PDF to Markdown Converter - AI-Powered with OCR & Tables
Pricing
Pay per event
PDF to Markdown Converter - AI-Powered with OCR & Tables
Convert PDFs to clean Markdown with GPU-accelerated AI. Extracts tables, LaTeX formulas, and images from complex layouts. Supports OCR for scanned docs in 8 languages. Batch process hundreds of PDFs in parallel via URL, upload, or API.
Pricing
Pay per event
Rating
0.0
(0)
Developer
ClearPath
Maintained by CommunityActor stats
1
Bookmarked
61
Total users
5
Monthly active users
4 months ago
Last modified
Categories
Share
PDF to Markdown
The most accurate PDF to Markdown converter on Apify — AI-powered with GPU acceleration for complex layouts, tables, formulas, and images.
Convert any PDF document into clean, structured Markdown with intelligent layout detection, OCR for scanned documents, and optional image extraction. Built for developers who need reliable PDF processing at scale.
- Complex layouts — Multi-column documents, academic papers, financial reports
- Table extraction — Preserves table structure in Markdown format
- Formula support — Mathematical equations converted to LaTeX
- Batch processing — Process hundreds of PDFs in parallel
- Multiple input methods — File upload, URLs, or base64 API calls
Copy to your AI assistant
Copy this block into ChatGPT, Claude, Cursor, or any LLM to start using this actor.
Demo
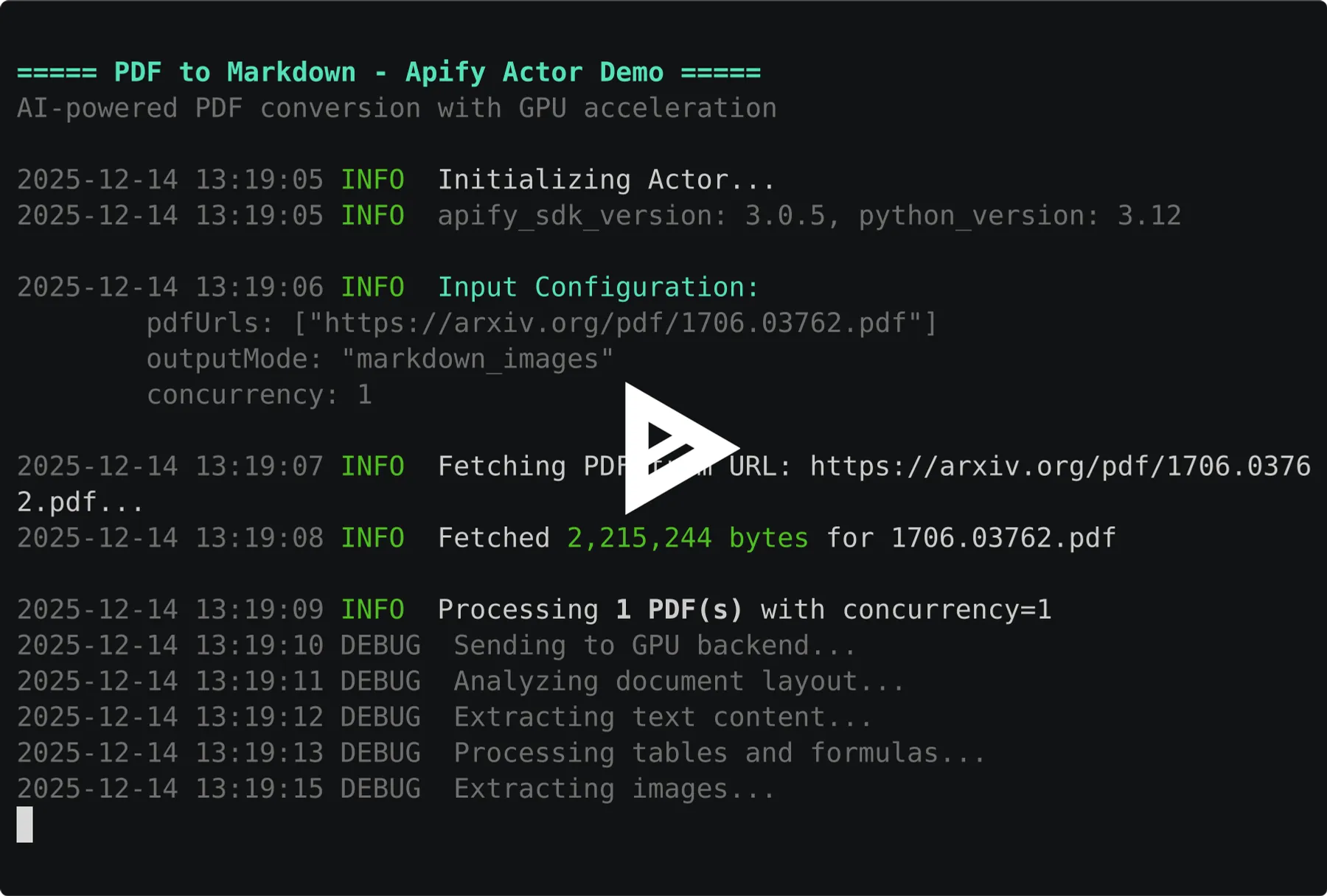
Key Features
Document Processing
- Intelligent layout detection — Handles single and multi-column layouts automatically
- Table recognition — Extracts tables with proper Markdown formatting
- Formula extraction — Converts mathematical formulas to LaTeX notation
- Image extraction — Optionally extract embedded images with public URLs
- OCR support — Process scanned PDFs with 8 language options
Developer-Friendly
- Batch processing — Submit multiple PDFs in a single run
- Parallel execution — Configurable concurrency (1-10 simultaneous PDFs)
- Three output modes — Choose between text-only, with images, or full extraction
- Structured output — Consistent JSON schema for easy integration
- Public image URLs — Images stored in Apify Key-Value Store, not base64 blobs
Reliability
- Automatic retries — Exponential backoff for transient failures
- Partial success — Continues processing if individual PDFs fail
- Detailed status — Per-document success/error reporting
- Processing metrics — Page count, markdown length, processing time
Use Cases
For RAG Pipeline Developers
- Prepare documents for LLM retrieval — Convert PDFs to clean text for embedding
- Build knowledge bases — Extract structured content from document libraries
- Enhance chatbot context — Feed processed documents into AI assistants
- Create searchable archives — Transform PDF collections into queryable text
For Data Engineers
- Document migration — Convert legacy PDF archives to Markdown
- Content pipelines — Automate PDF processing in data workflows
- ETL integration — Extract text data for downstream processing
- Compliance archival — Create text-based backups of PDF documents
For Researchers
- Extract tables from papers — Pull data tables from academic PDFs
- Process formulas — Convert mathematical notation to LaTeX
- Batch analysis — Process entire paper collections
- Figure extraction — Capture charts and diagrams with metadata
Quick Start
Basic — Single PDF URL
Advanced — Batch with Images
Complete — All Parameters
Pricing — Pay Per Event (PPE)
Usage-based pricing that scales with document complexity:
| Component | Price | Description |
|---|---|---|
| Base fee | $0.01/PDF | Charged once per successfully processed PDF |
| Per page | $0.005/page | Charged for each page in the document |
| Per image | $0.001/image | Charged for each extracted image (only in markdown_images and full modes) |
Cost Examples
| Document | Pages | Images | Calculation | Total |
|---|---|---|---|---|
| Simple report | 5 | 0 | $0.01 + (5 × $0.005) | $0.035 |
| Business doc | 20 | 5 | $0.01 + (20 × $0.005) + (5 × $0.001) | $0.115 |
| Research paper | 30 | 10 | $0.01 + (30 × $0.005) + (10 × $0.001) | $0.17 |
| Annual report | 100 | 30 | $0.01 + (100 × $0.005) + (30 × $0.001) | $0.54 |
| Large manual | 500 | 100 | $0.01 + (500 × $0.005) + (100 × $0.001) | $2.61 |
Batch Processing Examples
| Batch | Total Pages | Images | Total Cost |
|---|---|---|---|
| 10 PDFs × 10 pages | 100 | 0 | $0.60 |
| 50 PDFs × 20 pages | 1,000 | 0 | $5.50 |
| 100 PDFs × 15 pages | 1,500 | 200 | $8.70 |
Cost Optimization Tips
- Use
markdownmode if you don't need images — saves $0.001 per image - Filter PDFs before submission to avoid processing irrelevant documents
- Batch similar-sized documents for predictable costs
Input Parameters
| Parameter | Type | Default | Required | Description |
|---|---|---|---|---|
pdfFile | file upload | - | No* | Upload a single PDF file via the Apify UI |
pdfUrls | string[] | - | No* | Array of URLs pointing to PDF files |
pdfBase64Items | object[] | - | No* | Array of base64-encoded PDFs with filenames |
outputMode | enum | markdown | No | Output format: markdown, markdown_images, or full |
language | enum | en | No | Language hint for OCR accuracy |
concurrency | integer | 3 | No | Parallel processing (1-10) |
*At least one PDF source is required (pdfFile, pdfUrls, or pdfBase64Items).
Output Modes
| Mode | Markdown | Images | JSON Content | Best For |
|---|---|---|---|---|
markdown | Yes | No | No | Text extraction, RAG pipelines |
markdown_images | Yes | Yes (URLs) | No | Full document conversion |
full | Yes | Yes (URLs) | Yes | Analysis, debugging |
Supported Languages
| Code | Language |
|---|---|
en | English |
ch | Chinese (Simplified) |
chinese_cht | Chinese (Traditional) |
japan | Japanese |
korean | Korean |
ta | Tamil |
te | Telugu |
ka | Kannada |
Base64 Input Format
For API integration, use pdfBase64Items:
Output
Each PDF produces one dataset item with the following structure:
Output Fields
| Field | Type | Description |
|---|---|---|
filename | string | Original filename |
sourceType | string | Input source: url, upload, or base64 |
sourceUrl | string | Source URL (if applicable) |
status | string | success or error |
markdown | string | Extracted Markdown content |
pageCount | number | Number of pages in PDF |
markdownLength | number | Character count of markdown |
images | array | List of public URLs for extracted images |
imageCount | number | Number of extracted images |
jsonContent | object | Raw extraction metadata (full mode only) |
error | string | User-friendly error message (if failed) |
errorDetails | string | Additional error context |
processingTimeMs | number | Processing duration in milliseconds |
timestamp | string | ISO 8601 timestamp |
Error Output Example
API Integration
Python
JavaScript / TypeScript
cURL
Technical Requirements
| Requirement | Value |
|---|---|
| Memory | 512 MB |
| Processing Time | 20-45 seconds per PDF |
| Max Queue Wait | 2 minutes |
| Max Processing Time | 5 minutes per PDF |
| Concurrency | 1-10 parallel PDFs |
Supported PDF Types
- Standard text PDFs
- Scanned documents (via OCR)
- Multi-column layouts
- Tables and forms
- Academic papers with formulas
- Reports with charts and figures
Limitations
- Password-protected PDFs are not supported
- Maximum recommended file size: 50 MB per PDF
- Very complex layouts may have reduced accuracy
FAQ
What types of PDFs can this Actor process?
This Actor handles most PDF types including standard text documents, scanned images (via OCR), multi-column layouts, academic papers, financial reports, and documents with tables and formulas.
How long does processing take?
Most PDFs complete in 20-45 seconds. Complex documents with many pages or images may take longer. The Actor has a 5-minute timeout per PDF.
Can I process scanned documents?
Yes! The Actor includes OCR (Optical Character Recognition) that works with scanned PDFs. Use the language parameter to improve accuracy for non-English documents.
What languages are supported for OCR?
Eight languages: English, Chinese (Simplified and Traditional), Japanese, Korean, Tamil, Telugu, and Kannada.
How are images stored?
When using markdown_images or full mode, extracted images are stored in Apify's Key-Value Store. The output contains public URLs that remain accessible as long as your storage retention allows.
What happens if a PDF fails to process?
The Actor continues processing other PDFs and reports failures in the output. Each item has a status field (success or error) and an error field with a user-friendly message.
Can I process PDFs via API without uploading files?
Yes! Use the pdfBase64Items parameter to submit base64-encoded PDF content directly, or use pdfUrls to provide URLs that the Actor will fetch.
Is there a free trial?
Yes, Apify offers free platform credits for new users. You can test the Actor with sample PDFs before committing to paid usage.
How do I handle large batches efficiently?
Increase the concurrency parameter (up to 10) to process more PDFs in parallel. For very large batches, consider splitting into multiple runs.
What's the difference between output modes?
markdown: Text only, smallest output, fastestmarkdown_images: Text + image URLs, good for full document conversionfull: Everything including raw JSON metadata, best for analysis/debugging
Data Export
Export your results in multiple formats:
- JSON — Full structured data for programmatic access
- CSV — Spreadsheet-compatible format
- Excel — Direct import to Microsoft Excel
- XML — Legacy system integration
Automation
- Scheduled runs — Process PDFs on a recurring schedule
- Webhooks — Get notified when processing completes
- API integration — Trigger runs from your application
- Apify integrations — Connect with Zapier, Make, and more
Related Actors
Support
- Issues & Bugs: Use the ../../issues on this Actor's page
- Feature Requests: Open an issue or contact via email
- Email: max@mapa.slmail.me
- Response Time: Usually within 24 hours
Legal Compliance
This Actor processes documents that you provide. You are responsible for:
- Having the right to process the documents you submit
- Complying with applicable data protection regulations (GDPR, CCPA, etc.)
- Ensuring processed content doesn't violate any terms of service
The Actor does not store your PDFs beyond the processing duration.
Start Converting PDFs to Markdown Now
Transform your document workflows with accurate, AI-powered PDF extraction.