Google Images Scraper
Pricing
from $1.00 / 1,000 results
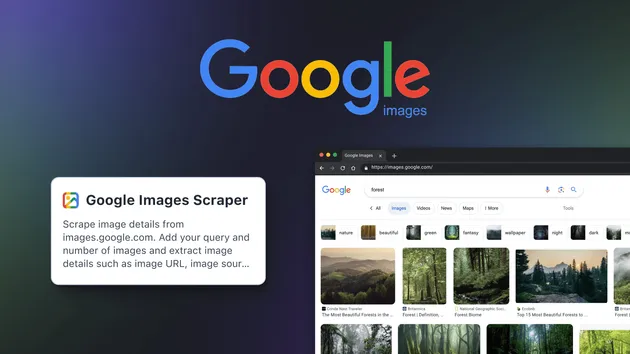
Google Images Scraper
Extract image data from Google Images search. Scrape image URLs, dimensions, thumbnails, page titles, origins, and content URLs for any search query.
Pricing
from $1.00 / 1,000 results
Rating
0.0
(0)
Developer
Crawler Bros
Maintained by CommunityActor stats
0
Bookmarked
90
Total users
15
Monthly active users
24 days ago
Last modified
Categories
Share
Scrape image data from Google Images search results at scale. Extract full-resolution image URLs, dimensions, thumbnails, page titles, source domains, and content page URLs for any search query.
Perfect for building image datasets, monitoring brand visuals, competitor research, content curation, and training data collection.
What data can you extract from Google Images?
For every image result, the scraper returns:
| Field | Type | Description |
|---|---|---|
query | string | The search query used |
imageUrl | string | Direct URL to the full-resolution image |
imageWidth | integer | Width of the full-resolution image in pixels |
imageHeight | integer | Height of the full-resolution image in pixels |
thumbnailUrl | string | URL of the Google-cached thumbnail |
thumbnailWidth | integer | Width of the thumbnail in pixels |
thumbnailHeight | integer | Height of the thumbnail in pixels |
title | string | Page title of the website containing the image |
origin | string | Domain of the website where the image is hosted |
contentUrl | string | URL of the web page containing the image |
How to use Google Images Scraper
- Add your search queries - Enter one or more image search terms (e.g., "sunset landscape", "product packaging design")
- Set the result limit - Choose how many images to extract per query (1 to 500)
- Run the scraper - Click Start and the scraper will collect all image data automatically
- Export your data - Download results as JSON, CSV, Excel, or connect via API
Input
| Field | Type | Description | Default |
|---|---|---|---|
queries | string[] | List of image search queries | required |
maxResultsPerQuery | integer | Maximum number of image results to extract per query | 100 |
Example Input
Output
Example Output
Output Schema
Use cases
- Image dataset building - Collect large sets of images for research, analysis, or machine learning training
- Brand monitoring - Track how your brand visuals appear across the web
- Competitor research - Analyze competitor product images, marketing materials, and visual strategies
- Content curation - Find high-quality images for blogs, presentations, and social media
- SEO & visual search analysis - Monitor which images rank for specific keywords
- E-commerce - Research product photography trends and competitor listings
Integrations
Connect Google Images Scraper with your existing tools and workflows:
- Webhooks - Get notified when a scrape finishes
- API access - Integrate results directly into your application
- Scheduled runs - Set up recurring scrapes to monitor image results over time
- Export to Google Sheets, Slack, Zapier, Make, and more
FAQ
How many images can I scrape per query?
You can extract up to 500 images per search query. The default is 100. For most queries, Google Images returns hundreds of results.
What image data is included?
Every result includes the full-resolution image URL with dimensions, a Google-cached thumbnail URL with dimensions, the page title and domain of the source website, and a link to the web page containing the image.
Can I search for images in different languages?
Yes. You can use search queries in any language, including non-Latin scripts like Japanese, Chinese, Korean, Arabic, and more.
Can I run multiple queries at once?
Yes. Pass an array of queries and the scraper will process them sequentially, returning results for each query in a single dataset.
How fast is it?
The scraper typically extracts 100 images per query in under 15 seconds. Larger result sets (200-500) take proportionally longer due to pagination.
What format can I export the data in?
Results can be exported as JSON, CSV, Excel, XML, or accessed via the Apify API. You can also connect to Google Sheets, Slack, Zapier, and other integrations.
Does it handle Google's anti-bot protection?
Yes. The scraper uses stealth browser techniques to avoid detection and works reliably without requiring proxies.