Canadiantire.ca Scraper 🍁 $1/1K Retail Product Data Extractor
Pricing
from $1.00 / 1,000 results
Canadiantire.ca Scraper 🍁 $1/1K Retail Product Data Extractor
Canadian Tire Scraper: Export Canada retail product listings & e-commerce data to CSV/JSON via Search URL. Extract market prices, inventory status, SKU, specs & deals across Canada. Built for competitor monitoring, retail price matching & fast B2B data extraction. 🚀 Proxy-optimized & fast!
Pricing
from $1.00 / 1,000 results
Rating
0.0
(0)
Developer
Azzouzana
Maintained by CommunityActor stats
2
Bookmarked
35
Total users
5
Monthly active users
4 days ago
Last modified
Categories
Share
Canadian Tire Products Scraper — Search, Categories & Product URLs
Features
Our Canadiantire scraper lets you extract products details from search results, from categories pages and from direct product URLs on Canadiantire.ca. It enables you to scrape rich products details as titles, descriptions, images, availabilities, ratings, prices, and all other available information.
The scraper has a requried startUrls parameter which is an array that should contain any combination of:
- Category page URL (plus a store) as input. It scrapes and returns category's products with their information. In terms of speed, this feature returns around 3.8K products/minute
- Search URL (plus a store) as input. It scrapes and returns search pages results products with their information. In terms of speed, this feature returns around 4K products/minute
- Direct product URL(s) (plus a store) as input. Since these are direct product URLs, the scraping speed is around 800 products/minute still fast but it's relatively slower than categories & search results pages scraping's speed.
Sample output:
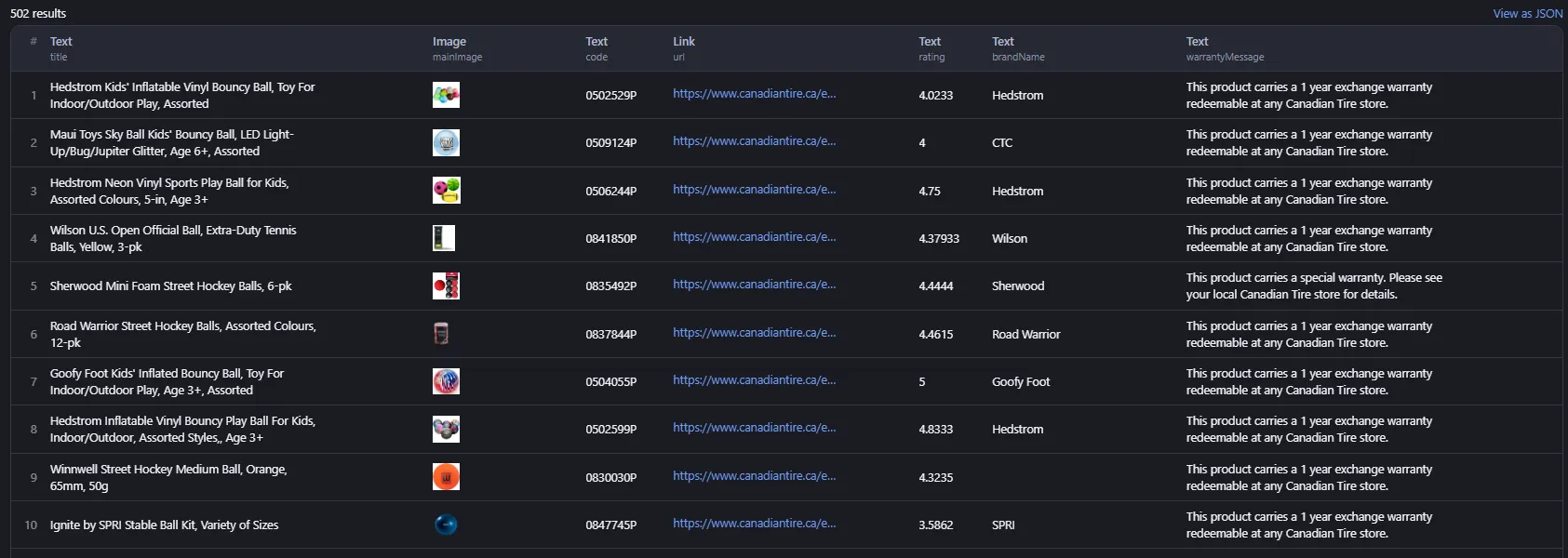
Is it legal to scrape Canadiantire?
It is legal to scrape publicly available data such as products descriptions, prices, or ratings. Read our blog post on the legality of web scraping to learn more.
Why scrape Canadiantire?
Canadiantire canada owns chains of 500+ retail stores, has millions of products in its database and has more than 25 million monthly unique visitors.
So what could you do with all that products listings data?
- Use the data to add value to your ecommerce/marketing business by providing extra information to your visitors.
- Marketing insights: You can use the data scraped to gather marketing insights, such as identifying popular products, trending items, and customer behavior.
- Price monitoring: Scraping can be used to track the prices of products, helping you to stay up-to-date with pricing trends and adjust your own pricing strategies.
- Improved customer experience: You can use the data scraped to identify customer preferences, enabling you to personalize your offerings and improve the overall customer experience.
- Train AI models to predict future trends and act fast when opportunities arise.
These are just some ideas to get you thinking about how web scraping can give you the data you need. Sky is the limit 🚀
Input
| Field | Type | Description | Default value |
|---|---|---|---|
| startUrls | array | the URLs that the scraper will scrape. For categories and search results pages, it will scrape products which show up there. For direct products URLs, it will scrape them one by one. | [{url: https://www.canadiantire.ca/en/search-results.html?q=shirts}] |
| store | number | The store ID against which to do the search load category's page or open product's page. To get this value, open the store locator page, search/find your store & click view store details. Grab the digits at the end of the url & paste it here. For example, you navigated to this store: https://www.canadiantire.ca/en/store-details/nl/carbonear-nl-217.html, you have to grab 217. | none |
| deepSearch | checkbox | Whether to scrape products data from the listing pages (catgeories/search results pages) or follow the products links and scrape their deep data. Please see below note about his field. | false |
| language | EN or FR | In which language to scrape results | en |
How to get startsUrls
-
To get search results page URL: open canadiantire's website, locate the search bar, type (choose your filter(s)), trigger the search & note the resulting url in the navigation bar. Make sure that it looks similar to
https://www.canadiantire.ca/en/search-results.html?...... -
To get category's page URL: access canadiantire's website and open a category's page then make sure to copy the address in the navigation bar. Make sure that it looks similar to
https://www.canadiantire.ca/en/cat/home-pets-DC0000001.html -
To get direct product URL: open canadiantire's website, open a product's page and copy the address in the navigation bar. Make sure that the url looks similar to
https://www.canadiantire.ca/en/cat/toys-sports-recreation/team-sports/soccer/soccer-balls-DC0002528.html
How to set the store ID?
The store parameter has to be specified either in the startUrls or in the store field. To specify the store ID in the url, please use this format ;store=123. If there's no store specified in a URL, the value specified in the seperate store parameter will be used.
If, an URL does not includes the store ID as specified previously, and when there's no global store ID parametr, the URL will be skipped.
Output
Output is stored in a dataset. Each item is information about a product.
⚠️ Note about deepSearch
Note that deepSearch parameter only makes sense when scraping categories and/or search results pages; if it's checked (true) then the scraper would open each product result item's page and scrape it, otherwise (the default) it will scrape product's information which are available in categries/search results pages, which in most cases (99%) sufffisant.
If the deepSearch attribute is checked, an example result may look like this.
If the deepSearch attribute is not checked, an example result may look like this.
Changelog
This Canadiantire scraper is at version 1.0.0.
It's actively maintained and regularly updated. The list of changes would be noted in this section upon scraper's updates.