Tech Stack & Hiring Signal Enricher
Pricing
from $3.60 / 1,000 company-signal-results
Tech Stack & Hiring Signal Enricher
Enrich company domains with public website technology signals (CMS, ecommerce, analytics, CRM, frontend, hosting/CDN) plus current hiring signals from public careers pages - no login, cookies, or paid APIs.
Pricing
from $3.60 / 1,000 company-signal-results
Rating
0.0
(0)
Developer
Delowar Munna
Maintained by CommunityActor stats
0
Bookmarked
2
Total users
1
Monthly active users
a month ago
Last modified
Categories
Share

Turn a list of company domains into one flat, CSV-ready row per company showing what technologies the website appears to use (CMS, ecommerce, analytics, CRM/marketing, frontend, hosting/CDN) and whether the company is actively hiring (careers page, public job board, open-role estimate, hiring departments). Every row carries a transparent, explainable growth-signal score. Built for B2B sales, lead generation, agencies, tech recruiters, and market researchers.
No login, no cookies, no paid enrichment APIs. The actor fetches each company's public homepage plus a small, cost-bounded set of public careers pages over HTTP and runs a local technology-signature dictionary. You pay one flat event per unique company row that passes your filters.
✨ Why this enricher
- Two commercial signals in one row — detected website technologies plus current hiring activity, without expensive contact enrichment or deep crawling.
- Flat & CSV-friendly — 32 flat fields, no nested objects. Drops straight into Sheets/Excel/CRMs.
- Transparent non-AI scoring — a deterministic 0–100 growth-signal score with
reason_tagsexplaining exactly why. - Cost-safe by design — homepage + up to
maxJobPagesPerCompanycareers probes only. No website crawling, no media downloads, no residential proxy. - Pay-Per-Event — one flat
company-signal-resultevent per saved unique company. Duplicates, filtered rows, and unreachable companies are never charged.
🚀 Quick start — sample inputs
Example 1 — companies + target technologies + hiring keywords
Example 2 — pasted domain list, tech-only enrichment, custom residential proxy via your own provider
Provide at least one of
companyUrlsorcompanyDomainsText. If you provide both, they are merged and deduplicated by domain.
The actor blocks Apify Residential proxy; if you need residential routing, supply your own provider via
proxyConfiguration.proxyUrlsas shown. See 🚦 Proxy policy below.
📦 Output
The dataset has one view: Tech stack & hiring signals — a 32-column flat table.
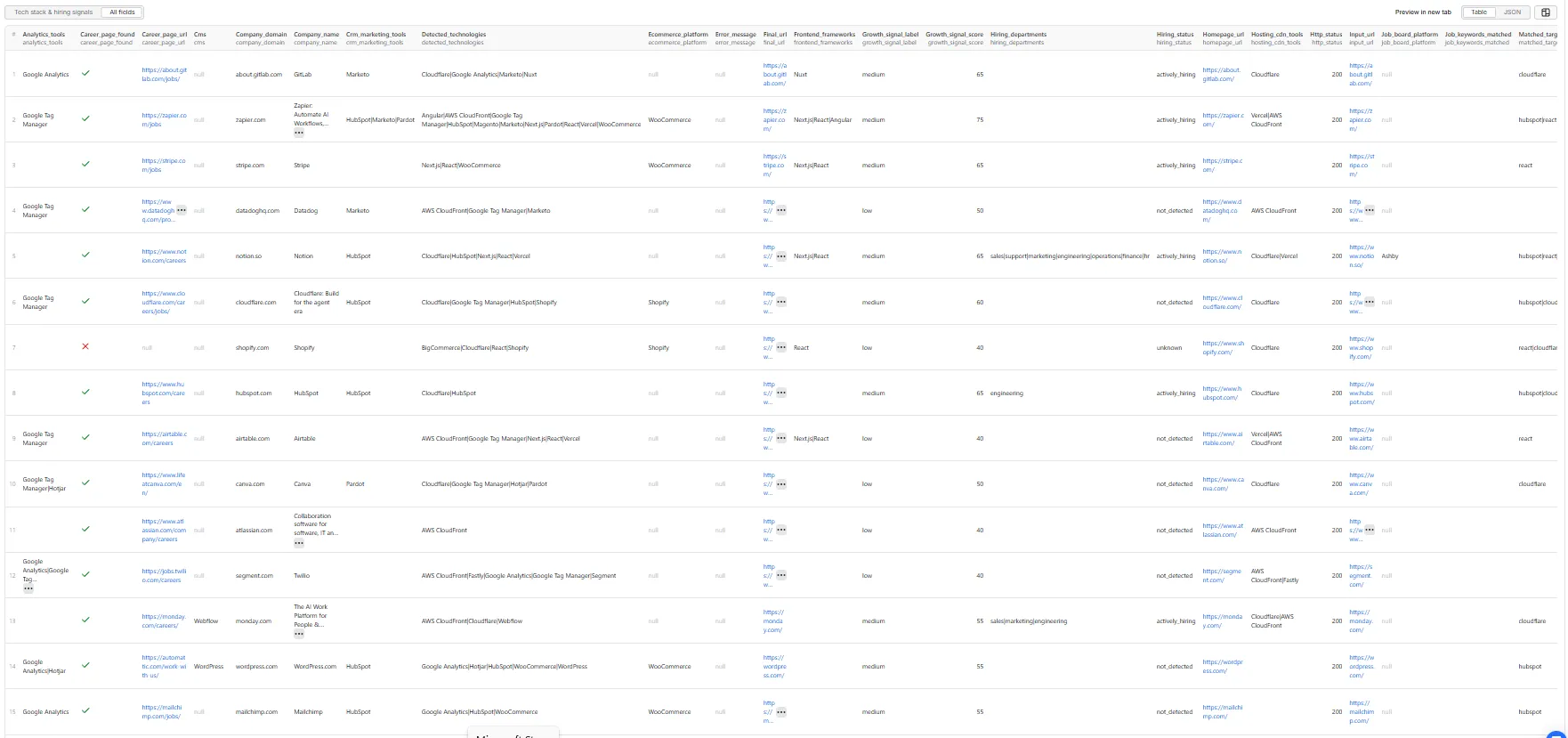
Output fields (32)
Identity & status: input_url, company_domain, homepage_url, company_name, page_title, http_status, final_url, source_pages_checked, status, error_message, scraped_at
Technology: tech_detected_count, detected_technologies, technology_categories, matched_target_technologies, cms, ecommerce_platform, analytics_tools, crm_marketing_tools, frontend_frameworks, hosting_cdn_tools
Hiring: career_page_found, career_page_url, job_board_platform, hiring_status, open_roles_estimate, job_keywords_matched, hiring_departments, top_job_titles_sample
Scoring: growth_signal_score, growth_signal_label, reason_tags
Multi-value fields are pipe-separated (HubSpot|React).
Sample record — Tech stack & hiring signals
A real row from a live run (Figma — tech detected, a matched target technology, a public job board, and active hiring with departments and sample titles):
🧠 What gets detected
Detection uses a small, high-value local signature dictionary — HTTP headers, <script> src URLs, <meta generator>, and HTML markers. No paid API, no external lookup.
| Category | Technologies (V1) |
|---|---|
| CMS | WordPress, Webflow, Drupal, Squarespace, Wix |
| Ecommerce | Shopify, WooCommerce, BigCommerce, Magento |
| Analytics | Google Analytics, Google Tag Manager, Segment, Hotjar |
| CRM/marketing | HubSpot, Marketo, Intercom, Drift, Salesforce, Pardot |
| Frontend | React, Next.js, Vue, Nuxt, Angular, Svelte |
| Hosting/CDN | Cloudflare, Vercel, Netlify, AWS CloudFront, Fastly |
| Job boards | Greenhouse, Lever, Workable, Ashby, SmartRecruiters, BambooHR |
🎯 Growth-signal score
Transparent rule-based score (0–100) computed only from visible scraped fields — no AI.
| Signal group | Points | Detail |
|---|---|---|
| Technology signal | ≤ 35 | +10 any tech · +10 CRM/marketing · +10 ecommerce · +5 frontend/hosting |
| Target technology match | ≤ 20 | +20 all targets match (all mode) · +15 ≥1 match (any mode) |
| Hiring signal | ≤ 30 | +10 career page · +15 actively hiring · +5 job-keyword match |
| Data confidence | ≤ 15 | +10 homepage 2xx · +5 company name detected |
Score is capped at 100. Labels: high (80–100) · medium (55–79) · low (30–54) · weak (0–29).
reason_tags is a pipe-separated list explaining the score — e.g. tech_detected, uses_hubspot, uses_react, career_page_found, actively_hiring, hiring_engineering, matches_target_technology, matches_job_keyword, homepage_reachable.
⚙️ Filters
Filters apply after extraction and scoring, before any row is saved or charged.
| Filter | Effect |
|---|---|
targetTechnologies + technologyFilterMode | any keeps ≥1 match · all keeps full match · off disables. Empty target list = off. |
hiringStatusFilter | actively_hiring / not_detected / any. |
minSignalScore | Keep only growth_signal_score >= minSignalScore. |
includeNoTechDetected | When false, drop companies with tech_detected_count = 0. |
deduplicateResults | Drop duplicate companies by normalized domain (recommended ON). |
💰 Pricing
Pay-Per-Event. One flat event per saved row (final per-event price is configured on the Apify console):
| Event | Charged when |
|---|---|
company-signal-result | Once per unique company row that passed all filters and was successfully written to the dataset. |
So your bill is simply results_saved × price_per_event. The actor honors the user-configured per-run spending cap: it caps how many companies it processes up-front to what the limit can pay for, and stops cleanly when the cap is reached during charging.
Not charged: duplicates, filtered-out rows, and unreachable companies.
🚦 Proxy policy
Use Apify Datacenter proxy or no proxy for normal runs — both work for public company websites at this actor's conservative concurrency.
Apify Residential proxy is not supported. The actor will fail at startup if proxyConfiguration.apifyProxyGroups includes RESIDENTIAL. Reason: in pay-per-event actors, residential bandwidth (~/GB) is billed to the developer, not the run user, so a single bandwidth-heavy run could exceed the per-result event revenue.
If you genuinely need residential routing, supply your own residential provider via the proxy editor's Custom proxy URLs field — that traffic goes through your provider, not Apify:
📊 Run summary
After each run, a RUN_SUMMARY entry is written to the key-value store:
charged_events equals the number of successfully saved unique rows.
🚧 Limitations (V1)
- Public data only: homepage + a few public careers pages. No login, cookies, or deep crawling.
- Lightweight detection: a curated V1 signature dictionary, not a full BuiltWith-level history. It favors precision on common, high-value technologies.
- Hiring discovery is shallow: it inspects homepage careers links and probes up to
maxJobPagesPerCompanylikely paths. Some sites render job lists via JavaScript or gate them behind an applicant flow; those returncareer_page_foundwithout a reliable role count. - No contact/email extraction, people finding, screenshots, or AI scoring (by design).
- Partial rows are saved when the homepage is reachable but one enrichment branch fails.
❓ FAQ
Do I need any login or cookies? No. The actor only fetches public homepages and public careers pages.
How is hiring_status decided?
actively_hiring when a careers page is found with visible open roles; not_detected when a careers page is found but no roles are visible; unknown when no careers page is found (or hiring discovery is off).
Why is a technology missing? Detection is signature-based on the homepage only. Tools loaded lazily, server-side, or behind consent banners may not appear. The dictionary is intentionally small and high-precision in V1.
Can I export to CSV?
Yes — every field is flat. Use Apify's CSV/Excel export or the dataset API with format=csv.
🛠️ Technical notes
- Stack: Node.js 22 · Apify SDK 3 · Crawlee
CheerioCrawler· Cheerio + native fetch. No browser. - Per company: 1 homepage request + up to
maxJobPagesPerCompanycareers probes. - Concurrency:
min=1,max=10(conservative; tune after real runs). - Memory: 1 GB min · 2 GB default · 4 GB max.
- Proxy: Apify Proxy enabled by default; custom configs accepted; Apify Residential rejected at startup.