1
Bookmarked
3
Total users
0
Monthly active users
2 months ago
Last modified
Categories
Share
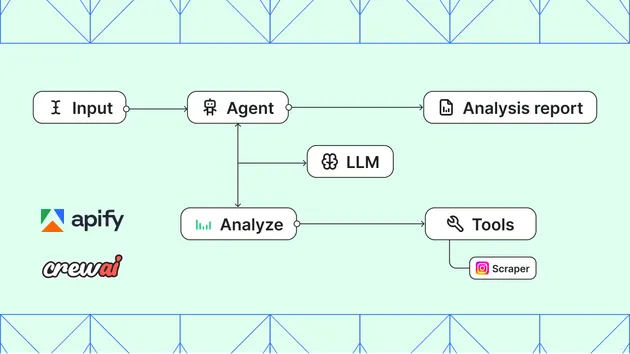
Benchmarks multiple builds of any Apify actor in parallel and compares their performance across key metrics: run duration, dataset item count, total cost, items per second, and cost per item.
Each build is run N times with the same input. Results are averaged per build to reduce the effect of outliers, then presented as a table and a set of bar charts.
How it works
- Dispatch — all runs (N builds × M runs each) are started in parallel as individual actor calls. A failure in one run does not abort the others.
- Re-fetch — once all runs finish, each run is re-fetched from the API to ensure stats are fully settled.
- Item count — the real item count is read from the Dataset API for each run's default dataset.
- Metrics — per-run metrics are computed and averaged per build. Failed runs are excluded from averages but still recorded for transparency.
- Output — averaged results are pushed to the default dataset, raw per-run rows to the
allRunsdataset, and five bar charts are saved to the key-value store.
Modes
The benchmark supports two mutually exclusive modes:
- Actor mode — provide
actorId+actorInput. Each run calls the actor with the given input. - Task mode — provide
taskIdonly. Each run calls the task using its own saved input on Apify.
If both are provided, actor mode takes priority and a warning is logged. If neither is provided, the actor exits with an error.
Input
| Field | Type | Required | Description |
|---|---|---|---|
buildNumbers | string[] | yes | List of build numbers or tags to compare (e.g. ["0.3.67", "canary"]) |
actorId | string | actor mode | ID or name of the actor to benchmark (e.g. apify/website-content-crawler) |
actorInput | object | actor mode | JSON input passed identically to every run |
taskId | string | task mode | ID or name of the Apify task to benchmark (e.g. my-username/my-task). The task's own saved input is used. |
runsPerBuild | integer | no | Number of runs per build, averaged together (default: 3, min: 1). All runs are started in parallel on your account — ensure you have enough memory quota available to allow them all to start simultaneously. |
maxRunDurationSecs | integer | no | Timeout in seconds for each run. If omitted, the actor's default timeout is used (min: 10, max: 36000) |
memoryMbytes | integer | no | Memory allocated to each run in MB. If omitted, the actor's default memory is used (min: 512, max: 32768) |
Output
Default dataset — averaged results
One row per build, with all numeric fields averaged across the successful runs of that build.
| Field | Description |
|---|---|
build | Build tag |
status | e.g. 3/3 SUCCEEDED or 2/3 SUCCEEDED |
durationSecs | Average wall-clock duration (seconds) |
itemCount | Average number of items in the output dataset |
totalCost | Average total run cost (USD) |
itemsPerSecond | Average throughput (items / second) |
costPerItem | Average cost per output item (USD) |
allRuns dataset — raw per-run data
One row per individual run, including failed runs. Same fields as above plus:
| Field | Description |
|---|---|
runNumber | 1-based index of the run within its build |
runId | Apify run ID |
Key-value store — charts
Five PNG bar charts comparing builds side by side, saved under these keys:
| Key | Metric |
|---|---|
chart-duration | Run Duration per Build (s) |
chart-items | Dataset Items per Build |
chart-total-cost | Total Cost per Build ($) |
chart-items-per-second | Items per Second per Build |
chart-cost-per-item | Cost per Item per Build ($) |
Error handling
- Single run fails to start — logged as a warning with the error from the orchestrator; remaining runs continue normally.
- Run finishes with non-SUCCEEDED status — logged as a warning with the run's status, exit code, and status message; the run is excluded from averaged metrics but still appears in the
allRunsdataset. - All runs fail — the actor exits with a non-zero exit code and no output is produced.