Reddit Subreddit Posts Scraper | Fast Bulk Feed Export
Pricing
from $1.99 / 1,000 posts
Reddit Subreddit Posts Scraper | Fast Bulk Feed Export
Scrape 1,000+ posts per subreddit in seconds. Hot, new, top, rising, controversial feeds with time filters. Optional comment fetching (up to 1,000 per post). Bulk subreddit input via names, URLs, or CSV.
Pricing
from $1.99 / 1,000 posts
Rating
0.0
(0)
Developer
ClearPath
Maintained by CommunityActor stats
1
Bookmarked
345
Total users
136
Monthly active users
a day ago
Last modified
Categories
Share
Reddit Subreddit Posts Scraper | Export Feed Data in Bulk (2026)
108 fields per post, 100 posts in ~1 second — scrape any subreddit feed with full metadata.
2026-07-27 — New createdAt / editedAt readable dates on every post (raw timestamps unchanged), and runs that return no posts now explain why.
Pick a subreddit, choose your sort order, and get back structured data for every post. Hot, new, top, rising, controversial. Optional comments. One subreddit or hundreds at once.
| Clearpath Reddit Suite • Search, analyze, and monitor Reddit at scale | |||
|
➤ You are here Subreddit Posts Feed scraper with 108 fields |
Full comment tree scraper |
Bulk profile & karma lookup |
Posts & comments history |
Copy to your AI assistant
Copy this block into ChatGPT, Claude, Cursor, or any LLM to start building with this data.
Key Features
- 108 fields per post — score, upvote ratio, flair, awards, media URLs, crosspost data, subreddit subscriber count, and 90+ more fields from the full Reddit feed response
- 5 sort orders — hot, new, top, rising, controversial. Add time filters (hour, day, week, month, year, all) for top and controversial sorts
- Optional comments — toggle on to fetch up to 1,000 top comments per post, with author, score, depth, and reply structure
- Bulk subreddit input — paste names, add URLs, or upload a CSV/TXT file. Mix formats freely:
AskReddit,r/AskReddit,reddit.com/r/AskReddit - Fast — posts-only mode scrapes 100 posts in roughly 1 second. Multiple subreddits run in parallel
How to Scrape Reddit Subreddit Posts
Single subreddit, default settings
Paste a subreddit name. The actor fetches up to 100 hot posts with all 108 fields.
All of these formats work interchangeably:
Top posts of the past week
Set sort to top and timeFilter to week to get the highest-scoring posts from the last 7 days.
Rising posts (catch trends early)
Rising surfaces posts that are gaining traction right now. Useful for monitoring subreddits for breaking content.
Posts with comments
Enable includeComments to fetch top comments for each post. Each post gets up to maxCommentsPerPost comments (default 1,000).
Comments are charged at $1.00 per 1,000.
Multiple subreddits in one run
Use the subreddits array for small batches. Mix any input format.
Subreddits run in parallel across multiple sessions, so adding more subreddits doesn't proportionally increase run time.
Bulk from file
Upload a .txt or .csv file through the Apify Console, or point to a hosted file URL. TXT files expect one subreddit per line. CSV files auto-detect a subreddit, sub, or name column.
Drag and drop a file directly into the "Subreddits file" field in the Apify Console for the fastest setup.
Controversial posts, all time
Find the most divisive posts ever submitted to a subreddit.
Input Parameters
| Parameter | Type | Default | Description |
|---|---|---|---|
subreddit | string | — | A single subreddit name or URL |
subreddits | string[] | [] | Multiple subreddit names or URLs. Use "Bulk edit" to paste a list |
subredditsFile | string | — | Upload a .txt/.csv file, or paste a URL to a hosted file |
sort | enum | hot | Sort order: hot, new, top, rising, controversial |
timeFilter | enum | all | Time range: hour, day, week, month, year, all. Only applies to top and controversial sorts |
maxPostsPerSubreddit | integer | 100 | Max posts to scrape per subreddit (1-1,000). Reddit limits feeds to ~1,000 posts |
includeComments | boolean | false | Fetch top comments for each post |
maxCommentsPerPost | integer | 1000 | Max comments per post when comments are enabled (1-1,000) |
At least one of subreddit, subreddits, or subredditsFile is required.
Sort order reference
| Value | Behavior |
|---|---|
hot | Reddit's default. Balances recency and engagement to surface currently active posts |
new | Most recent posts first, regardless of score |
top | Highest score (upvotes minus downvotes). Combine with timeFilter to control the time window |
rising | Posts gaining momentum right now. The feed is smaller but catches trends before they hit the front page |
controversial | Posts with roughly equal upvotes and downvotes. Combine with timeFilter for different windows |
Time filter reference
| Value | Window |
|---|---|
hour | Past 60 minutes |
day | Past 24 hours |
week | Past 7 days |
month | Past 30 days |
year | Past 365 days |
all | All time (default) |
Time filters only apply to top and controversial sort orders. They are ignored for hot, new, and rising.
What Data Can You Extract from Subreddit Posts?
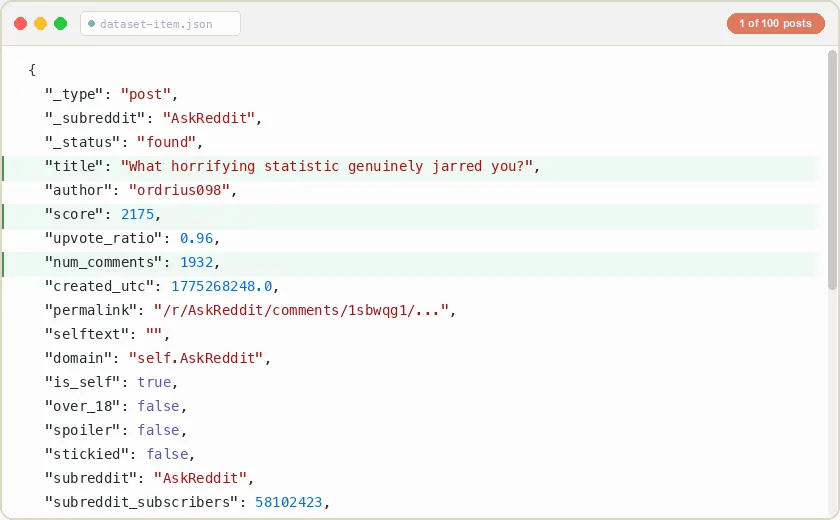
The output contains two row types: post rows and comment rows (when comments are enabled). Each post row contains 108 fields from the full Reddit feed response. The _subreddit field on every row lets you group results when scraping multiple subreddits. Both row types carry createdAt as an ISO 8601 UTC string, alongside the raw created_utc timestamp on post rows.
Post row (108 fields, key fields shown)
Every post includes the complete Reddit feed response. Beyond the key fields above, you also get:
Content and media:
selftext_html, thumbnail, thumbnail_height, thumbnail_width, preview (image resolutions), media (video/embed metadata), media_embed, secure_media, secure_media_embed, gallery_data, media_metadata, is_gallery, is_video, is_reddit_media_domain, post_hint
Scores and engagement:
score, ups, downs, upvote_ratio, num_comments, num_crossposts, total_awards_received, gilded, all_awardings, top_awarded_type, awarders
Author and flair:
author, author_fullname, author_flair_text, author_flair_css_class, author_flair_type, author_flair_template_id, author_flair_richtext, author_flair_background_color, author_flair_text_color, author_premium, author_patreon_flair
Post flair and categorization:
link_flair_text, link_flair_css_class, link_flair_type, link_flair_template_id, link_flair_richtext, link_flair_background_color, link_flair_text_color, category
Subreddit metadata:
subreddit, subreddit_id, subreddit_subscribers, subreddit_name_prefixed, subreddit_type
Moderation and status:
stickied, locked, removed_by_category, banned_by, approved_by, mod_reason_by, mod_reason_title, can_mod_post, distinguished
URLs and identifiers:
id, name, permalink, url, url_overridden_by_dest, domain, full_link
Flags:
over_18, spoiler, is_self, is_video, is_original_content, is_meta, is_crosspostable, is_robot_indexable, hide_score, archived, contest_mode, pinned, no_follow, send_replies
Comment row (when includeComments is enabled)
Comment fields:
| Field | Type | Description |
|---|---|---|
_type | string | Always "comment" |
_post_id | string | Parent post ID (t3_ prefixed), links this comment to its post |
_subreddit | string | Subreddit name |
_status | string | found |
id | string | Comment ID (t1_ prefixed) |
author | string | Username, or null for deleted comments |
score | integer | Upvotes minus downvotes |
createdAt | string | ISO 8601 creation timestamp |
editedAt | string/null | ISO 8601 edit timestamp, or null if never edited |
depth | integer | Nesting level. 0 = top-level reply, 1 = reply to a top-level, etc. |
parentId | string/null | Parent comment ID, or null for top-level comments |
permalink | string | Relative URL path to the comment |
body | string | Comment text in markdown |
isStickied | boolean | Pinned by a moderator |
isLocked | boolean | Replies disabled |
isScoreHidden | boolean | Score hidden by subreddit rules |
distinguishedAs | string/null | "moderator", "admin", or null |
authorFlair | string/null | User's flair text in the subreddit |
isDeleted | boolean | Deleted by author or removed by moderators |
childCount | integer | Number of direct replies |
authorId | string/null | Author account ID (t2_ prefixed) |
authorAccountType | string/null | Account type (e.g. USER) |
authorIsCakeDay | boolean | true on the author's account anniversary |
authorIcon | string/null | Author avatar URL |
languageCode | string/null | Detected language of the comment |
isArchived | boolean | true if the comment is archived |
isRemoved | boolean | true if removed by a moderator |
removedByCategory | string/null | Removal reason category, or null |
isCommercialCommunication | boolean | true if flagged as paid/commercial |
isInitiallyCollapsed | boolean | true if collapsed by default (e.g. low score) |
contentTypeHint | string/null | Body content format hint (e.g. RTJSON) |
Comments Add-on
Comments are optional and off by default. When you enable includeComments, the actor fetches the top comments for each post in a separate pass after collecting all posts.
How the pricing works
| Component | Cost |
|---|---|
| Posts | $1.99 per 1,000 posts |
| Comments | $1.00 per 1,000 comments |
Posts and comments are billed separately, and you pay only for the rows you receive. Comments are optional and off by default, so a posts-only run never incurs comment charges.
Cost examples
| Scenario | Posts | Comments | Estimated cost |
|---|---|---|---|
| 100 posts, no comments | 100 | 0 | ~$0.20 |
| 100 posts, 100 comments each | 100 | 10,000 | ~$0.20 + $10.00 = ~$10.20 |
| 50 posts, 500 comments each | 50 | 25,000 | ~$0.10 + $25.00 = ~$25.10 |
| 1,000 posts, no comments | 1,000 | 0 | ~$1.99 |
For large comment volumes, consider Reddit Post & Comments Scraper instead. It is built specifically for deep comment extraction with full tree expansion, six sort orders, and Q&A filtering.
When a Run Returns No Posts
An empty result is not always the same thing, so every run that returns nothing says why in its status message:
| Status message | What it means |
|---|---|
| No posts found. The subreddit may be empty, private, or may not exist. | Reddit answered, and there is genuinely nothing to return for this input. A trustworthy zero. |
| Couldn't reach Reddit. Please try again in a few minutes. | One or more subreddits could not be loaded at all. Retry. |
| Found N posts, but part of the run could not be completed. | Some subreddits delivered, others were cut short. Raise the run timeout to get the rest. |
| The run ended before all of the input was processed. | The run hit its timeout before every subreddit was checked. Raise the run timeout and try again. |
A successful run that returned everything sets no status message.
Pricing — Pay Per Event (PPE)
| $1.99 per 1,000 posts • $1.00 per 1,000 comments |
You pay only for what you scrape. Posts and comments are charged separately.
Budget controls: Set a spending limit on any run from the Apify Console. The actor stops automatically when the budget is reached, and you keep all data scraped up to that point.
Use Cases
Subreddit monitoring. Track a subreddit's front page over time. Schedule daily runs with sort: "hot" to capture what's trending. Compare scores, comment counts, and upvote ratios across snapshots to detect shifts in community interest. Export to Google Sheets via Apify integrations for automatic dashboards.
Trend detection. Use sort: "rising" to catch posts gaining traction before they hit the front page. Rising surfaces content early in its lifecycle, giving you a head start on breaking topics, viral content, and emerging discussions. Ideal for brand monitoring, news tracking, and competitive research.
Content research. Pull top posts from niche subreddits to understand what resonates with specific audiences. The upvote_ratio field tells you how divisive a topic is: 0.95+ means near-universal agreement, while 0.50-0.60 indicates a split community. Flair data reveals the content categories a community values most. Combine with time filters to study seasonal patterns.
Dataset building. Export structured subreddit data for analysis, machine learning, or data journalism. The 108 fields per post give you more metadata than most Reddit datasets, including media URLs, crosspost chains, award breakdowns, and author flair. Download as JSON, CSV, or Excel from the Apify Console, or pipe directly into your data pipeline via the Apify API.
Competitor analysis. Scrape brand-related subreddits to see what customers discuss, complain about, and recommend. Compare engagement metrics across multiple subreddits in a single run. The num_comments and upvote_ratio fields are strong signals for how much discussion a topic generates and whether the sentiment skews positive or negative.
Academic research. Study posting patterns, community dynamics, and content virality. The created_utc timestamp combined with score data lets you analyze how posts perform over different time windows. Crosspost fields reveal how content spreads between communities. Schedule recurring runs to build longitudinal datasets.
Lead generation. Monitor subreddits where your target audience asks for recommendations. Posts in subreddits like r/SaaS, r/Entrepreneur, or r/freelance often contain explicit purchase intent. Export the data and filter by flair or keywords to find high-intent threads.
SEO and content strategy. Analyze which topics generate the most engagement in your industry's subreddits. Use sort: "top" with timeFilter: "month" to find the highest-performing content themes. The title and selftext fields combined with engagement metrics reveal what your audience cares about most.
FAQ
How many fields do I get per post? 108 fields per post. This includes everything Reddit returns in its feed response: scores, ratios, flair, awards, media metadata, crosspost data, moderation flags, and subreddit information. You get the complete raw data, not a subset.
What's the maximum number of posts I can scrape?
Up to 1,000 posts per subreddit per run. This is a Reddit limitation, not an actor limitation. For most subreddits, the new sort provides the best coverage since it returns posts chronologically. Schedule recurring runs if you need ongoing coverage beyond 1,000 posts.
How fast is it? Posts-only mode scrapes 100 posts in roughly 1 second. Adding comments increases run time proportionally. Multiple subreddits run in parallel across sessions, so scraping 10 subreddits takes about the same time as scraping 2.
What happens if a subreddit doesn't exist?
Non-existent and private subreddits are included in the output with "_status": "not_found". You are not charged for failed subreddits.
What subreddit formats are accepted?
Plain name (AskReddit), prefixed (r/AskReddit), full URL (https://reddit.com/r/AskReddit), old/new/mobile URLs, and any combination of these in the same run. The actor normalizes all inputs before processing.
When should I use time filters?
Time filters apply only to top and controversial sort orders. For example, sort: "top" with timeFilter: "week" returns the highest-scoring posts from the past 7 days. The filters are ignored for hot, new, and rising.
How do comments work?
When includeComments is enabled, the actor fetches the top comments for each scraped post. Comments are sorted by confidence (Reddit's "best" algorithm). You can set maxCommentsPerPost from 1 to 1,000. Comments appear as separate rows in the output, linked to their parent post by _post_id.
How much do comments cost? Comments are billed at $1.00 per 1,000 ($0.001 each), separate from posts. They are optional and off by default, so a posts-only run incurs no comment charges.
What's the difference between this and the Post & Comments Scraper? This actor starts from a subreddit feed and gives you posts with optional comments. The Post & Comments Scraper starts from specific post URLs and specializes in deep comment extraction: full tree expansion, six sort orders, Q&A filtering, unlimited comments. Use this actor when you want to scrape a subreddit's feed. Use the other when you already have post URLs and need complete comment trees.
Can I schedule recurring runs?
Yes. Set up a schedule in the Apify Console to run the actor daily, hourly, or at any interval. Combine with sort: "new" to build a continuous feed archive.
Can I use this with the Apify API or integrations? Yes. Call the actor via the Apify API, schedule recurring runs, or connect to integrations like webhooks, Zapier, Make, or Google Sheets. The output is standard JSON that works with any downstream pipeline.
What output formats are available? The Apify Console lets you download results as JSON, CSV, Excel, XML, or RSS. You can also access the dataset directly via the Apify API in any of these formats. CSV and Excel flatten nested fields automatically, so media metadata and award arrays become readable columns.
How do I scrape NSFW subreddits?
NSFW subreddits work the same as any other subreddit. Posts from NSFW communities include "over_18": true in the output, so you can filter them in your downstream pipeline if needed.
Does it work with private or quarantined subreddits?
Private subreddits return a "_status": "not_found" row since their content is not publicly accessible. Quarantined subreddits may return partial or no results depending on their access restrictions. You are not charged for subreddits that fail to load.
More Clearpath scrapers for Reddit
🔍 Search & discovery
 Reddit Search Scraper
Reddit Search Scraper
Keyword search across all of Reddit
💬 Threads & comments
 Reddit Post Comments Scraper
Reddit Post Comments Scraper
Full comment trees and nested replies from any post URL
👤 Users
 Reddit Profile Scraper
Reddit Profile Scraper
Bulk username, karma, and account lookup Reddit User Posts & Comments Scraper
Reddit User Posts & Comments Scraper
A single user's full post and comment history
🤖 AI & LLM tools
 Reddit MCP Server
Reddit MCP Server
Live Reddit search inside your AI assistant Reddit Answers API
Reddit Answers API
Reddit's AI answer engine for any question Reddit to LLM
Reddit to LLM
Clean Reddit threads as Markdown for AI pipelines
Support
- Bugs: Issues tab
- Features: Email or issues
- Email: max@mapa.slmail.me
Legal Compliance
Extracts publicly available data. Users must comply with Reddit terms and data protection regulations (GDPR, CCPA).
Bulk subreddit feed scraping. 108 fields per post, 5 sort orders, optional comments, from one subreddit or hundreds.