Hiring Signal Company Enricher
Pricing
from $2.40 / 1,000 company-signal-results
Hiring Signal Company Enricher
Enrich company domains, websites, or names with public hiring signals - open role counts, hiring departments, locations, remote/hybrid indicators, sample jobs, and a transparent growth signal score. No login or cookies.
Pricing
from $2.40 / 1,000 company-signal-results
Rating
0.0
(0)
Developer
Delowar Munna
Maintained by CommunityActor stats
0
Bookmarked
3
Total users
2
Monthly active users
a month ago
Last modified
Categories
Share
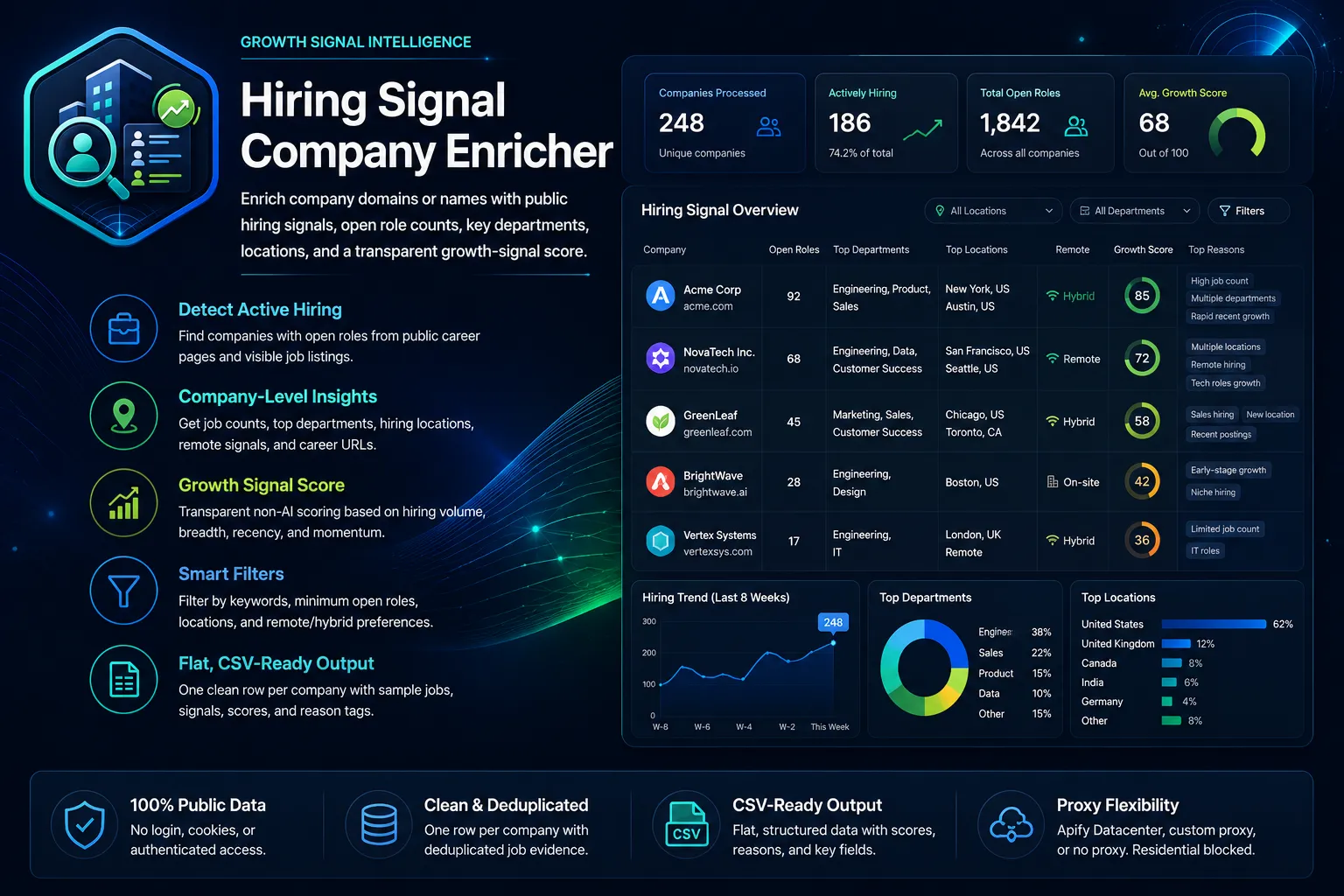
Enrich a list of companies — by domain, website URL, career-page URL, or plain name — with public hiring signals. For each company you get one flat, CSV-ready row: open-role count, hiring departments, locations, remote/hybrid indicators, sample jobs, and a transparent growth-signal score (0–100).
Built for B2B sales, lead generation, recruiters, agencies, and market researchers who want company-level hiring intelligence without scraping raw job boards or merging several actors.
- ✅ No login, no cookies, no API keys. Public data only.
- ✅ One row per company, not a raw job dump.
- ✅ Transparent, non-AI scoring you can audit field-by-field.
- ✅ Reliable extraction via public ATS JSON APIs (Greenhouse, Lever, Ashby, SmartRecruiters, Recruitee, Workable), with careers-page HTML as a fallback.
What it does
For every company input the actor:
- Normalizes the input and detects its type (domain, URL, career URL, or company name).
- Discovers the best public source — a careers page or a public ATS job board — honouring your
sourceMode. - Extracts visible open roles (public ATS JSON first, careers-page HTML fallback), up to
maxJobsPerCompany. - Derives company-level signals: role count, top departments, top locations, remote/hybrid counts, target-keyword matches, sample jobs.
- Scores a transparent
growth_signal_scoreand emits one flat row.
It does not do login/session scraping, contact or email enrichment, deep crawling, AI summaries, or historical tracking.
Input
| Field | Type | Default | Description |
|---|---|---|---|
companies | array of strings | [] | Company names, domains, website URLs, or career-page URLs. At least one required. Max 1,000. |
inputType | string | auto | auto, domain_or_url, company_name, or career_url. |
maxCompanies | integer | 100 | Max unique companies to process (1–1000). |
maxJobsPerCompany | integer | 50 | Cap on job evidence collected per company (1–200). |
sourceMode | string | public_website_first | public_website_first, search_first, or career_url_only. |
targetKeywords | array of strings | [] | Title/department terms to score and filter on (max 50). |
requireKeywordMatch | boolean | false | Save only companies with a matching visible job. |
minOpenRoles | integer | 0 | Skip companies with fewer visible open roles (0–200). |
includeSampleJobs | boolean | true | Populate up to 5 sample job titles/URLs. |
deduplicate | boolean | true | One row per normalized company. |
proxyConfiguration | object | { "useApifyProxy": true } | Datacenter, no proxy, or custom proxy URLs. Apify Residential rejected at startup. |
Example inputs
1. Enrich a mixed list (websites, names, ATS boards) and score them
2. Build a sales-trigger list — only companies actively hiring for your keywords
3. Minimal run — just give it companies
Output
One flat row per enriched company. Key fields:
- Identity:
input_value,input_type_detected,company_name,company_domain,company_website_url,careers_url,source_url,source_type - Hiring signals:
hiring_status,open_roles_count,open_roles_count_capped,top_departments,top_locations,remote_roles_count,hybrid_roles_count - Keyword matching:
target_keyword_matches,matched_keywords - Sample jobs:
sample_job_title_1..5,sample_job_url_1..5 - Scoring:
growth_signal_score(0–100),growth_signal_label(high/medium/low/none/unknown),reason_tags - Status:
extraction_status,error_message,scraped_at
Company hiring signals (table view)
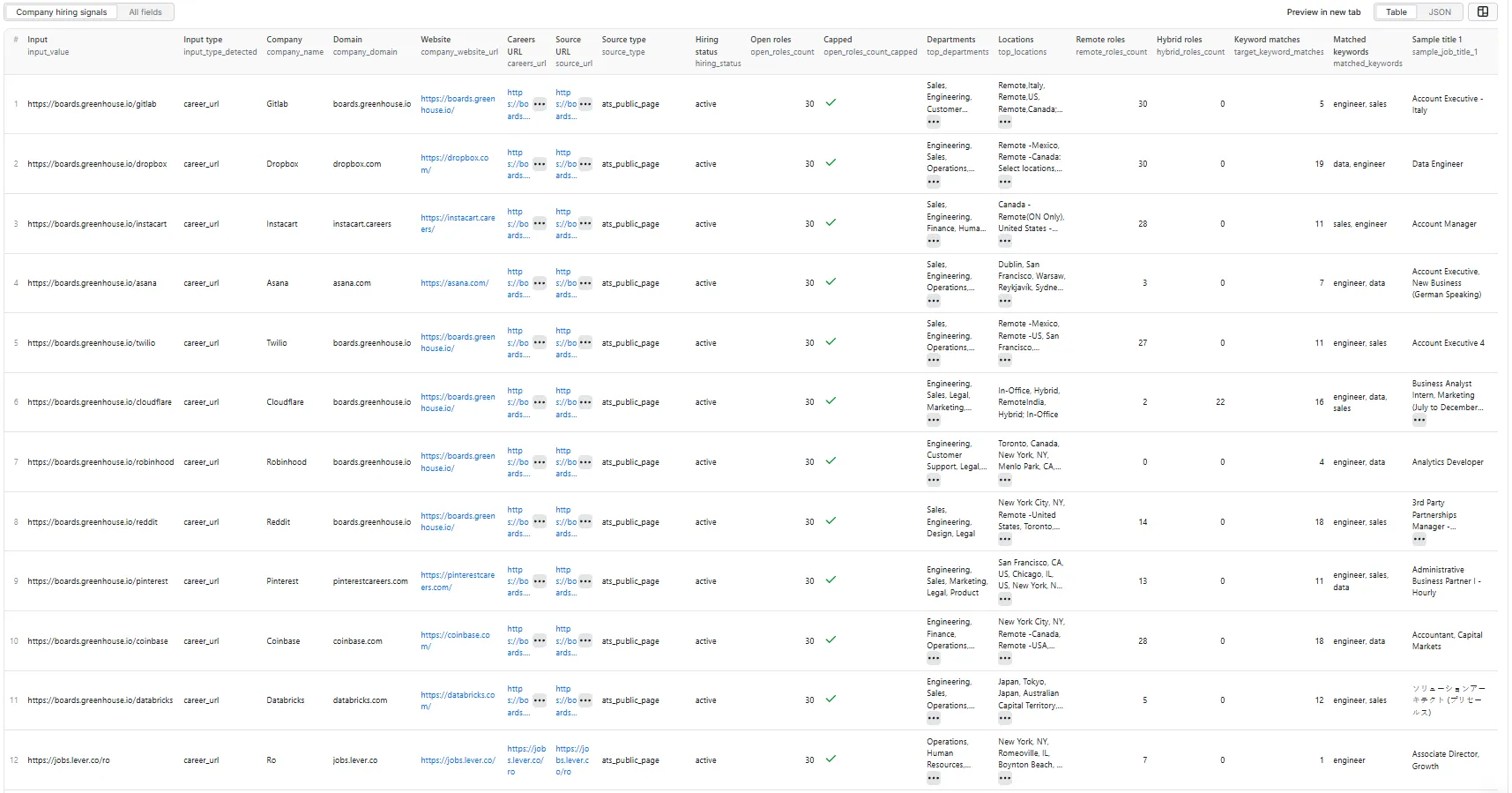
Sample record
One flat row per company. Example record (real output for https://boards.greenhouse.io/dropbox):
A run summary is stored in the default key-value store under RUN_SUMMARY with counters such as inputs_total, results_saved, duplicates_removed, filtered_out, charged_events, and companies_with_active_hiring.
Growth-signal score
A transparent 0–100 weighted sum (see PRD §7), based only on visible public fields:
- Open-role volume bands (
+40 / +30 / +20 / +10) +15for ≥3 hiring departments+10for ≥2 hiring locations+10for any remote/hybrid role+15 / +8for target-keyword matches+5for a dedicated careers URL
Labels: 80–100 high, 50–79 medium, 20–49 low, 1–19 none, 0 (uncertain) unknown.
Pricing
Pay Per Event. One event, company-signal-result, is charged only after a valid, unique company row is successfully pushed to the dataset. Duplicate companies, filtered-out companies, failed inputs, and raw job evidence are never charged. The actor honours your per-run spending limit and stops cleanly when it is reached.
🚦 Proxy policy
Use Apify Datacenter proxy or no proxy for normal runs — both work reliably for company websites and public ATS APIs at this actor's conservative concurrency.
Apify Residential proxy is not supported. The actor fails at startup if apifyProxyGroups includes RESIDENTIAL. Reason: in pay-per-event actors, residential bandwidth (~$8/GB) is billed to the developer, not the run user, so a single bandwidth-heavy run could exceed the per-result event revenue.
If you genuinely need residential routing, supply your own residential provider via the proxy editor's Custom proxy URLs field — that traffic goes through your provider, not Apify, and is unaffected:
How sources are found
For each company the actor tries, in order of reliability:
- Public ATS JSON APIs when the careers page is hosted on / links to one (Greenhouse, Lever, Ashby, SmartRecruiters, Recruitee, Workable).
- Schema.org
JobPostingJSON-LD embedded in the careers page (server-rendered, standardized). - Known-site adapters for notable companies that publish a custom public listings endpoint (e.g. Atlassian).
- ATS-token guessing — many companies host on a public board whose token derives from their name (e.g.
canva→ SmartRecruitersCanva,hubspot→ Greenhousehubspotjobs). The actor probes a small set of likely boards and keeps the one with the most roles. - Generic careers-page HTML — job-detail links as a last resort.
Notes & limitations
- Coverage is strongest for companies that publish jobs on a public ATS — which, thanks to token guessing and JSON-LD, includes many companies whose own careers site is a custom/JS app.
- Company-name inputs are resolved best-effort via free public search; supplying a domain or careers URL is more reliable.
- A custom JavaScript-only careers page with no public ATS board, JSON-LD, or adapter is reported as
no_jobs_found/partial(this actor is HTTP-only by design — no headless browser).